







简要介绍
构造抽象语法树是构造基于DFA的正则表达式引擎的第一步。目前在我实现的这个正则表达式的雏形中,正则表达式的运算符有3种,表示选择的|运算符,表示星号运算的*运算符,表示连接的运算符cat(在实际正则表达式中被省去)。
例如对于正则表达式a*b|c,在a*和b之间省略了连接运算符cat。其中|、cat运算符是双目运算符,*运算符是单目运算符。
下图来自编译原理一书:
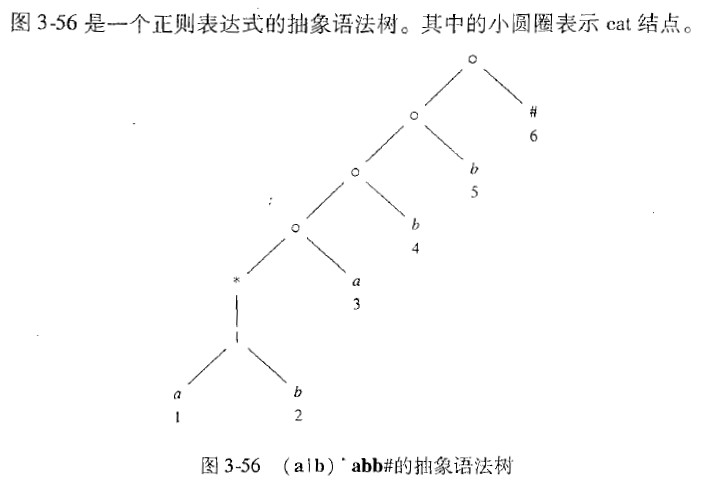
对(a|b)*abb构造语法树,需要注意的是,此图中在原正则表达式的末尾添加了一个#号表示接受状态。在我自己的代码中没有添加最后一个#号,而是用 eType_END 类型的词法单元表示正则表达式的末尾和DFA的接受状态。
构造正则表达式的抽象语法树的过程和构造算术表达式的抽象语法树的过程类似,都一样会存在运算符优先级和括号处理的问题。有差异的地方是正则表达式中存在单目运算符*,而普通的算术表达式中都是双目运算符。
构造正则表达式语法树的过程基于词法分析,这里的词法分析就比较简单了,因为一个字符就对应一个词法单元,需要注意的地方是:
1 在两个非运算符、右括号左括号对之间需要添加cat连接运算符。
2 在尾部需要加入一个 eType_END 类型的词法单元表示正则表达式的末尾和DFA的接受状态。
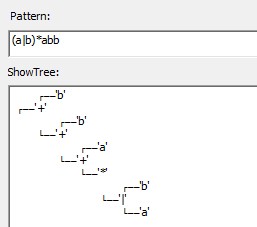
语法树展示
根据正则表达式得到的语法树如下所示:
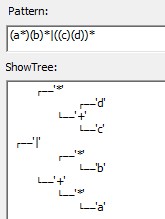
支持转义字符(右斜杠\)的模式串:
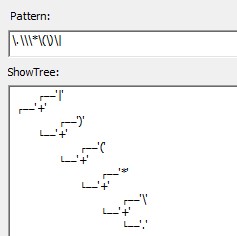
在我写的词法分析中支持通配符点号(.),支持转义字符(右斜杠\加特殊字符)。另外这个语法分析树的打印方式大家也可以从我的代码中找到实现方法^_^。
在以上各个语法树中,打印输出时屏蔽了尾部的eType_END节点。
构建语法树主要需要的对象和数据结构
构建语法树主要需要的对象和数据结构如下:
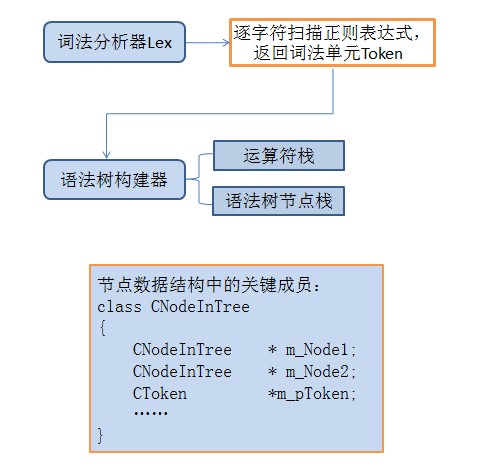
整个语法树的构建过程中需要一个词法分析器Lex,词法分析器从左到右逐个字符地扫描正则表达式,根据遇到的字符返回正确的Token给语法树构建器,对于不合法的正则表达式给出报错信息(例如转义字符\后面跟的不是特殊字符)。
语法树构建器拿到词法分析器返回的词法Token后,开始进行自下而上的建树过程,在不考虑括号的情况下,正确的正则表达式的第一个词法Token应该是一个非运算符,它被包装为语法树节点结构然后被压入语法树构建器的语法树节点栈中。
之后第二个词法Token可能是一个运算符也可能是一个非运算符,如果是非运算符,则需要添加一个表示连接的cat运算符到运算符栈中,并将得到的操作数Token包装为语法树节点压入语法树节点栈中。每次向运算符栈中压入新的运算符new之前,都需要查看当前运算符栈顶的运算符old,和new谁的优先级更高,如果old的优先级较高,则先处理old运算符(会用掉语法树节点栈中的节点,运算得到的节点再压回语法树节点栈),old被处理完后,old出栈,接下来的栈顶元素成为old,再次和new进行比较,重复这个过程,直到old的运算符优先级低于new,再将new运算符压栈。如果遇到了左括号,则先将左括号压入运算符栈中,在遇到右括号时需要将运算符栈中的节点从栈顶开始处理,直到处理到最靠近栈顶的左括号为止。
当正则表达式处理完后,最后再处理运算符栈中剩余的运算符。
正确的结果应该是运算符栈为空,语法树节点栈中有一个节点,这个节点就是整个语法树的根节点。
结合实例介绍构建语法树过程
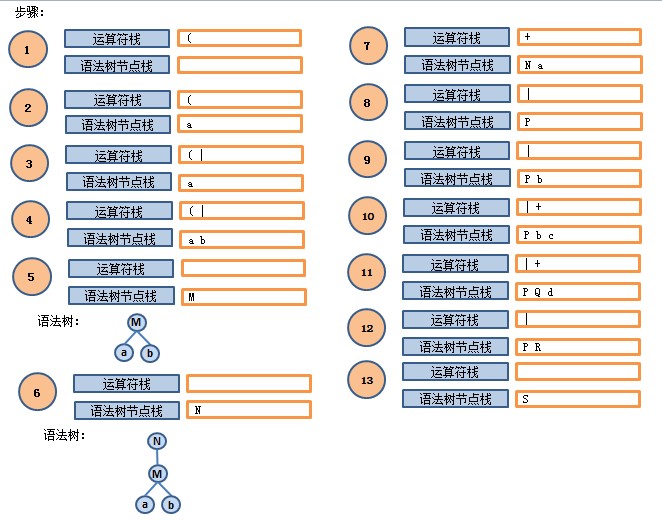
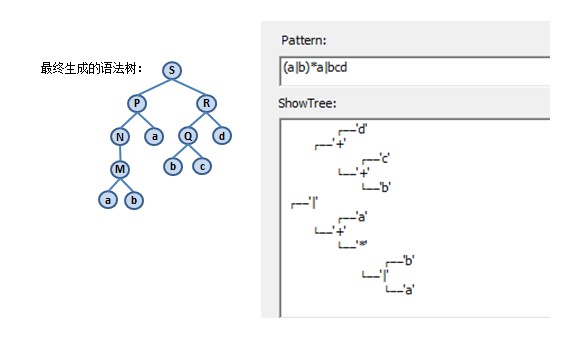
接下来举一个实例,对正则表达式(a|b)*a|bcd 构造语法树。过程如下:1 词法分析器从左向右扫描表达式,先得到左括号,将左括号包装成节点,压入运算符栈中;
2 词法分析器获得的下一个节点为字符a,压入语法树节点栈中;
3 词法分析器继续获取词法Token,得到运算符|,压入运算符栈中;
4 下一个字符是b,将b包装成节点压入语法树节点栈中;
5 继续获取字符,得到右括号,此时语法树构建器开始根据语法树节点栈和运算符栈进行运算合并已有节点,直到在语法树节点栈中遇到左括号为止。开始处理时语法树节点栈和运算符栈中内容如下:
运算符栈:(|
语法树节点栈:ab
运算符栈的栈顶运算符出栈,得到|运算符,这是一个双目运算符,所以从语法树节点栈中出栈2个节点b和a,|运算符和节点a节点b,得到新的节点(记为M),M再压入语法树节点栈,此时在运算符栈顶已经是左括号,将其出栈,节点合并结束。
两个栈的内容如下:
运算符栈:空
语法树节点栈:M
6 接下来是*号运算符,因为*号是优先级最高的运算符,所以可以直接处理,无需进行运算符优先级的比较,*号会消耗语法树节点栈中一个节点(也就是M),*号运算符和M节点运算得到新的节点N,重新压入节点栈中。
7 接下来词法分析器得到字符a,但是在节点N和字符a之间需要插入一个连接cat运算符,我们把cat运算符用‘+’来表示,‘+’压入运算符栈,a压入节点栈。
8 词法分析器得到的下一个Token是运算符|,在向运算符栈中压入‘|’运算符之前,我们需要检查运算符栈的栈顶运算符和当前想要压栈的运算符的优先级,如果栈顶运算符的优先级大于等于将要压栈的运算符,则需要先处理栈顶的运算符(这里是一个循环的过程,也就是说处理完栈顶的运算符之后,还要继续比较栈顶的运算符和将要压栈的运算符之间的优先级,以决定接下来该执行什么步骤)。在这里栈顶的运算符‘+’的优先级比运算符‘|’的优先级高,所以先进行栈顶运算符的运算,‘+’连接运算符将节点N和a组成为新的节点(记为P)并重新压入节点栈中。然后运算符栈为空,此时把前面所说的“将要压入运算符栈的‘|’运算符”压入运算符栈。
9 下一个字符是b,此时不需要插入连接运算符,只需要将字符b包装为节点压入节点栈。
10 下一个字符是c,此时同样需要插入一个连接运算符,在向运算符栈中压入‘+’运算符之前,我们需要检查运算符栈的栈顶运算符和当前想要压栈的运算符的优先级。在这里‘+’的优先级高于栈顶的‘|’,所以直接将运算符‘+’压入运算符栈中,并将字符c包装为节点压入节点栈。
11 下一个字符是d,此时同样需要插入一个连接运算符,在向运算符栈中压入‘+’运算符之前,我们需要检查运算符栈的栈顶运算符和当前想要压栈的运算符的优先级。在这里两个运算符相同,所以先处理运算符栈栈顶的运算符,‘+’运算符和节点栈中的b,c字符组成新的节点Q压入节点栈,然后运算符栈顶的运算符为‘|’,‘+’的优先级高于‘|’,所以不在处理运算符栈的栈顶运算符。将‘+’压入运算符栈,将字符d包装为节点压入节点栈。
12 此时词法分析器报告已经到达正则表达式的结尾,所以开始处理运算符栈中剩余的运算符,从栈顶开始依次处理,首先遇到的是‘+’连接符,从节点栈中取出节点Q和字符d生成新的节点R压回节点栈。
13 继续处理运算符栈,栈顶运算符为‘|’,从节点栈中取出节点P和节点R生成新的节点S压回节点栈。
14 此时运算符栈清空,节点栈中只有一个节点S,S就是最终生成的语法树的根节点。(至此大功告成、功德圆满^_^呼呼)
可以看出,我们遇到一个非运算符时,需要检查是否需要添加cat连接符,在向运算符栈中添加一个新的运算符时,需要比较栈顶运算符和将要添加的运算符之间的优先级,以决定是否先进行栈顶运算符的运算。
我们将上面每一个步骤中的运算符栈和节点栈以图形的方式直观地展现出来:















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









