






接下来,我们将超越简单的示例,详细介绍Spark Streaming的基础知识。
链接
与Spark类似,Spark Streaming可以通过Maven Central获得。要编写自己的Spark Streaming程序,必须将以下依赖项添加到Maven项目中。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.0</version>
</dependency>要从Kafka,Flume和Kinesis等源中提取Spark Streaming核心API中不存在的数据,我们必须将相应的artifact spark-streaming-xyz_2.11 添加到依赖中。例如,一些常见的如下:
| Source | Artifact |
| Kafka | spark-streaming-kafka-0-10_2.11 |
| Flume | spark-streaming-flume_2.11 |
| Kinesis | spark-streaming-kinesis-asl_2.11[Amazon Software License] |
初始化StreamingContext
要初始化Spark Streaming程序,必须创建一个StreamingContext对象,它是所有Spark Streaming功能的主要入口点。
一个StreamingContext对象可以被SparkConf对象创建,如下:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))该appName参数时应用程序在集群UI上显示的名称。master是Spark,Mesos或YARN集群URL,或在本地local模式下运行的特殊“local[*]”字符串。实际上,当在集群上运行时,我们不希望master在程序中进行硬编码,而是启动应用程序spark-submit并在那里接受它。但是,对于本地测试和单元测试,我们可以传递“local[*]”以在进程中运行Spark Streaming。请注意,这会在内部创建一个JavaSparkContext(所有Spark功能的起点),可以将其作为ssc.sparkContext。
必须根据应用程序的延迟要求和可用的集群资源设置批处理间隔。
一个JavaStreamingContext还可以通过JavaSparkContext大对象创建。
import org.apache.spark.streaming.api.java.*;
JavaSparkContext sc = ... //existing JavaSparkContext
JavaStreamingContext ssc = new JavaStreamingContext(sc, Durations.seconds(1));定义上下文后,我们必须执行以下操作。
- 通过创建输入DStream来定义输入源。
- 通过将转换和输出操作应用于DStream来定义流式计算。
- 开始接收数据并使用它进行处理streamingContext.start()。
- 等待处理停止(手动或由于任何错误)使用streamingContext.awaitTermination()。
- 可以使用手动停止处理streamingContext.stop()。
要记住的要点:
- 一旦启动了上下文,就不能设置或添加新的流式计算。
- 上下文停止后,无法重新启动。
- 在JVM中只能同时激活一个StreamingContext。
- StreamingContext上的stop()也会停止SparkContext。要仅停止StreamingContext,需要将名为stopSparkContext的stop()的可选参数设置为false。
- 只要创建下一个StreamingContext之前停止前一个StreamingContext(不停止SparkContext),就可以重复使用SparkContext创建多个StreamingContexts。
离散流(DStreams)
Discretized Stream或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变分布式数据集的抽象。DStream中的每个RDD都包含来自特定时间间隔的数据。
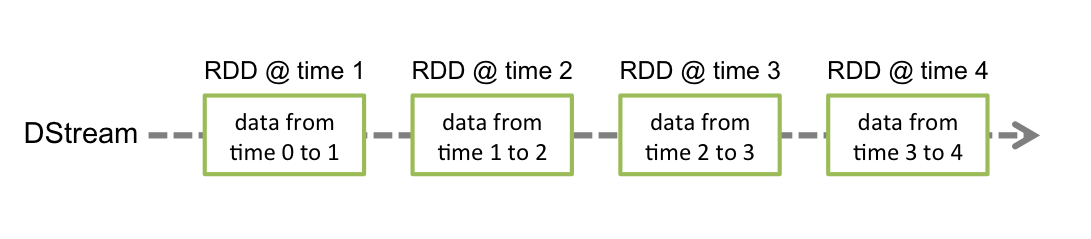
应用于DStream的任何操作都转换为底层RDD上的操作。例如,在先前将行流转换为单词的示例中,flatMap操作应用于lines DStream中的每个RDD以生成DStream的wordsRDD。如下图:
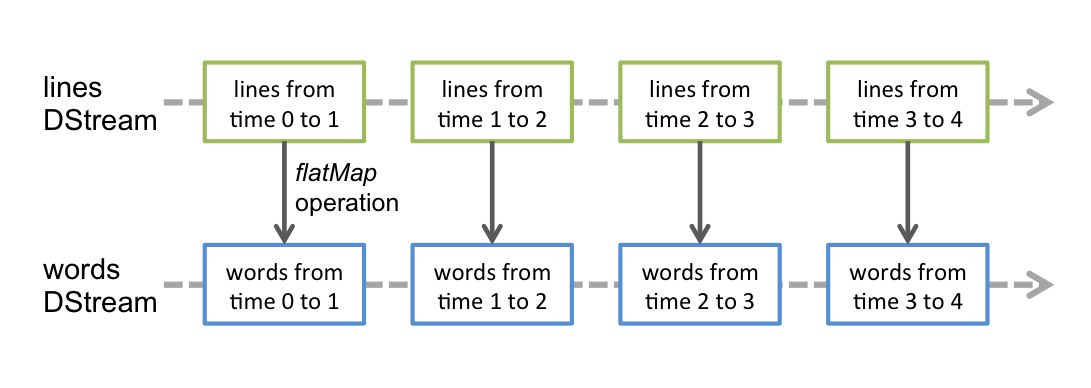
这些底层RDD转换由Spark引擎计算。DStream操作隐藏了大部分细节,并为开发人员提供了更高级别的API以方便使用。
输入DSreams和Receivers
输入DStream是表示从流源接收的输入数据流的DStream。在上示例中,lines输入DStream是表示从netcat服务器接收的数据流。每个输入DStream(文件流除外)都与Receiver对象相关联,该对象从源接收数据并将其存储在Spark的内存中进行处理。
Spark Streaming提供两类内置流媒体源。
- 基本来源:StreamingContext API中直接提供的源。示例:文件系统和socket连接。
- 高级资源:Kafka,Flume,Kinesis等资源可通过额外的实用程序类获得。这些需要连接额外的依赖关系。
注意,如果要在应用程序中并行接收多个数据流,可以创建多个输入DStream。这将创建多个接收器,这些接收器将同时接收多个数据流。但请注意,Spark worker / executor是一个长期运行的任务,因此它占用了分配给Spark Streaming应用程序的其中一个核心。因此,重要的是要记住,Spark Streaming应用程序需要分配足够的内核来处理接收的数据,以及运行接收器。
要记住的要点
- 在本地运行Spark Streaming程序时,请勿使用“local”或“local[1]”作为主URL。这两种方法都意味着只有一个线程将用于本地运行任务。如果我们正在使用基于接收器的输入DStream(例如Kafka,Socket,Flume等),那么将使用单个线程来运行接收器,而不留下用于处理接收数据的线程。因此,在本地运行时,始终使用“local[n]”作为主URL,其中n>要运行的接收器数量。
- 将逻辑扩展到在集群上运行时,分配给Spark Streaming应用程序的核心数必须大于接收器数。否则系统将接收数据,但无法处理数据。
基本来源
我们已经在示例中看了通过TCP Socket连接接收的文本数据创建DStream的示例ssc.socketTextStream(...)。除了Socket之外,StreamingContext API还提供了从文件创建DStream作为输入源的方法。
文件流
对于从于HDFS API兼容的任何文件系统(即HDFS,S3,NFS等)上的文件读取数据,可以创建DStream作为viaStreamingContext.fileStream[keyClass, valueClass, InputFormatClass]。
文件流不需要运行接收器,因此不需要为接收文件数据分配任何内核。
对于简单的文本文件,最简单的方法是StreamingContext.textFileStream(dataDirectory)。
streamingContext.fileStream<KeyClass, ValueClass, InputFormatClass>(dataDirectory);对于文本文件
streamingContext.textFileStream(dataDirectory);
如何监控目录
Spark Streaming将监视目录dataDirectory并处理在该目录中创建的任何文件。
- 可以监视一个简单的目录,例如“hdfs://namenode:8040/logs/”。直接在这种路径下的所有文件将在发现时进行处理。
- 一个POSIX glob模式可以被提供,例如“hdfs://namenode:8040/logs/2017/*”。这里,DStream将包含与模式匹配的目录中的所有文件。那就是:它是目录的模式,而不是目录中的文件。
- 所有文件必须采用相同的数据格式。
- 根据文件的修改时间而不是创建时间,文件被视为时间段的一部分。
- 一旦处理完毕后,对当前窗口中文件的更改不会导致重新读取文件。那就是:忽略更新。
- 目录下的文件越多,扫描更改所需要的时间越长:即使没有修改过任何文件。
- 如果使用通配符来标识目录,例如“hdfs://namenode:8040/logs/2016-*”,重命名整个目录以匹配路径,则会将该目录添加到受监视目录列表中。只有修改时间在当前窗口内的目录中的文件才会包含在流中。
- 调用FileSystem.setTimes()修复时间戳是一种在稍后的窗口中拾取文件的方法,即使其内容未更改。
使用对象存储作为数据源
“完整”文件系统(如HDFS)会在创建输出流后立即在其文件上设置修改时间。打开文件时,即使在数据完全写入之前,它也可能包含在DStream-after将忽略同一窗口中文件大的更新。即:可能会遗漏更改,并从流中省略数据。
要确保在窗口中选择更改,请将文件写入不受监视的目录,然后在关闭输出流后立即将其重命名为目标目录。如果重命名的文件在其创建窗口期间出现在扫描的目标目录中,则将拾取新数据。
相比之下,Amazon S3和Azure Storage等对象存储通常具有较慢的重命名操作,因为实际上是复制了数据。此外,重命名的对象可能将rename()操作的时间作为其修改时间,因此可能不被视为原始创建时间所暗示的窗口的一部分。
需要对目标对象存储进行仔细测试,以验证存储的时间戳行为是否与Spark Streaming所期望的一致。可能是直接写入目标目录是通过所选对象存储流传输数据的适当策略。
基于自定义接收器的流
可以使用通过自定义接收器接收的数据流创建DStream。
RDD作为流的队列
为了测试带有测试数据的Spark Streaming应用程序,还可以使用基于RDD队列streamingContext.queueStream(queueOfRDDs)创建DStream。推入队列的每个RDD将被视为DStream中的一批数据,并像流一样处理。
高级资源
从Spark2.3.0开始,在这些源代码中,Kafka,Kinesis和Flume在Python API中可用,咱不关注。此类源需要与外部非Spark库连接,其中一些库具有复杂的依赖性(例如,Kafka和Flume)。因此,为了最大限度地减少与依赖项版本冲突相关的问题,从这些源创建DStream的功能已移至可在必要时显示连接的单独库。
请注意,Spark shell中不提供这些高级资源,因此无法在shell中测试基于这些高级资源的应用程序。如果我们真的想在Spark shell中使用它们,则必须下载相应的Maven依赖,并将其添加到类路径中。
其中一些高级资源的版本兼容如下:
- Kafka:Spark Streaming 2.3.0与Kafka broker版本 0.8.2.1或更高版本兼容
- Flume:Spark Streaming 2.3.0与Flume 1.6.0兼容。
- Kinesis:Spark Streaming 2.3.0与Kinesis Client Library 1.2.1兼容。
自定义来源
输入DStream也可以从自定义数据源创建。我们所要做的就是实现一个用户自定义的接收器,它可以从自定义源接收数据并将其推送到Spark。
接收器可靠性
根据其可靠性,可以有两种数据源。资源(如Kafka和Flume)允许传输数据得到确认。如果从这些可靠来源接收数据的系统正确地确认接收到地数据,则可以确保不会因任何类型地故障而丢失数据。这导致两种接收器:
- 可靠的接收器:可靠的接收器在接收到数据并将其存储在带复制的Spark中时,正确地将确认发送到可靠地源。
- 不可靠地接收器:一个不可靠地接收器并没有发送确认地资源等。这可以用于不支持确认地源,甚至可以用于不需要或需要进入确认复杂性的可靠源。














 1546
1546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









