







从数据仓库到数据湖
仓库和湖泊
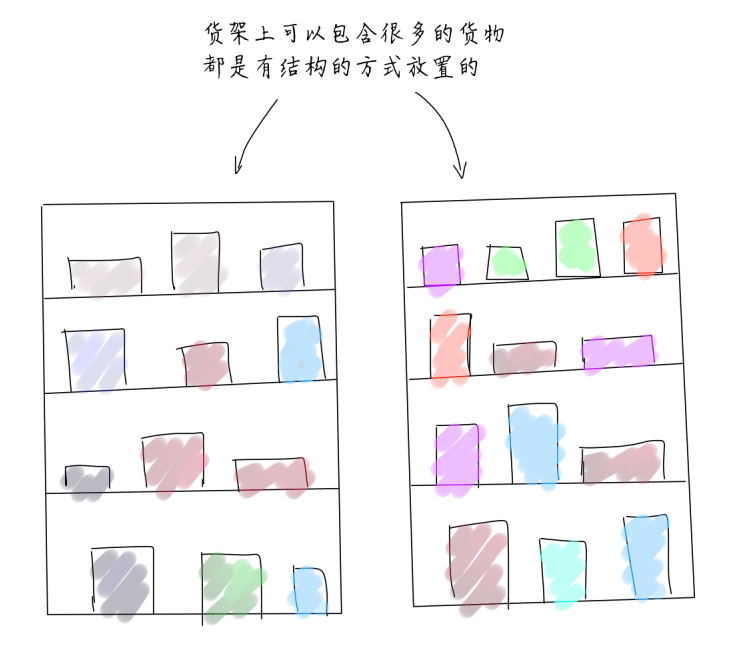
仓库是人为提前建造好的,有货架,还有过道,并且还可以进一步为放置到货架的物品指定位置。
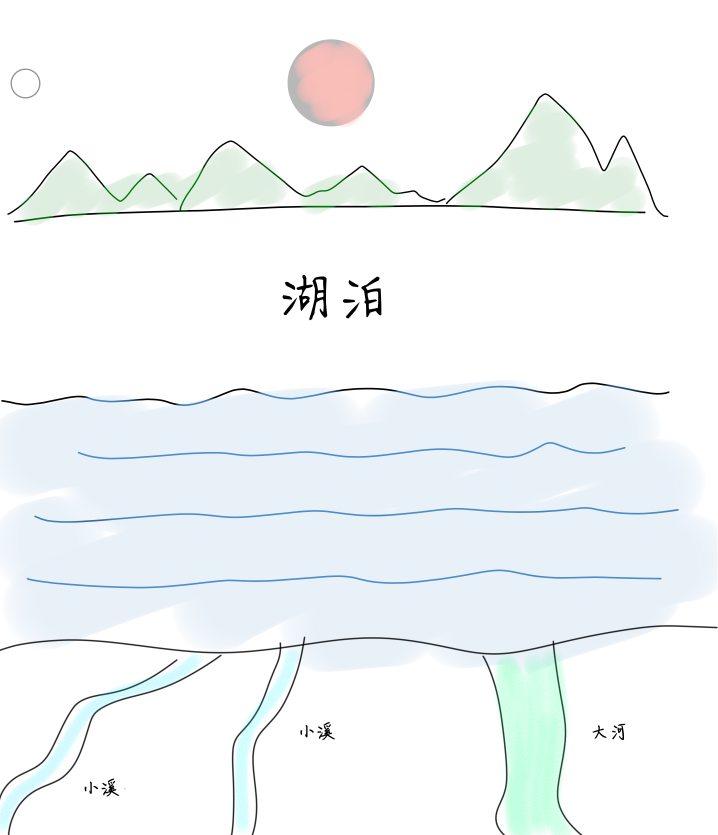
而湖泊是液态的,是不断变化的、没有固定形态的,基本上是没有结构的,湖泊可以是由河流 、小溪和其他未被任何处理的水源维持。湖泊是不需要预先指定结构的。
什么是数据湖?
数据湖(Data Lake)和数据库、数据仓库一样,都是数据存储的设计模式。数据库和数据仓库会以关系型的方式来设计存储、处理数据。但数据湖的设计理念是相反的,数据仓库是为了保障数据的质量、数据的一致性、数据的重用性等对数据进行结构化处理。
数据湖是一个数据存储库,可以使用数据湖来存储大量的原始数据。现在企业的数据仓库都会通过分层的方式将数据存储在文件夹、文件中,而数据湖使用的是平面架构来存储数据。我们需要做的只是给每个数据元素分配一个唯一的标识符,并通过元数据标签来进行标注。当企业中出现业务问题时,可以从数据湖中查询数据,然后分析业务对应的那一小部分数据集来解决业务问题。
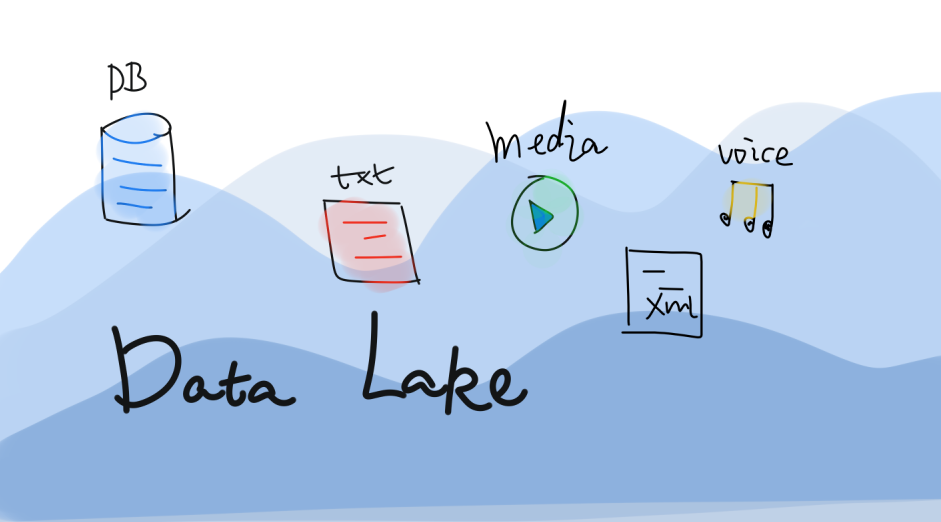
了解过Hadoop的同学知道,基于Hadoop可以存储任意形式的数据。所以,很多时候数据湖会和Hadoop关联到一起。例如:把数据加载Hadoop中,然后将数据分析、和数据挖掘的工具基于Hadoop进行处理。数据湖越来越多的用于描述任何的大型数据池,数据都是以原始数据方式存储,知道需要查询应用数据的时候才会开始分析数据需求和应用架构。
数据湖是描述数据存储策略的方式,并不与具体的某个技术框架关联。数据库、数据仓库也一样。它们都是数据的管理策略。
数据湖是专注于原始数据保真以及低成本长期存储的存储设计模式,它相当于是对数据仓库的补充。数据湖是用于长期存储数据容器的集合,通过数据湖可以大规模的捕获、加工、探索任何形式的原始数据。通过使用一些低成本的技术,可以让下游设施可以更好地利用,下游设施包括像数据集市、数据仓库或者是机器学习模型。
数据湖的优点
-
提供不限数据类型的存储
-
开发人员和数据科学家可以快速动态建立数据模型、构建应用、查询数据,非常灵活。
-
因为数据湖没有固定的结构,所以更易于访问
-
长期存储数据的成本低廉,数据湖可以安装在低成本的硬件在,例如:
在一般的X86机器上部署Hadoop
-
因为数据湖是非常灵活的,它允许使用多种不同的处理、分析方式来让数据发挥价值,例如:
数据分析、实时分析、机器学习以及SQL查询都可以。
数据湖 VS 数据仓库
数据湖和数据仓库是用于存储大数据的两种不同策略,最大区别是:数据仓库是提前设计好模式(schema)的,因为数据仓库中存储的都是结构化数据。而在数据湖中,不一定是这样的。数据湖中可以存储结构化和非结构化的数据,是无法预先定义好结构的。
我们来进一步进行对比:
数据的存储位置不同
数据仓库因为是要有结构的,在企业中很多都是基于关系型模型。而数据湖通常位于分布式存储例如Hadoop或者类似的大数据存储中。
数据源不同
数据仓库的数据来源很多时候来自于OLTP应用的结构化数据库中提取的,用于支持内部的业务部门(例如:销售、市场、运营等部门)进行业务分析。而数据湖的数据来源可以是结构化的、也可以是非结构化的,例如:业务系统数据库、 IOT设备、社交媒体、移动APP等。
用户不同
数据仓库主要是业务系统的大量业务数据进行统计分析,所以会应用数据分析的部门是数据仓库的主要用户,例如:销售部、市场部、运营部、总裁办等等。而当需要一个大型的存储,而当前没有明确的数据应用用户或者是目标,将来想要使用这些数据的人可以在使用时开始设计架构,此时,数据湖更适合。
但数据湖中的数据都是原始数据,是未经整理的,这对于普通的用户几乎是不可用的。数据湖更适合数据科学家,因为数据科学家可以应用模型、技术发觉数据中的价值,去解决企业中的业务问题。
数据质量
数据仓库是非常重数据质量的,大家现在经常听说的数据中台,其中有一大块是数据质量管理、数据资产管理等。数据仓库中的数据都是经过处理的。而数据湖中的数据可靠性是较差的,这些数据可能是任意状态、形态的数据。
数据模式
数据仓库在数据写入之前就要定义好模式(schema),例如:我们会先建立模型、建立表结构,然后导入数据。我们可以把它称之为write-schema。而数据湖中的数据是没有模式的,直到有用户要访问数据、使用数据才会建立schema。我们可以把它称之为read-schema。
敏捷扩展性
数据仓库的模式一旦建立,要重新调整模式,往往代价很大,牵一发而动全身,所有相关的ETL程序可能都需要调整。而数据湖是非常灵活的,可以根据需要重新配置结构或者模式。
基于上述内容,我们可以了解到,数据湖和数据仓库的应用点是不一样的。他们是两种相对独立的数据设计模式。在一些企业中,可能会既有数据湖、又有数据仓库。数据湖并不是要替代数据仓库,而是对企业的数据管理模式进行补充。
数据仓库应用
数据仓库一般用于做批处理报告、BI、可视化。而数据湖主要用于机器学习、预测分析、数据探索和分析。
数据湖应用
数据湖是用于数据存储的设计模式,但最终数据肯定是需要一种介质存储下来的。我们可以自己来选择数据湖的物理存储引擎。例如:使用Hadoop作为数据湖的物理存储引擎、或者使用AWS的S3作为存储引擎等。
AWS的S3就是Simple Storage Service的缩写,是亚马逊云服务(AWS)提供的一种分布式对象存储服务。它允许用户在云中存储和检索任意数量和类型的数据,而无需关心底层的硬件或基础设施细节。S3的设计很简单,它提供了一个高度可扩展的存储基础设施,支持从任何地点访问和存储数据,并且具有高可靠性和安全性。
S3的主要特点包括:
1. 可靠性高:S3使用多个数据中心存储数据,保证数据可用性和容错性。
2. 可扩展性强:用户可以非常方便地在S3中上传和管理任意数量和类型的数据,而无需考虑数据量的大小或类型的复杂性。
3. 安全性高:S3支持加密、权限控制、访问日志等多种安全措施,保证数据的安全性和隐私性。
4. 成本低廉:S3采用按用量计费的方式,用户只需要为实际使用的存储空间和数据传输费用付费,无需支付额外的硬件或服务器维护费用。
S3广泛应用于各种场景,如备份恢复、数据归档、网站内容分发、大数据存储等。
但架构数据湖时,需要注意几点原则,这几点原则也将和其他数据存储方法区别开来。
-
可以加载各种源系统中的数据,并存储。
任意类型的数据都可以存储。
-
数据是以原始状态保存在数据湖中的,是几乎不需要做任何转换的。
-
数据可以根据应用、分析的要求,进行转换成适合分析的模式
构建数据湖时,为了方便数据的管理。我们可以建立一些管理办法,例如:
-
将数据进行合理分类,例如:
按照数据类型分类、按照业务内容分类、按照应用场景分类或者按照可能的用户来分类。
-
为了方便数据湖的数据存取,要提前定义好命名规则和固定的文件目录结构。
-
如果出现数据质量问题也可以解决掉。
-
建立数据访问标准,可以追踪到哪些用户正在访问数据。
-
让数据目录可以被检索到。
-
提供一些加密、监控、授权、警报等功能。
不要让数据湖变成一潭死水
如果数据湖没有任何管理办法,不进行任何的治理,那么所有的数据将会是不可追溯的,再一大堆的数据,但杂乱不堪。数据湖将不再是数据湖,变成了一潭死水,或者泥潭,白白浪费大量有价值的数据。如果数据无人维护管理,数据湖最终变成了数据坟墓。这就尴尬了。所以,一旦建设了数据湖,一定要配有管理人员。对数据湖的治理负责。
除了具备基本的存储、敏捷可扩展特性外,一个管理良好的数据湖还应该具备以下特征:
-
提供方便进行访问、操作的API接口,应该Data Lake的应用场景很多,很灵活,所以应该提供方便提数的API接口
-
具备有访问控制机制。
可以方便数据的owner控制数据湖中数据的访问权限,并支持一些加密、网络安全等功能。
-
具备搜索和分类功能。
如果没法方便地进行数据湖数据的组织,以及快速检索数据,数据湖无法最大化地发挥作用。
-
数据湖能够提供方便进行处理和分析层,数据分析师、数据科学家、机器学习算法工程师能够集中访问。
数据湖还应该提供统一、易用的访问方式。
















 3942
3942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











