






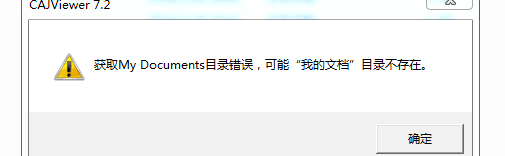
打开安装好的程序会出现下面的错误
解决《获取My Document目录错误,可能”我的文档“目录不存在》
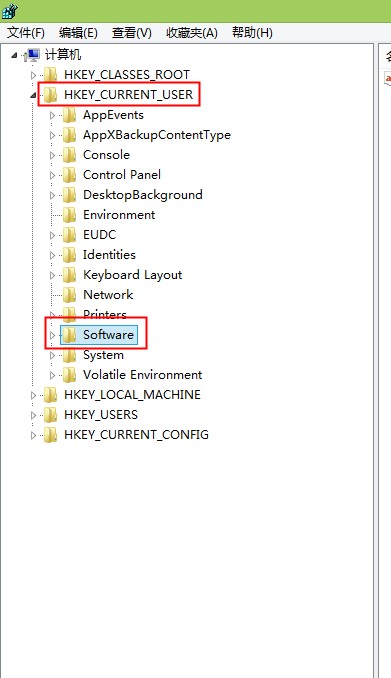
方法:开始—运行—搜索regedit.exe打开注册表
依次打开注册表以下目录:
开始……运行……搜索regedit.exe,打开regedit.exe
依次打开以下目录:
HKEY_CURRENT_USER/SOFTWARE/Microsoft/Windows/Currentversion/Explorer/User Shell Floders
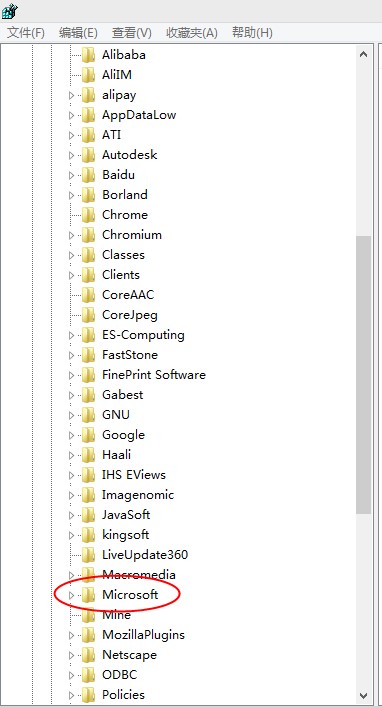
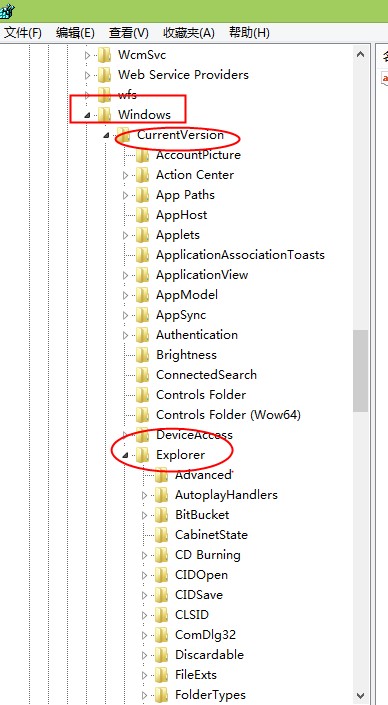
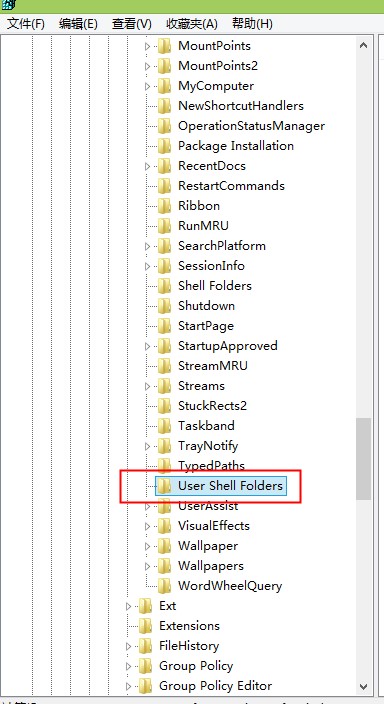
点击User Shell Floders出现下面的页面,找到personal双击打开
将地址栏
C:\Document改为改成%USERPROFILE%\Document
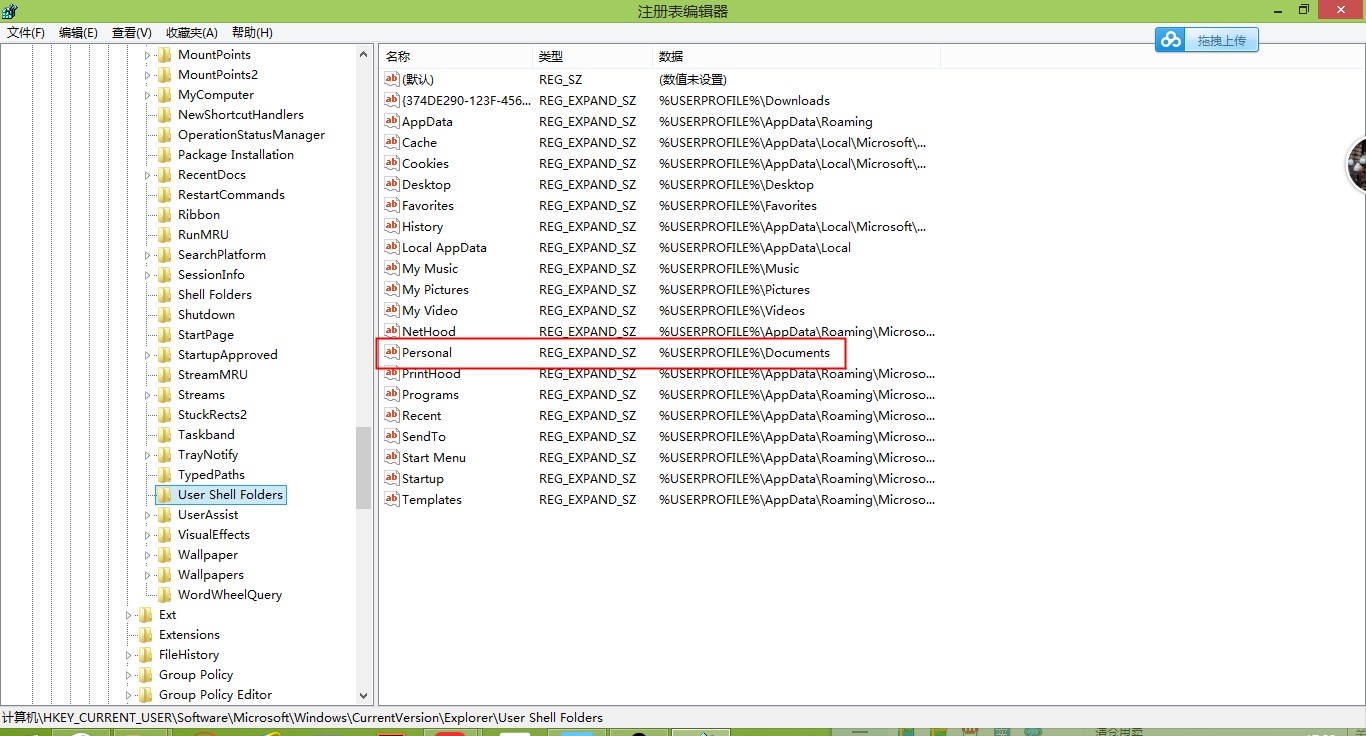
这样就可以打开安装的程序了
哈哈
不用谢















 8694
8694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









