









大纲
-
开源大语言模型
-
大语言模型管理
-
私有大语言模型服务部署方案
开源大语言模型
担心安全与隐私?可私有部署的开源大模型
-
商业大模型,不支持私有部署
-
ChatGPT
-
Claude
-
Google Gemini
-
百度问心一言
-
-
开源大模型,支持私有部署
-
Mistral
-
Meta Llama
-
ChatGLM
-
阿里通义千问
-
常用开源大模型列表
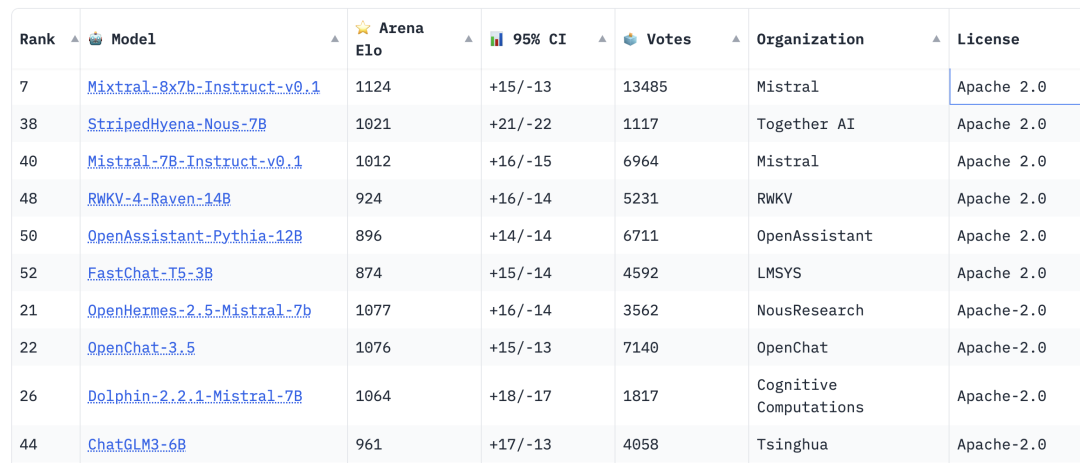
开源大模型分支
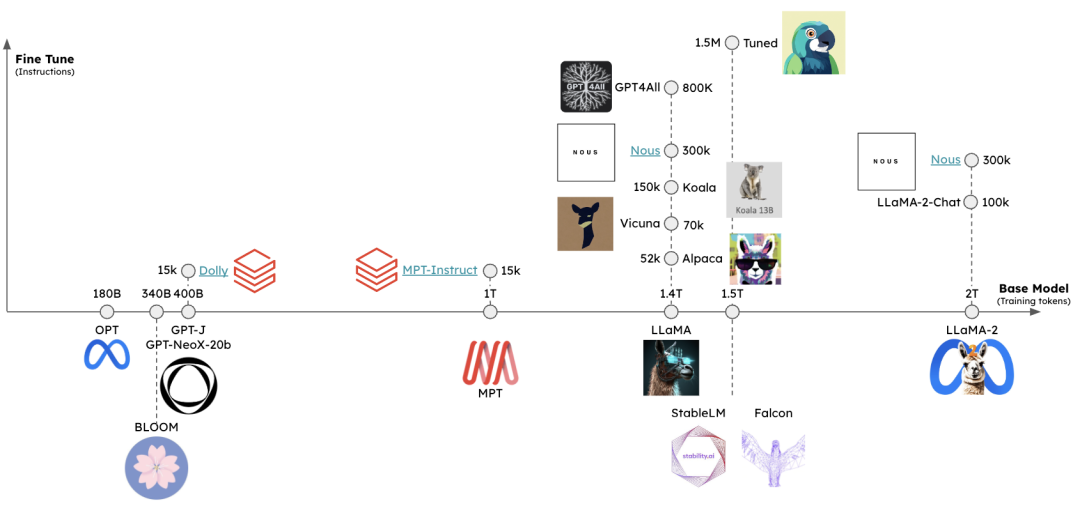
大语言模型管理
大语言模型管理工具
-
HuggingFace 全面的大语言模型管理平台
-
Ollama 在本地管理大语言模型,下载速度超快
-
llama.cpp 在本地和云端的各种硬件上以最少的设置和最先进的性能实现 LLM 推理
-
GPT4All 一个免费使用、本地运行、具有隐私意识的聊天机器人。无需 GPU 或互联网
Ollama 速度最快的大语言模型管理工具


Ollama 的命令
ollama pull llama2ollama listollama run llama2 "Summarize this file: $(cat README.md)"ollama servecurl http://localhost:11434/api/generate -d '{"model": "llama2","prompt":"Why is the sky blue?"}'curl http://localhost:11434/api/chat -d '{"model": "mistral","messages": [{ "role": "user", "content": "why is the sky blue?" }]}'
大语言模型的前端
大语言模型的应用前端
-
开源平台 ollama-chatbot、PrivateGPT、gradio
-
开源服务 hugging face TGI、langchain-serve
-
开源框架 langchain llama-index
ollama chatbot
docker run -p 3000:3000 ghcr.io/ivanfioravanti/chatbot-ollama:main## http://localhost:3000
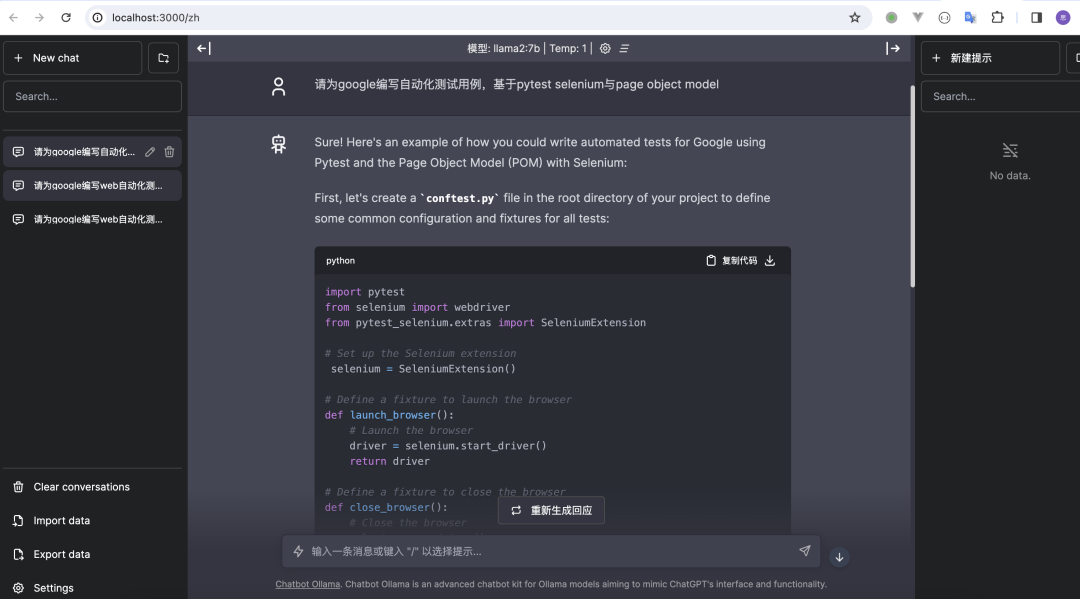
ollama chatbot
PrivateGPT
PrivateGPT 提供了一个 API,其中包含构建私有的、上下文感知的 AI 应用程序所需的所有构建块。该 API 遵循并扩展了 OpenAI API 标准,支持普通响应和流响应。这意味着,如果您可以在您的工具之一中使用 OpenAI API,则可以使用您自己的 PrivateGPT API,无需更改代码,并且如果您在本地模式下运行 privateGPT,则免费。
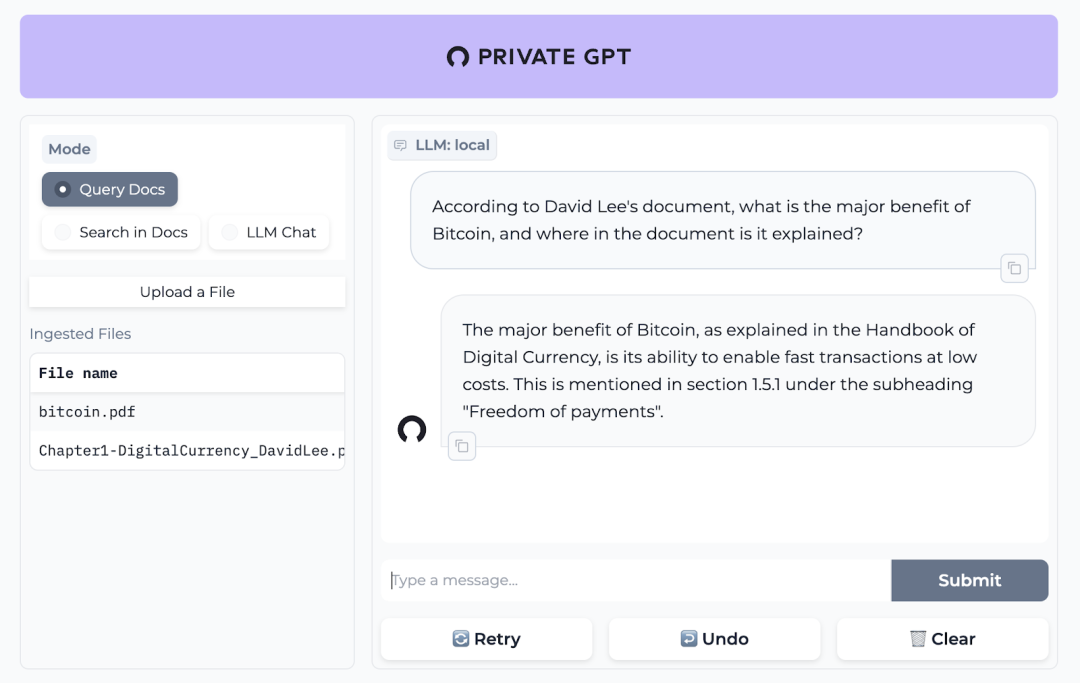
PrivateGPT 架构
-
FastAPI
-
LLamaIndex
-
支持本地 LLM,比如 ChatGLM llama Mistral
-
支持远程 LLM,比如 OpenAI Claud
-
支持嵌入 embeddings,比如 ollama embeddings-huggingface
-
支持向量存储,比如 Qdrant, ChromaDB and Postgres
PrivateGPT 环境准备
git clone https://github.com/imartinez/privateGPTcd privateGPT#不支持3.11之前的版本python3.11 -m venv .venvsource .venv/bin/activatepip install --upgrade pip poetry#虽然官网只说了要安装少部分的依赖,但是那些依赖管理不是那么完善,容易有遗漏#所以我们的策略就是全都要。poetry install --extras "ui llms-llama-cpp llms-openai llms-openai-like llms-ollama llms-sagemaker llms-azopenai embeddings-ollama embeddings-huggingface embeddings-openai embeddings-sagemaker embeddings-azopenai vector-stores-qdrant vector-stores-chroma vector-stores-postgres storage-nodestore-postgres"#或者用这个安装脚本#poetry install --extras "$(sed -n '/tool.poetry.extras/,/^$/p' pyproject.toml | awk -F= 'NR>1{print $1}' | xargs)"
ollama 部署方式
ollama pull mistralollama pull nomic-embed-textollama serve#官方这个依赖不够,还需要额外安装torch,所以尽量采用上面提到的全部安装的策略poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"PGPT_PROFILES=ollama poetry run python -m private_gpt
setting-ollama.yaml
server:env_name: ${APP_ENV:ollama}llm:mode: ollamamax_new_tokens: 512context_window: 3900temperature: 0.1 #The temperature of the model. Increasing the temperature will make the model answer more creatively. A value of 0.1 would be more factual. (Default: 0.1)embedding:mode: ollamaollama:llm_model: mistralembedding_model: nomic-embed-textapi_base: http://localhost:11434tfs_z: 1.0 ## Tail free sampling is used to reduce the impact of less probable tokens from the output. A higher value (e.g., 2.0) will reduce the impact more, while a value of 1.0 disables this setting.top_k: 40 ## Reduces the probability of generating nonsense. A higher value (e.g. 100) will give more diverse answers, while a lower value (e.g. 10) will be more conservative. (Default: 40)top_p: 0.9 ## Works together with top-k. A higher value (e.g., 0.95) will lead to more diverse text, while a lower value (e.g., 0.5) will generate more focused and conservative text. (Default: 0.9)repeat_last_n: 64 ## Sets how far back for the model to look back to prevent repetition. (Default: 64, 0 = disabled, -1 = num_ctx)repeat_penalty: 1.2 ## Sets how strongly to penalize repetitions. A higher value (e.g., 1.5) will penalize repetitions more strongly, while a lower value (e.g., 0.9) will be more lenient. (Default: 1.1)vectorstore:database: qdrantqdrant:path: local_data/private_gpt/qdrant
启动
PGPT_PROFILES=ollama poetry run python -m private_gptpoetry run python -m private_gpt02:36:06.928 [INFO ] private_gpt.settings.settings_loader - Starting application with profiles=['default', 'ollama']02:36:46.567 [INFO ] private_gpt.components.llm.llm_component - Initializing the LLM in mode=ollama02:36:47.405 [INFO ] private_gpt.components.embedding.embedding_component - Initializing the embedding model in mode=ollama02:36:47.414 [INFO ] llama_index.core.indices.loading - Loading all indices.02:36:47.571 [INFO ] private_gpt.ui.ui - Mounting the gradio UI, at path=/02:36:47.620 [INFO ] uvicorn.error - Started server process [72677]02:36:47.620 [INFO ] uvicorn.error - Waiting for application startup.02:36:47.620 [INFO ] uvicorn.error - Application startup complete.02:36:47.620 [INFO ] uvicorn.error - Uvicorn running on http://0.0.0.0:8001 (Press CTRL+C to quit)
PrivateGPT UI
local 部署模式
#todo: 需要安装llama-cpp,每个平台的安装方式都不同,参考官方文档poetry run python scripts/setupPGPT_PROFILES=local poetry run python -m private_gpt
setting-local.yaml
server:env_name: ${APP_ENV:local}llm:mode: llamacpp## Should be matching the selected modelmax_new_tokens: 512context_window: 3900tokenizer: mistralai/Mistral-7B-Instruct-v0.2llamacpp:prompt_style: "mistral"llm_hf_repo_id: TheBloke/Mistral-7B-Instruct-v0.2-GGUFllm_hf_model_file: mistral-7b-instruct-v0.2.Q4_K_M.ggufembedding:mode: huggingfacehuggingface:embedding_hf_model_name: BAAI/bge-small-en-v1.5vectorstore:database: qdrantqdrant:path: local_data/private_gpt/qdrant
非私有 OpenAI-powered 部署
poetry install --extras "ui llms-openai embeddings-openai vector-stores-qdrant"PGPT_PROFILES=openai poetry run python -m private_gpt
setting-openai.yaml
server:env_name: ${APP_ENV:openai}llm:mode: openaiembedding:mode: openaiopenai:api_key: ${OPENAI_API_KEY:}model: gpt-3.5-turbo
openai 风格的 API 调用
-
The API is built using FastAPI and follows OpenAI's API scheme.
-
The RAG pipeline is based on LlamaIndex.
curl -X POST http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"prompt": "string","stream": true}'
推荐学习
人工智能测试开发训练营,为大家提供全方位的人工智能测试知识和技能培训。行业专家授课,实战驱动,并提供人工智能答疑福利。内容包含ChatGPT与私有大语言模型的多种应用,人工智能应用开发框架 LangChain,视觉与图像识别自动化测试,人工智能产品质量保障与测试,知识图谱与模型驱动测试,深度学习应用,带你一站式掌握人工智能测试开发必备核心技能,快速提升核心竞争力!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









