






這幾天拿了一個題目自己練習寫python,才發現cpython是使用ascii來處理字串,對於unicode處理較不拿手。在這邊介紹一些python中使用unicode的方法。
首先要先確認使用的是script或是直譯器
script就要確認文件的編碼,直譯器則要確定所使用的shell的環境。
使用script的話,在一開始文件編輯列,要先加入宣告,文件編輯軟體(如vi等)才會儲存為UTF-8字元。
# -*- coding: <encoding_name>-*-
例如下面這行就可以宣告本文件應以UTF-8格式儲存:
# -*- coding: utf-8 -*-
這邊可以參考以下網址
http://www.python.org/dev/peps/pep-0263/
若是使用直譯器,就要確定shell的環境變數LANG。
配置字串的時候,將字串配置為unicode格式:
如果LANG=zh_TW.UTF-8:
unicode_str = unicode('這是中文', 'utf-8')
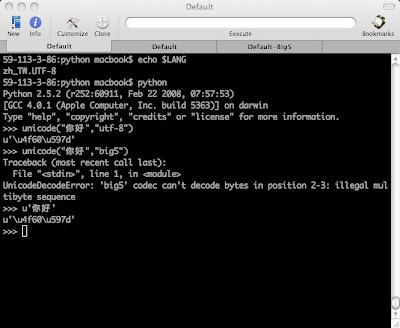
如果LANG=zh_TW.BIG5:
unicode_str = unicode('這是中文', 'big5')
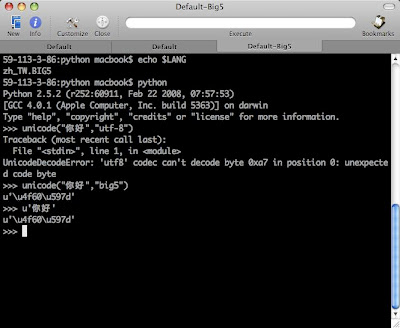
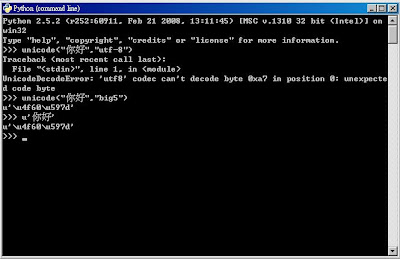
windows中則shell的環境一定為big5:
也有比較簡單的方法,無論LANG變數為何都可以運作:
unicode_str = u'這是中文'
之後檢查
>>> type(unicode_str)(type 'unicode')
如果想要用big5顯示,可以這樣做
print unicode('這是中文', 'utf-8').decode('big5')
另外,raw_input()這個功能也有一些問題
raw_input(u'Please input')raw_input(u'請輸入')
前者會成功,後者卻會失敗
筆者猜想可能是raw_input依然使用ascii來處理字串的關係。
唯一解決方法就是不要讓raw_input裡面塞入unicode的中文了。
在網站上也另外看到一個文件:
http://czug.org/blog/eishn/sqlobject-dezhongwenbianmawentijijiejuefangan
簡單來說,sys這個module原本有setdefaultencoding這個function,但在啟動腳本setting.py中卻被刪除了。而這個功能可以經由reload(sys)來啟用。
因此可以在script開始時這樣寫入:
import sysif sys.getdefaultencoding() != 'utf-8':reload(sys)sys.setdefaultencoding('utf-8')
很多問題就可以解決囉!
參考網址:
http://evanjones.ca/python-utf8.html

















 5991
5991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









