







递归算法是一种直接或间接调用自身算法的过程,特点如下:
1、递归就是在过程或函数里调用自身。
2、在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。
3、递归算法解题通常显得简洁,但解题的运行效率较低。
4、在递归调用的过程中为每一层的返回点、局部变量等开辟栈来存储,递归次数过多易造成栈溢出。
递归算法体现的“重复”一般有三个要求:
1、每次调用在规模上都缩小(通常为减半)。
2、相邻两次重复之间有紧密联系,前一次要为后一次做准备(通常前一次的输出作为后一次的输入)。
3、问题的规模极小时必须直接给出解答而不再进行递归调用,因而每次递归都是有条件的(以规模未达到直接解答的大小为条件),无条件递归调用将会成为死循环。
应用:
(1)斐波那契数列
def fibonacci(arg1,arg2,stop_arg):
if arg1 == 0:
print(arg1,arg2)
arg3 = arg1 + arg2
print(arg3)
if arg3 < stop_arg:
fibonacci(arg2,arg3,stop_arg)(2)二分法查找
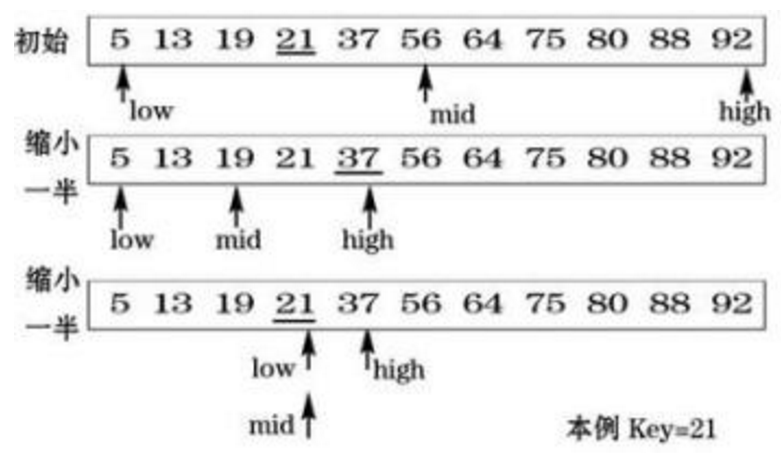
递归算法:
def binary_search(data_source,find_n):
mid = int(len(data_source)/2)
if len(data_source) > 1:
if data_source[mid] > find_n:
print("data in left of [%s]"%data_source[mid])
binary_search(data_source[:mid],find_n)
elif data_source[mid] < find_n:
print("data in right of [%s]"%data_source[mid])
binary_search(data_source[mid:],find_n)
else:
print("found find_s",data_source[mid])
else:
print("cannot find")非递归算法:
def bin_search(data_source,find_n):
high = data_source[-1]
low = data_source[0]
while low < high:
mid = int((low+high)/2)
if data_source[mid] > find_n:
high = mid - 1
elif data_source[mid] < find_n:
low = mid + 1
else:
return mid
else:
return -1














 8921
8921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









