





作为延续解剖的-Apache的火花的工作后,我将分享如何利用星火UI调谐工作。 我将继续使用先前文章中使用的相同示例,新的spark应用程序将在以下方面完成工作
–阅读纽约市停车票
–通过“板ID”进行汇总并计算违规日期
–保存结果
此代码的DAG看起来像这样
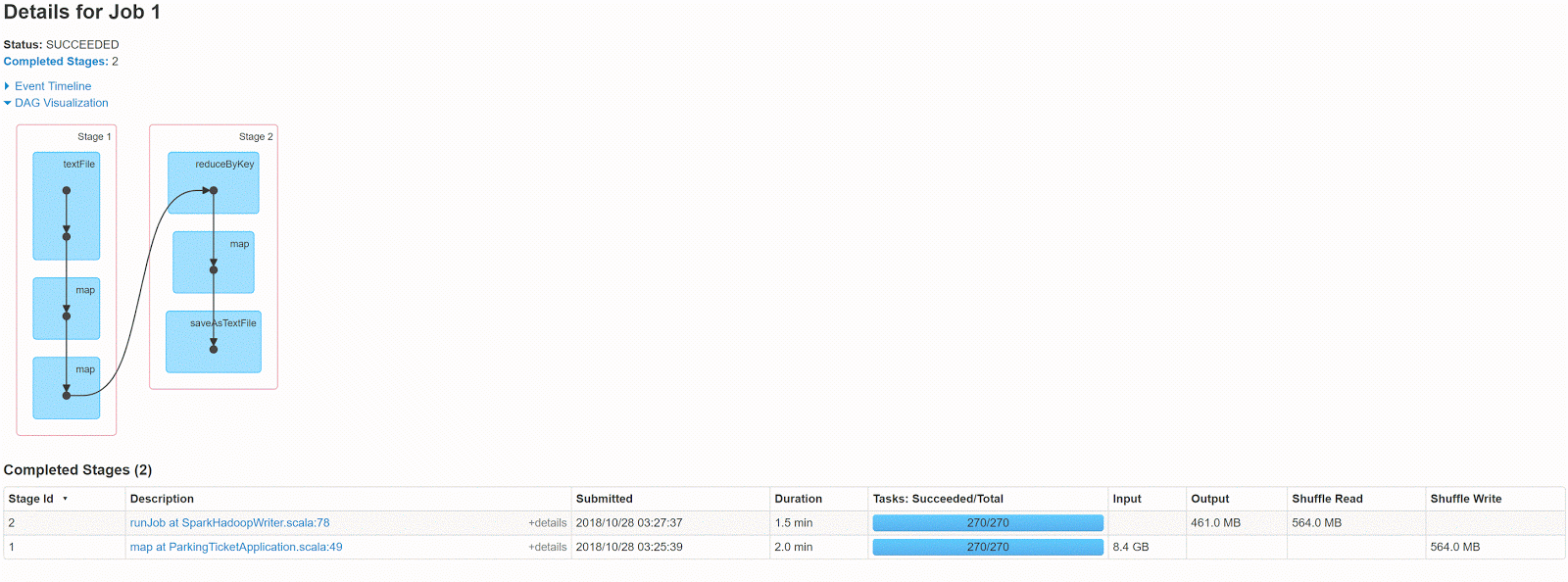
这是多阶段的工作,因此需要一些数据混洗,因为此示例混洗写入为564mb,输出为461MB。
让我们看看我们可以做些什么来减少这种情况?
让我们从“ Stage2”开始采取自上而下的方法。 首先想到的是探索压缩。
当前代码
aggValue.map {
case (key, value) => Array(key, value._1, value._2.mkString(",")).mkString("\t")
}.saveAsTextFile(s"/data/output/${now}")新密码
aggValue.map {
case (key, value) => Array(key, value._1, value._2.mkString(",")).mkString("\t")
}.saveAsTextFile(s"/data/output/${now}", classOf[GzipCodec])新代码仅在写入时启用gzip,让我们看看我们在Spark UI上看到的内容

用Gzip保存
只需写入编码器,写入量下降了70%。 现在达到135Mb并加快了工作速度。
让我们先看看还有什么可能,然后再进行更多的内部调整
最终输出如下所示
1RA32 1 05/07/2014
92062KA 2 07/29/2013,07/18/2013
GJJ1410 3 12/07/2016,03/04/2017,04/25/2015
FJZ3486 3 10/21/2013,01/25/2014
FDV7798 7 03/09/2014,01/14/2014,07/25/2014,11/21/2015,12/04/2015,01/16/2015进攻日期以原始格式存储,可以对此应用少量编码以提高速度。
Java 8添加了LocalDate来简化日期操作,该类带有一些方便的功能,其中之一就是toEpocDay。
此函数将日期转换为1970年的日期,因此这意味着在4个字节(Int)中,我们最多可以存储5K年,与当前格式占用10个字节相比,这似乎可以节省很多。
epocDay的代码段
val issueDate = LocalDate.parse(row(aggFieldsOffset.get("issue date").get), ISSUE_DATE_FORMAT)
val issueDateValues = mutable.Set[Int]()
issueDateValues.add(issueDate.toEpochDay.toInt)
result = (fieldOffset.map(fieldInfo => row(fieldInfo._2)).mkString(","), (1, issueDateValues))更改后的Spark UI。 我还做了另一项更改以使用KryoSerializer

这是一个巨大的改进,随机写入从564Mb更改为409MB(提高27%),输出从134Mb更改为124 Mb(提高8%)
现在让我们转到Spark UI上的另一部分,该部分显示了执行者端的日志。
以上运行的GC日志显示以下内容
2018-10-28T17:13:35.332+0800: 130.281: [GC (Allocation Failure) [PSYoungGen: 306176K->20608K(327168K)] 456383K->170815K(992768K), 0.0222440 secs] [Times: user=0.09 sys=0.00, real=0.03 secs]
2018-10-28T17:13:35.941+0800: 130.889: [GC (Allocation Failure) [PSYoungGen: 326784K->19408K(327168K)] 476991K->186180K(992768K), 0.0152300 secs] [Times: user=0.09 sys=0.00, real=0.02 secs]
2018-10-28T17:13:36.367+0800: 131.315: [GC (GCLocker Initiated GC) [PSYoungGen: 324560K->18592K(324096K)] 491332K->199904K(989696K), 0.0130390 secs] [Times: user=0.11 sys=0.00, real=0.01 secs]
2018-10-28T17:13:36.771+0800: 131.720: [GC (GCLocker Initiated GC) [PSYoungGen: 323744K->18304K(326656K)] 505058K->215325K(992256K), 0.0152620 secs] [Times: user=0.09 sys=0.00, real=0.02 secs]
2018-10-28T17:13:37.201+0800: 132.149: [GC (Allocation Failure) [PSYoungGen: 323456K->20864K(326656K)] 520481K->233017K(992256K), 0.0199460 secs] [Times: user=0.12 sys=0.00, real=0.02 secs]
2018-10-28T17:13:37.672+0800: 132.620: [GC (Allocation Failure) [PSYoungGen: 326016K->18864K(327168K)] 538169K->245181K(992768K), 0.0237590 secs] [Times: user=0.17 sys=0.00, real=0.03 secs]
2018-10-28T17:13:38.057+0800: 133.005: [GC (GCLocker Initiated GC) [PSYoungGen: 324016K->17728K(327168K)] 550336K->259147K(992768K), 0.0153710 secs] [Times: user=0.09 sys=0.00, real=0.01 secs]
2018-10-28T17:13:38.478+0800: 133.426: [GC (Allocation Failure) [PSYoungGen: 322880K->18656K(326144K)] 564301K->277690K(991744K), 0.0156780 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
2018-10-28T17:13:38.951+0800: 133.899: [GC (Allocation Failure) [PSYoungGen: 323808K->21472K(326656K)] 582842K->294338K(992256K), 0.0157690 secs] [Times: user=0.09 sys=0.00, real=0.02 secs]
2018-10-28T17:13:39.384+0800: 134.332: [GC (Allocation Failure) [PSYoungGen: 326624K->18912K(317440K)] 599490K->305610K(983040K), 0.0126610 secs] [Times: user=0.11 sys=0.00, real=0.02 secs]
2018-10-28T17:13:39.993+0800: 134.941: [GC (Allocation Failure) [PSYoungGen: 313824K->17664K(322048K)] 600522K->320486K(987648K), 0.0111380 secs] [Times: user=0.00 sys=0.00, real=0.02 secs] 让我们专注于一条线
2018-10-28T17:13:39.993+0800: 134.941: [GC (Allocation Failure) [PSYoungGen: 313824K->17664K(322048K)] 600522K->320486K(987648K) , 0.0111380 secs] [Times: user=0.00 sys=0.00, real=0.02 secs] 次要GC之前的堆为600MB,之后为320MB,总堆大小为987MB。
执行器分配了2GB内存,并且此Spark应用程序未使用所有内存,我们可以通过发送更多任务或更大任务来给执行器增加更多负载。
我将输入分区从270减少到100

带270个输入分区

带100个输入分区
100个输入分区看起来更好,可减少大约10%以上的数据洗牌。
其他技巧
现在,我将分享一些将大大改变GC的东西!
优化前的代码
private def mergeValues(value1: (Int, mutable.Set[Int]), value2: (Int, mutable.Set[Int])): (Int, mutable.Set[Int]) = {
val newCount = value1._1 + value2._1
val dates = value1._2
dates.foreach(d => value2._2.add(d))
(newCount, value2._2)
}
private def saveData(aggValue: RDD[(String, (Int, mutable.Set[Int]))], now: String) = {
aggValue
.map { case (key, value) => Array(key, value._1, value._2.mkString(",")).mkString("\t") }.coalesce(100)
.saveAsTextFile(s"/data/output/${now}", classOf[GzipCodec])
}优化后的代码
private def mergeValues(value1: GroupByValue, value2: GroupByValue): GroupByValue = {
if (value2.days.size > value1.days.size) {
value2.count = value1.count + value2.count
value1.days.foreach(d => value2.days.add(d))
value2
}
else {
value1.count = value1.count + value2.count
value2.days.foreach(d => value1.days.add(d))
value1
}
}
private def saveData(aggValue: RDD[(String, GroupByValue)], now: String) = {
aggValue.mapPartitions(rows => {
val buffer = new StringBuffer()
rows.map {
case (key, value) =>
buffer.setLength(0)
buffer
.append(key).append("\t")
.append(value.count).append("\t")
.append(value.days.mkString(","))
buffer.toString
}
})
.coalesce(100)
.saveAsTextFile(s"/data/output/${now}", classOf[GzipCodec])
}新代码正在对集合进行优化合并,它向大集合中添加了小集合,并且还引入了Case类。
另一种优化是保存功能,其中它使用mapPartitions通过使用StringBuffer减少对象分配。
我使用http://gceasy.io获得了一些GC统计信息。

更改代码之前
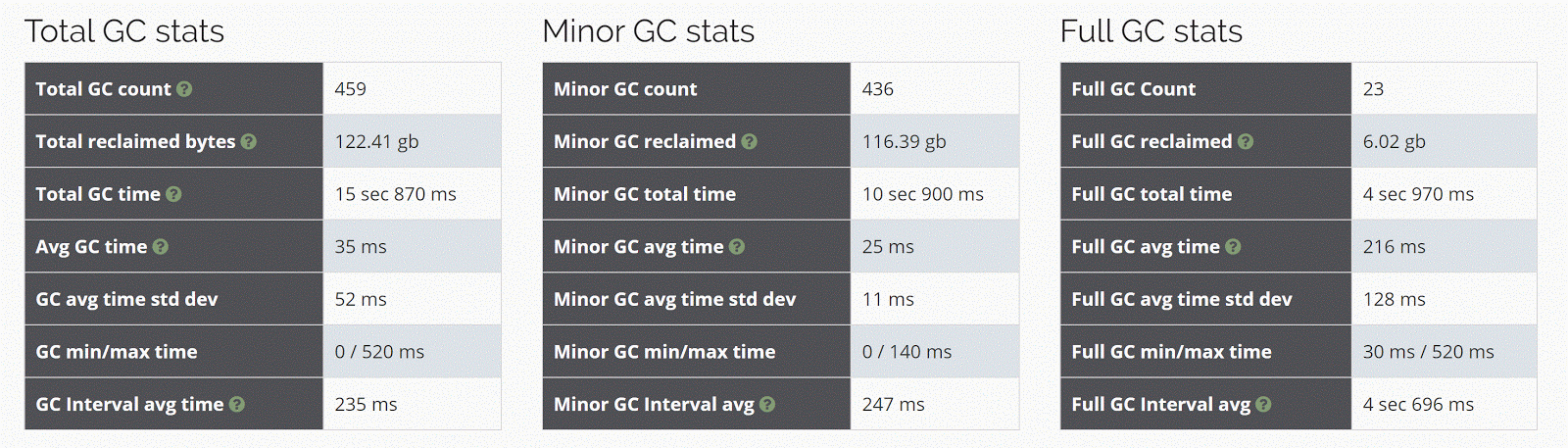
更改代码后
新代码为例如产生更少的垃圾。
总GC 126 GB和122 GB(约提高4%)
最大GC时间720ms与520 ms(约好25%)
优化看起来很有希望。
该博客中使用的所有代码都可以在github repo sparkperformance上找到
请继续关注有关此内容的更多信息。
翻译自: https://www.javacodegeeks.com/2018/11/insights-spark-ui.html















 4100
4100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









