







 文章详细介绍了Spark作业(Job)的执行过程,包括Job的执行时间(TotalUptime)并非所有task的简单相加,它涉及并行执行和时间间隔。Job的调度模型分为FIFO和FAIR,前者先提交先执行,后者依据权重分配执行。Job由action算子触发,stage由transformation算子划分。在DAG图中,skipped的stage表示之前已计算并落盘,无需重算。EventTimeline展示了Executor的加入和退出以及job的起止时间。
文章详细介绍了Spark作业(Job)的执行过程,包括Job的执行时间(TotalUptime)并非所有task的简单相加,它涉及并行执行和时间间隔。Job的调度模型分为FIFO和FAIR,前者先提交先执行,后者依据权重分配执行。Job由action算子触发,stage由transformation算子划分。在DAG图中,skipped的stage表示之前已计算并落盘,无需重算。EventTimeline展示了Executor的加入和退出以及job的起止时间。
Jobs
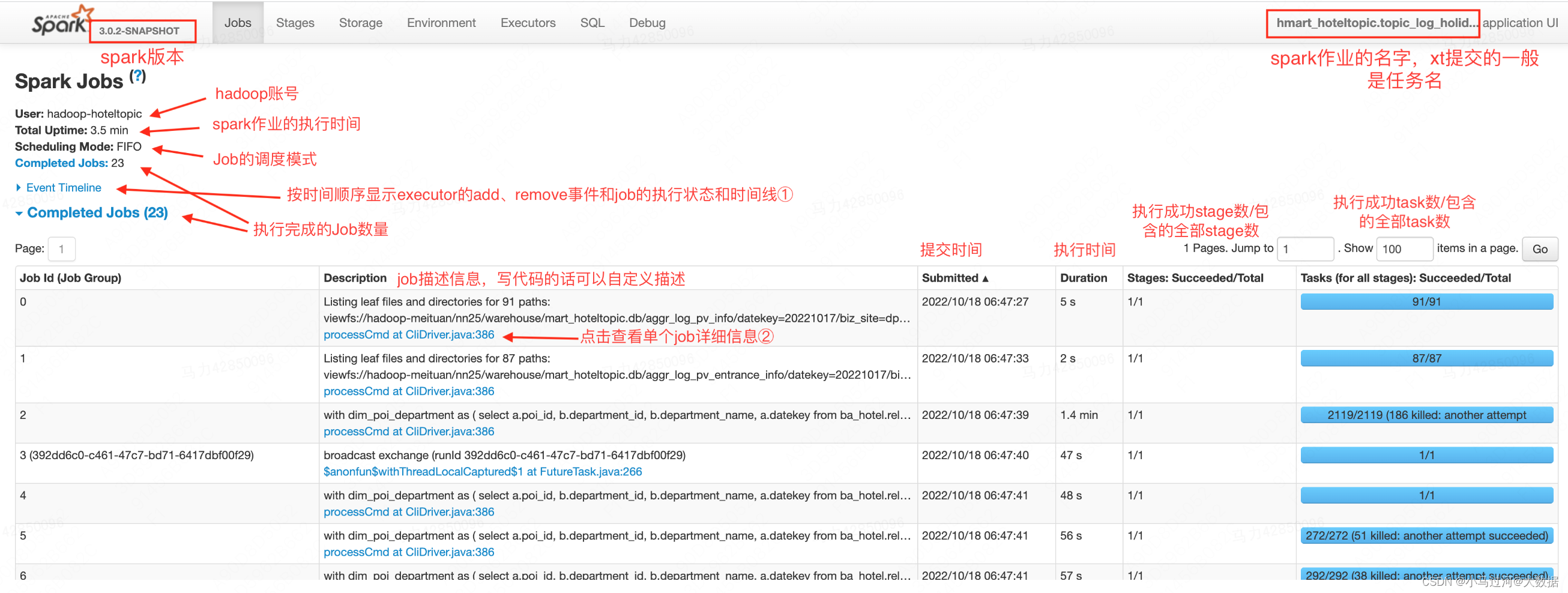
- User:hadoop账号,和登录hope时需要的User相同
- Total Uptime:spark作业的执行时间,完成的作业=结束时间➖开始时间,进行中的作业该值会随着刷新在改变。该时间不是所有job的执行时间之和(有并行的job,job与job之间也有时间间隔),也不是最后一个job的结束时间➖第一个job的提交时间(作业启动到job提交之前还有一些时间)
- Scheduling Model:Job的调度模式,分为FIFO(先进先出)和FAIR(公平调度)。可以并行的Job,FIFO是谁先提交谁先执行可以理解为JobId小的先执行。FAIR会根据权重决定哪个Job先执行
Event Timeline
点击Event Timeline后可以看到以下信息:

时间线会显示Executor加入和退出的时间点, 以及job执行的起止时间.
Jobs Detail
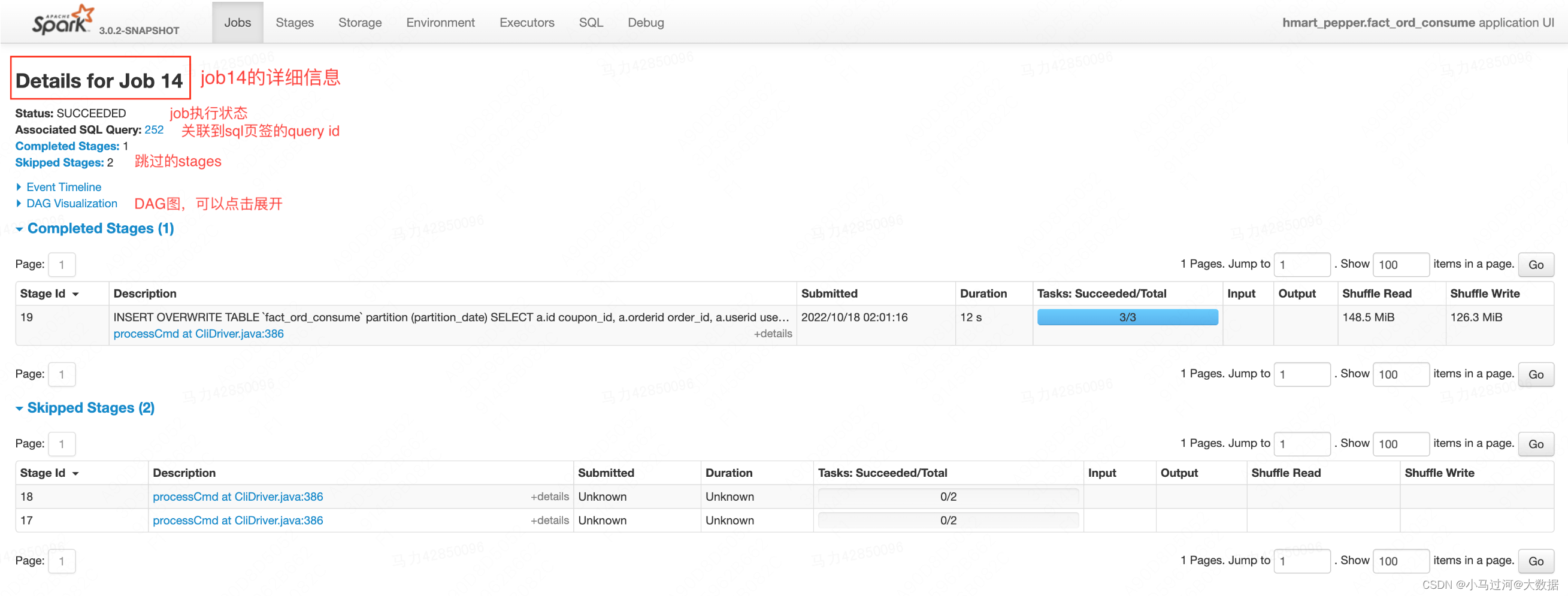
- Status:job的执行状态(running, succeeded, failed)
- Associated SQL Query:关联到sql页签的query id,点击可以跳到SQL页签具体的query
- Number of stages per status :(active, pending, completed, skipped, failed)状态下的stage数量
- Event timeline: 和Jobs中的相同
- DAG Visualization:DAG(directed acyclic graph),有向无环图,显示该job下执行的stage的可视化图,其中顶点表示RDDs或DataFrames,边表示要应用于RDD的操作。
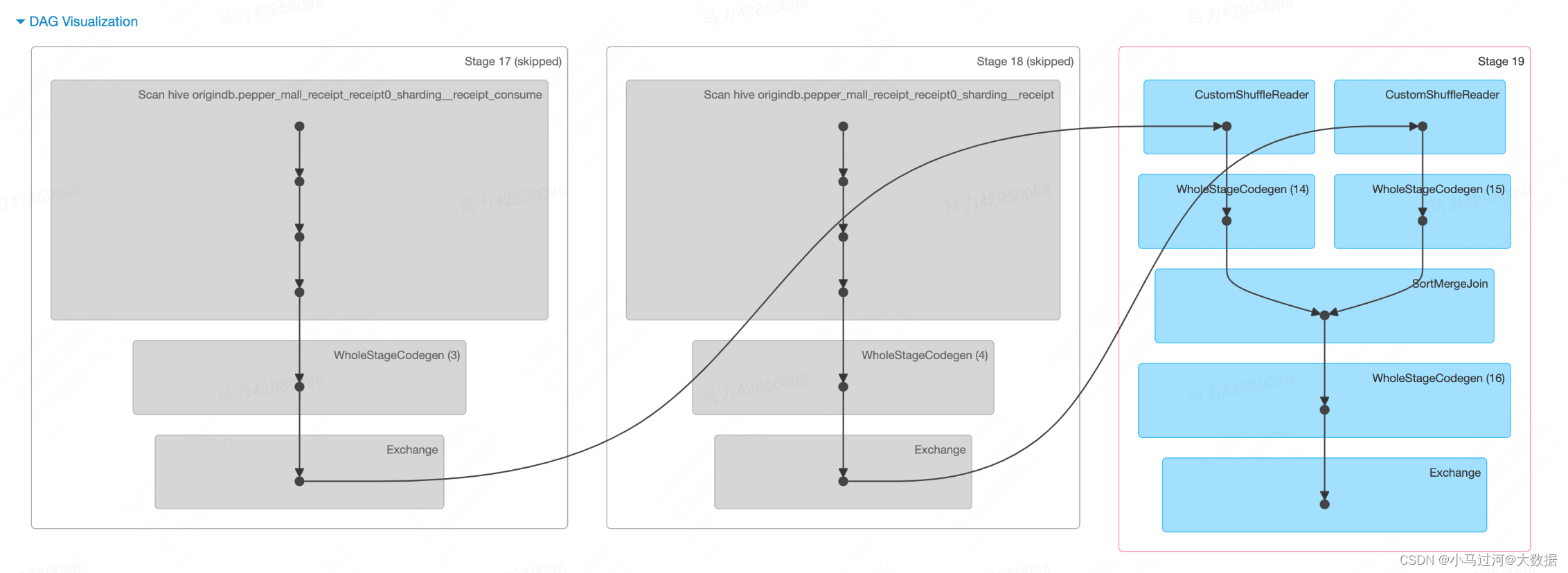
有关Jobs的自问自答
1.多个job可以并行执行吗?
可以,常见的如多个表join,每读一个表可能是一个job,多个表就是多个job,可以并行执行(前提是资源足够)
2.job是如何划分的?
spark中有两类算子,一类是action(行动)算子,一类是transformation(转换)算子。当遇到action算子时就会划分出一个新的job,action算子常见的有reduce、collect、count等,作者并没有找到和sql关键字的对应关系,笼统的说需要落盘存储的一般都是action算子。
job的划分没有太多的意义,可以不必关注,关注stage的划分更有意义。
3.job detai中为什么有些stage可以被跳过(skipped)
skipped的stage代表是之前以前被其他stage执行过并落盘了,并不需要重新计算,可以直接使用之前的结果。
以上面的DAG图为例,stage17和stage18在其他的job中有其他的stage已经shuffle write数据到磁盘,当前job中的stage在做shuffle read时不需要从头开始scan table

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









