





 本文探讨了SBE(Simple Binary Encoding),一个为金融行业设计的快速序列化库。SBE通过全栈优化、无垃圾或少垃圾产生、缓存预取和流媒体访问等特性实现高性能。其设计考虑了CPU缓存和硬件预取,使用不安全API和常量提升效率,并避免分支指令。与protobuf等相比,SBE在大小和速度上更具优势。
本文探讨了SBE(Simple Binary Encoding),一个为金融行业设计的快速序列化库。SBE通过全栈优化、无垃圾或少垃圾产生、缓存预取和流媒体访问等特性实现高性能。其设计考虑了CPU缓存和硬件预取,使用不安全API和常量提升效率,并避免分支指令。与protobuf等相比,SBE在大小和速度上更具优势。
SBE是用于金融行业的非常快速的序列化库,在本博客中,我将介绍一些使其快速发展的设计选择。
序列化的全部目的是对消息进行编码和解码,并且有很多可用的选项,从XML,JSON,Protobufer,Thrift,Avro等开始。
XML / JSON是基于文本的编码/解码,在大多数情况下都很好,但是当延迟很重要时,这些基于文本的编码/解码就会成为瓶颈。
Protobuffer / Thrift / Avro是二进制选项,使用非常广泛。
SBE也是二进制的,是基于机械同情而构建的,以利用基础硬件(CPU缓存,预取程序,访问模式,管线指令等)的优势。
CPU和内存革命的小历史。
我们的行业看到了功能强大的8位,16位,32位,64位处理器,现在普通的台式机CPU可以执行近数十亿条指令,只要程序员能够编写程序来生成这种类型的负载即可。 内存也变得便宜,获得512 GB服务器非常容易。
我们必须改变编程方式以利用所有这些东西,数据结构和算法也必须改变。
让我们潜入sbe。
全栈方法
大多数系统依赖于运行时优化,但是SBE已采用全栈方法,并且第一级优化由编译器完成。
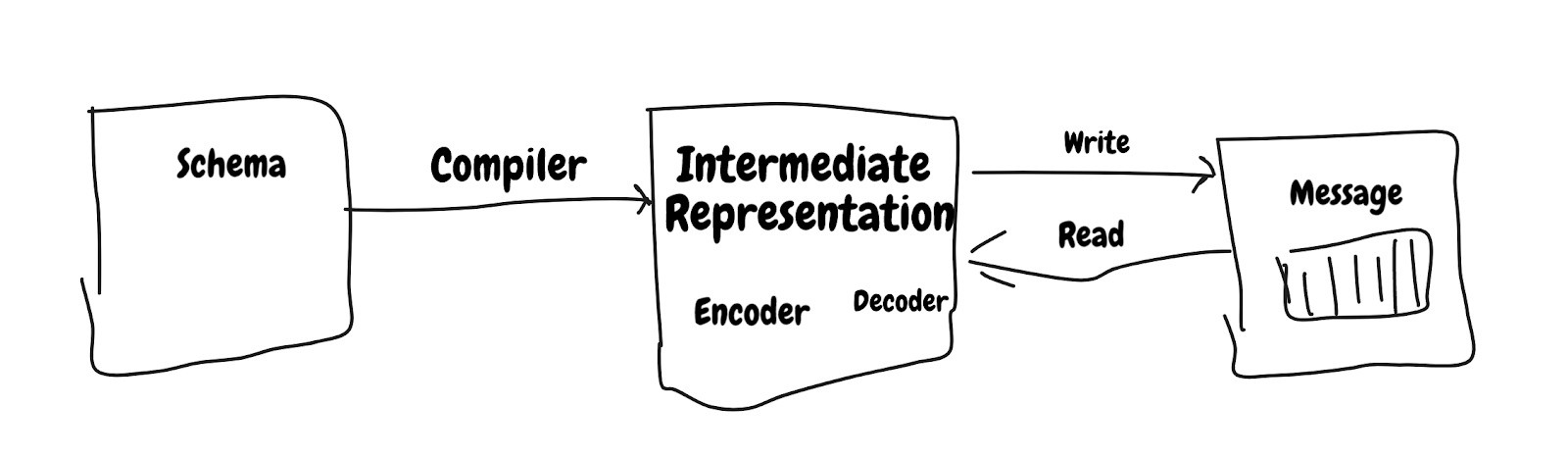
模式 –用于定义消息的布局和数据类型的XML文件。
编译器 –将模式作为输入并生成IR。 在这一层中发生了很多魔术,例如使用最终/常量,优化的代码。
消息 –实际消息被缓冲区包装。
全栈方法允许在各个级别进行优化。
无垃圾或少垃圾
这对于低延迟系统非常重要,如果不注意它,则应用程序将无法正确使用CPU缓存,并且可能进入GC暂停状态。
SBE是围绕flyweight模式构建的,它全部与重用对象有关,以减轻JVM上的内存压力。
它具有缓冲区的概念,并且可以重复使用,编码器/解码器可以将缓冲区作为输入并对其进行处理。 编码器/解码器不分配或分配很少(即在使用String的情况下)。
SBE建议使用直接/分出缓冲区使GC完全脱离图像,这些缓冲区可以在线程级别分配,并且可以用于消息的解码和编码。
缓冲区使用情况的代码段。
final ByteBuffer byteBuffer = ByteBuffer.allocateDirect(4096);
final UnsafeBuffer directBuffer = new UnsafeBuffer(byteBuffer);tradeEncoder .tradeId(1)
.customerId(999)
.qty(100)
.symbol("GOOG")
.tradeType(TradeType.Buy);缓存预取
CPU已内置基于硬件的预取器。 缓存预取是计算机处理器用来提高执行性能的技术,它可以在实际需要之前将指令或数据从较慢内存中的原始存储中提取到较快的本地内存中。
从快速CPU缓存访问数据比从主存储器访问数据快许多个数量级。
等待时间,您应该知道的博客文章详细介绍了CPU高速缓存的速度。
如果算法正在流式传输并且所使用的基础数据像数组一样连续,则预取效果很好。 数组访问非常快,因为它是连续且可预测的
SBE使用数组作为基础存储,并将字段打包在其中。
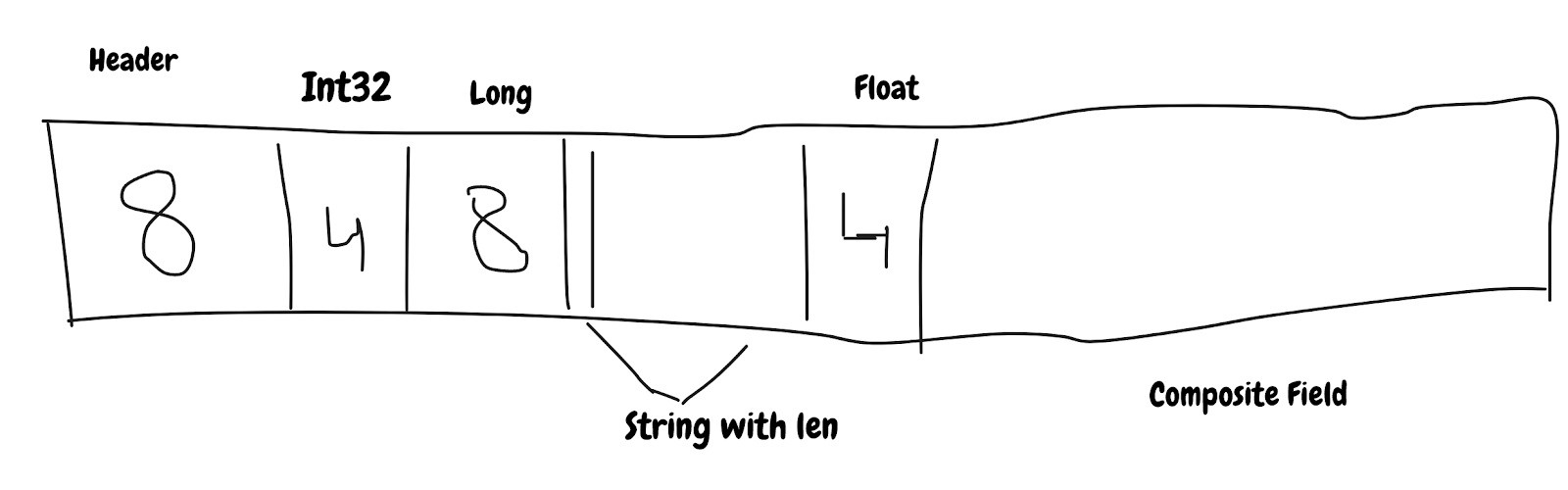
数据以小批量的高速缓存行(通常为8个字节)移动,因此,如果应用程序要求1个字节,它将获得8个字节的数据。 由于数据打包在数组中,因此可以提前访问单字节预取数组内容,这将加快处理速度。
将预取器视为数据库表中的索引。 如果读取基于这些索引,则应用程序将受益。
流媒体访问
SBE支持所有原始类型,并且还允许定义大小可变的自定义类型,这使编码器和解码器可以流式传输和顺序传输。 从高速缓存行中读取数据具有很好的好处,并且解码器几乎不需要了解有关消息的元数据(即偏移量和大小)。
附带权衡的读取顺序必须基于布局顺序,尤其是在对可变类型的数据进行编码的情况下。
例如写正在使用以下顺序
tradeEncoder .tradeId(1)
.customerId(999)
.tradeType(TradeType.Buy)
.qty(100)
.symbol("GOOG")
.exchange("NYSE");对于String属性(符号和交换),读取顺序必须是第一个符号 ,然后是exchange ,如果应用程序交换顺序,则它将读取错误的字段,对于可变长度属性,另一项读取应仅为一次,因为它是流访问模式。
好东西是有代价的!
不安全的API
数组绑定检查可能会增加开销,但是SBE使用的是不安全的API,并且没有额外的绑定检查开销。
在生成的代码上使用常量
编译器生成代码时,它会预先计算内容并使用常量。 一个示例是在生成的代码中存在字段偏移,但不进行计算。
程式码片段
public static int qtyId()
{
return 2;
}
public static int qtySinceVersion()
{
return 0;
}
public static int qtyEncodingOffset()
{
return 16;
}
public static int qtyEncodingLength()
{
return 8;
}这需要权衡,这对性能有利,但对灵活性不利。 您无法更改字段顺序,必须在末尾添加新字段。
关于常量的另一个好处是,它们仅在生成的代码中存在,而在消息中却没有,这是非常有效的。
分支免费代码
每个内核都有多个并行运行的端口,几乎没有指令会像分支,mod,除法那样阻塞。 SBE编译器生成的代码无需使用这些昂贵的指令,并且具有基本的指针碰撞数学功能。
没有昂贵指令的代码非常快,它将利用内核的所有端口。
Java序列化的示例代码
public void writeFloat(float v) throws IOException {
if (pos + 4 <= MAX_BLOCK_SIZE) {
Bits.putFloat(buf, pos, v); pos += 4; } else {
dout.writeFloat(v); }
}
public void writeLong(long v) throws IOException {
if (pos + 8 <= MAX_BLOCK_SIZE) {
Bits.putLong(buf, pos, v); pos += 8; } else {
dout.writeLong(v); }
}
public void writeDouble(double v) throws IOException {
if (pos + 8 <= MAX_BLOCK_SIZE) {
Bits.putDouble(buf, pos, v); pos += 8; } else {
dout.writeDouble(v); }
}SBE的示例代码
public TradeEncoder customerId(final long value)
{
buffer.putLong(offset + 8, value, java.nio.ByteOrder.LITTLE_ENDIAN); return this;}public TradeEncoder tradeId(final long value)
{
buffer.putLong(offset + 0, value, java.nio.ByteOrder.LITTLE_ENDIAN); return this;}邮件大小上的一些数字。
类型级元帅.SerializableMarshal-> 267号
输入class marshal.ExternalizableMarshal-> size 75
输入类元帅SBEMarshall->大小49
SBE最紧凑且速度最快,SBE的作者声称它比Google proto缓冲区快20到50倍。
可提供SBE代码@ simple-binary-encoding
博客中使用的示例代码可在@ sbeplayground获得
翻译自: https://www.javacodegeeks.com/2018/06/inside-simple-binary-encoding-sbe.html















 4300
4300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









