





什么是Apache Kafka?
Apache Kafka是一个分布式流系统,具有发布和订阅记录流的功能。 在另一方面,它是企业消息传递系统。 它是一个快速,水平可扩展和容错的系统。 Kafka有四个核心API,
生产者API:
该API允许客户端连接到集群中运行的Kafka服务器,并将记录流发布到一个或多个Kafka主题。
使用者API:
该API允许客户端连接到集群中运行的Kafka服务器,并使用一个或多个Kafka主题的记录流。 卡夫卡的消费者是直接从卡夫卡主题的消息。
流API:
此API通过使用来自一个或多个主题的流并将这些流生成到其他输出主题,从而使客户端充当流处理器。 这允许转换输入和输出流。
连接器API:
该API允许编写可重用的生产者和使用者代码。 例如,如果我们要从任何RDBMS读取数据以将数据发布到主题,并使用主题中的数据并将其写入RDBMS。 使用连接器API,我们可以为各种数据源创建可重用的源连接器和接收器连接器组件。
Kafka用于什么用例?
Kafka用于以下用例,
讯息系统:
Kafka用作企业消息传递系统,以分离源系统和目标系统以交换数据。 与JMS相比,Kafka具有分区的高吞吐量和具有复制功能的容错能力。
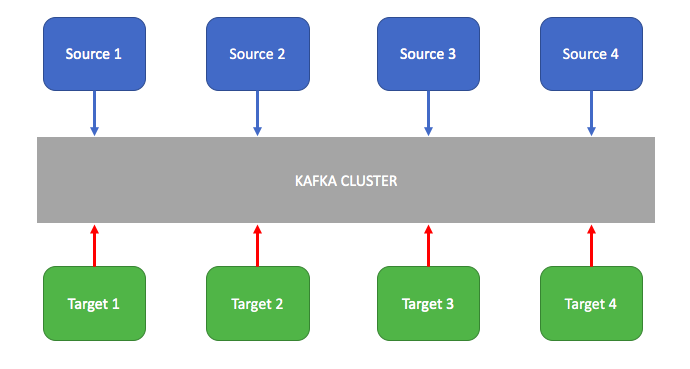
网络活动跟踪:
跟踪网站上的用户旅程事件以进行分析和脱机数据处理。
日志汇总:
处理来自各种系统的日志。 特别是在具有微服务架构的分布式环境中,该系统将系统部署在各种主机上。 我们需要汇总来自各种系统的日志,并在中央位置提供日志以进行分析。 浏览有关使用Kafka的分布式日志记录体系结构的文章https://smarttechie.org/2017/07/31/distributed-logging-architecture-for-micro-services/
指标收集器:
Kafka用于从各种系统和网络收集指标以进行操作监视。 Kafka指标报告器可用于监控工具,例如Ganglia , Graphite等…
关于此https://github.com/stealthly/metrics-kafka的一些参考
什么是经纪人?
Kafka群集中的一个实例称为代理。 在Kafka群集中,如果您连接到任何一个代理,您将可以访问整个群集。 我们连接到访问群集的代理实例也称为引导服务器。 每个代理由集群中的数字ID标识。 首先从Kafka集群开始,三个经纪人是一个不错的选择。 但是有些集群中有数百个经纪人。
什么是主题?
主题是将记录发布到的逻辑名称。 在内部,该主题分为数据发布到的分区。 这些分区分布在群集中的代理之间。 例如,如果一个主题有三个分区,群集中有3个代理,则每个代理都有一个分区。 要发布到分区的数据仅附加偏移量增量。
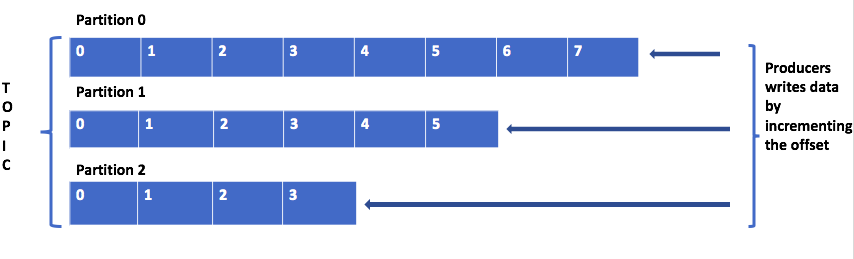
以下是在使用分区时需要记住的几点。
- 主题由其名称标识。 一个集群中可以有很多主题。
- 消息的顺序保持在分区级别,而不是跨主题。
- 一旦写入分区的数据不被覆盖。 这称为不变性。
- 分区中的消息与键,值和时间戳一起存储。 Kafka确保将给定密钥的消息发布到同一分区。
- 在Kafka群集中,每个分区都有一个领导者,该领导者将对该分区进行读/写操作。
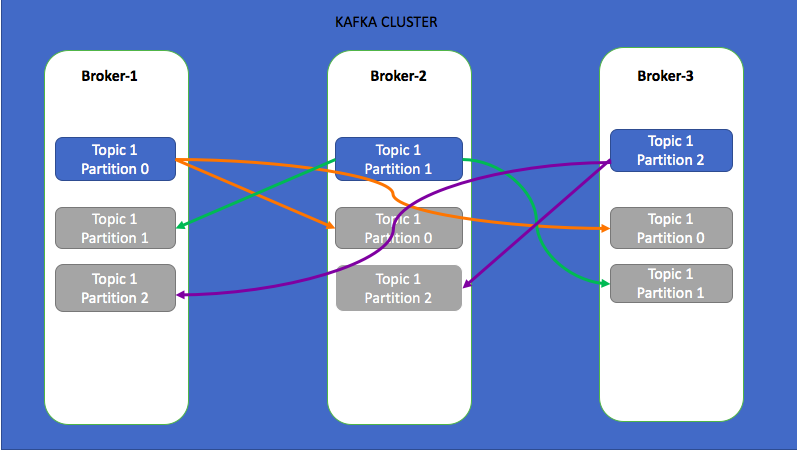
在上面的示例中,我创建了一个主题,其中包含三个具有复制因子3的分区。在这种情况下,因为集群具有3个代理,所以这三个分区是均匀分布的,每个分区的副本都复制到另外2个代理中。 由于复制因子为3,因此即使有2个代理发生故障,也不会丢失数据。 始终保持复制因子大于1且小于或等于集群中的代理数目。 您创建的主题的复制因子不能超过集群中代理的数量。
在上图中,每个分区都有一个领导者(发光分区),其他同步副本(灰色分区)是跟随者。 对于分区0,broker-1是领导者,broker-2,broker-3是跟随者。 对分区0的所有读/写将进入Broker-1,并且相同的内容将被复制到Broker-2和Broker-3。
现在,让我们按照以下步骤创建具有3个代理的Kafka集群。
步骤1:
下载Apache Kafka最新版本。 在此示例中,我使用的是最新的1.0。 解压缩文件夹并移到bin文件夹中。 启动Zookeeper,这对于从Kafka集群开始至关重要。 Zookeeper是一种协调服务,用于管理代理,对分区的领导者选举以及在主题更改(删除主题,创建主题等)或代理(添加代理,代理人代理等)更改期间向Kafka发出警报。 在此示例中,我仅启动了一个Zookeeper实例。 在生产环境中,我们应该有更多的Zookeeper实例来管理故障转移。 如果没有Zookeeper,Kafka群集将无法正常工作。
./zookeeper-server-start.sh ../config/zookeeper.properties第2步:
现在开始卡夫卡经纪人。 在此示例中,我们将启动三个经纪人。 转到Kafka根目录下的config文件夹,并将server.properties文件复制3次,并将其命名为server_1.properties,server_2.properties和server_3.properties。 在这些文件中更改以下属性。
#####server_1.properties#####
broker.id=1
listeners=PLAINTEXT://:9091
log.dirs=/tmp/kafka-logs-1
#####server_2.properties######
broker.id=2
listeners=PLAINTEXT://:9092
log.dirs=/tmp/kafka-logs-2
######server_3.properties#####
broker.id=3
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-3M现在,使用以下命令运行3个代理。
###Start Broker 1 #######
./kafka-server-start.sh ../config/server_1.properties
###Start Broker 2 #######
./kafka-server-start.sh ../config/server_2.properties
###Start Broker 3 #######
./kafka-server-start.sh ../config/server_3.properties第三步:
使用以下命令创建主题。
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic first_topic第四步:
使用Kafka控制台生成器,向上一步中创建的主题生成一些消息。 对于控制台生产者,请提及任何中间商地址。 这将是引导服务器,用于访问整个群集。
./kafka-console-producer.sh --broker-list localhost:9091 --topic first_topic
>First message
>Second message
>Third message
>Fourth message
>步骤5:
使用Kafka控制台使用者使用消息。 对于Kafka消费者,请提及任何一个代理地址作为引导服务器。 请记住,在阅读邮件时,您可能看不到订单。 由于顺序是在分区级别而不是主题级别维护的。
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first_topic --from-beginning如果需要,可以使用以下命令描述该主题以查看分区的分布方式以及每个分区的领导者。
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic first_topic
#### The Result for the above command#####
Topic:first_topic PartitionCount:3 ReplicationFactor:3 Configs:
Topic: first_topic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: first_topic Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Topic: first_topic Partition: 2 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2在上面的描述中,broker-1是分区0的领导者,broker-1,broker-2和broker-3具有每个分区的副本。
在下一篇文章中,我们将看到生产者和消费者JAVA API。 直到那时, 快乐消息!!!
翻译自: https://www.javacodegeeks.com/2017/11/introduction-apache-kafka.html















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









