





介绍
在我以前的帖子在这里和这里我展示了如何使用JDBC和Elasticsearch JDBC进口商库从SQL数据库索引数据到Elasticsearch。 在这里的第一篇文章中,我提到了使用导入程序库的一些缺点,这些缺点我已在此处复制:
- 不支持ES版本5及更高版本
- 嵌套对象数组中可能存在重复的对象。 但是重复数据删除可以在应用程序层进行处理。
- 对最新ES版本的支持可能会延迟。
使用Logstash及其以下插件可以克服以上所有缺点:
- JDBC Input插件 –用于使用JDBC从SQL DB读取数据
- 聚合过滤器插件 –用于将SQL DB中的行聚合到嵌套对象中。
我将使用最新的ES版,即5.63可以从Elasticsearch网站下载这里 。 我们将使用此处可用的映射创建索引world_v2。
$ curl -XPUT --header "Content-Type: application/json"
http://localhost:9200/world_v2 -d @world-index.json或使用Postman REST客户端,如下所示:
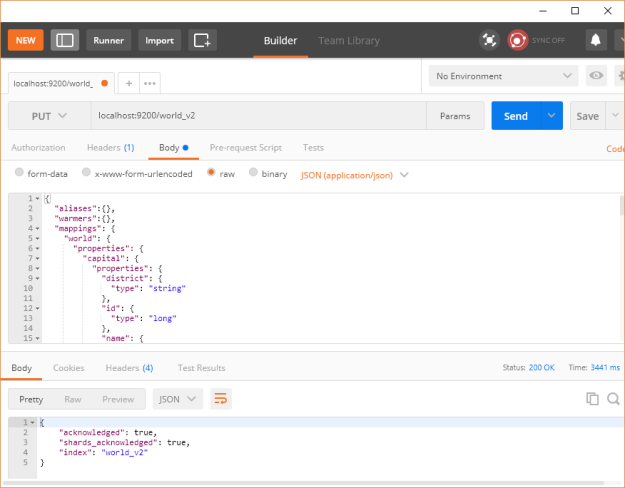
要确认索引已成功创建,请在浏览器中打开此URL http:// localhost:9200 / world_v2,以得到类似于以下内容的内容:

创建Logstash配置文件
我们应该选择等效的logstash版本,即5.6.3,可以从此处下载。 然后,我们需要使用以下命令安装JDBC输入插件,聚合过滤器插件和Elasticsearch输出插件:
bin/logstash-plugin install logstash-input-jdbc
bin/logstash-plugin install logstash-filter-aggregate
bin/logstash-plugin install logstash-output-elasticsearch我们需要将以下内容复制到bin目录中,以便能够运行我们将在接下来定义的配置:
我们将以上内容复制到Logstash的bin目录或您将拥有logstash配置文件的任何目录中,因为这是因为我们在配置中使用这两个文件的相对路径来引用这两个文件。 下面是Logstash配置文件:
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/world"
jdbc_user => "root"
jdbc_password => "mohamed"
# The path to downloaded jdbc driver
jdbc_driver_library => "mysql-connector-java-5.1.6.jar"
jdbc_driver_class => "Java::com.mysql.jdbc.Driver"
# The path to the file containing the query
statement_filepath => "world-logstash.sql"
}
}
filter {
aggregate {
task_id => "%{code}"
code => "
map['code'] = event.get('code')
map['name'] = event.get('name')
map['continent'] = event.get('continent')
map['region'] = event.get('region')
map['surface_area'] = event.get('surface_area')
map['year_of_independence'] = event.get('year_of_independence')
map['population'] = event.get('population')
map['life_expectancy'] = event.get('life_expectancy')
map['government_form'] = event.get('government_form')
map['iso_code'] = event.get('iso_code')
map['capital'] = {
'id' => event.get('capital_id'),
'name' => event.get('capital_name'),
'district' => event.get('capital_district'),
'population' => event.get('capital_population')
}
map['cities_list'] ||= []
map['cities'] ||= []
if (event.get('cities_id') != nil)
if !( map['cities_list'].include? event.get('cities_id') )
map['cities_list'] << event.get('cities_id')
map['cities'] << {
'id' => event.get('cities_id'),
'name' => event.get('cities_name'),
'district' => event.get('cities_district'),
'population' => event.get('cities_population')
}
end
end
map['languages_list'] ||= []
map['languages'] ||= []
if (event.get('languages_language') != nil)
if !( map['languages_list'].include? event.get('languages_language') )
map['languages_list'] << event.get('languages_language')
map['languages'] << {
'language' => event.get('languages_language'),
'official' => event.get('languages_official'),
'percentage' => event.get('languages_percentage')
}
end
end
event.cancel()
"
push_previous_map_as_event => true
timeout => 5
}
mutate {
remove_field => ["cities_list", "languages_list"]
}
}
output {
elasticsearch {
document_id => "%{code}"
document_type => "world"
index => "world_v2"
codec => "json"
hosts => ["127.0.0.1:9200"]
}
}我们将配置文件放置在logstash的bin目录中。 我们使用以下命令运行logstash管道:
$ logstash -w 1 -f world-logstash.conf我们使用1个工作程序,因为当汇总发生时,多个工作人员可能会破坏汇总,这是基于具有共同国家/地区代码的事件序列。 成功完成Logstash管道后,我们将看到以下输出:
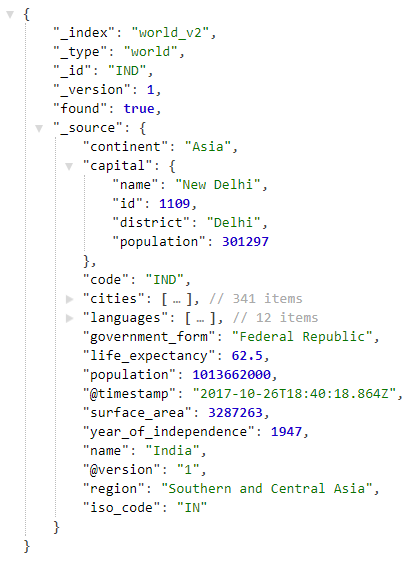
在浏览器中打开以下URL http:// localhost:9200 / world_v2 / world / IND ,以查看在Elasticsearch中索引的印度的信息,如下所示:
翻译自: https://www.javacodegeeks.com/2017/10/aggregate-index-data-elasticsearch-using-logstash-jdbc.html















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









