





初赛
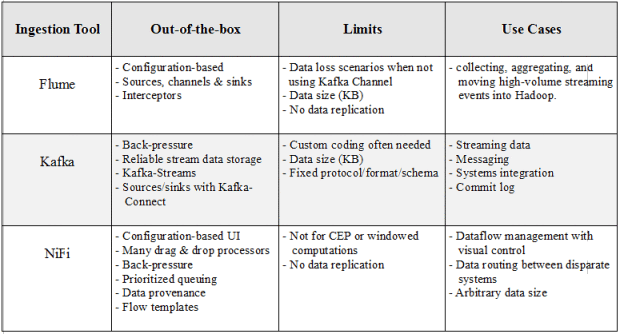
在构建大数据管道时,我们需要考虑如何吸收通常在Hadoop生态系统中出现的数据的数量,多样性和速度。 在决定采用哪种工具来满足我们的要求时,诸如可伸缩性,可靠性,适应性,开发时间成本等方面的初步考虑都将发挥作用。 在这篇文章中。 我们将简要介绍三个Apache提取工具: Flume , Kafka和NiFi 。 所有这三种产品均具有出色的性能,可以水平缩放,并提供一种插件架构,可以通过自定义组件扩展功能。
阿帕奇水槽
Flume部署由一个或多个配置了拓扑的代理组成。 Flume Agent是一个JVM进程,它承载Flume拓扑的基本构建块,即源,通道和接收器。 Flume客户端将事件发送到源,源将这些事件成批放置到称为通道的临时缓冲区中,然后数据从那里流到连接到数据最终目标的接收器。 接收器也可以是其他Flume代理的后续数据源。 代理可以链接起来,并且每个都有多个源,通道和接收器。
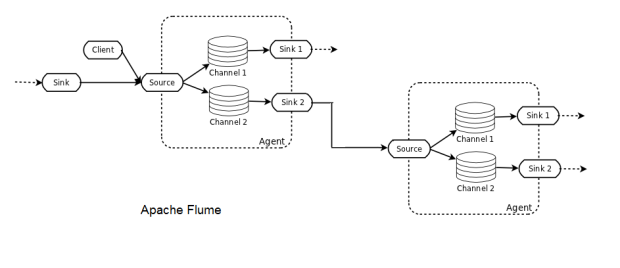
Flume是一个分布式系统,可用于收集,聚合流事件并将其传输到Hadoop中。 它带有许多内置源,通道和接收器,例如Kafka Channel和Avro接收器。 Flume基于配置,并具有拦截器 ,可对运行中的数据执行简单的转换。
如果不小心,很容易使用Flume丢失数据。 例如,选择内存通道以实现高吞吐量具有不利的一面,即当代理程序节点发生故障时,数据将丢失。 文件通道将以增加延迟为代价提供持久性。 即使这样,由于数据不会复制到其他节点,因此File通道仅与基础磁盘一样可靠。 Flume确实通过多跳/扇入扇出流提供了可伸缩性。 对于高可用性(HA),可以水平缩放代理。
阿帕奇·卡夫卡
Kafka是一种分布式的高吞吐量消息总线,可将数据生产者与消费者分离 。 消息按主题进行组织,主题被划分为多个分区,并且跨集群中的节点(称为代理)复制分区。 与Flume相比,Kafka具有更好的可伸缩性和消息持久性。 Kafka现在有两种形式:“经典”生产者/消费者模型,以及新的Kafka-Connect ,它提供了到外部数据存储的可配置连接器(源/接收器)。
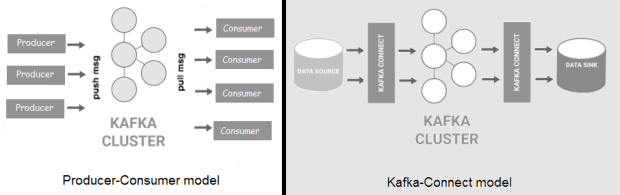
Kafka可用于事件处理以及大型软件系统的组件之间的集成。 开箱即用地处理数据峰值和背压 (快速生产,缓慢消费)。 此外,Kafka附带有Kafka Streams ,可以将其用于简单的流处理,而无需像Apache Spark或Apache Flink那样需要单独的集群。
由于消息在磁盘上持久保存并在群集中复制,因此数据丢失的情况比Flume少见。 也就是说,使用Kafka客户端或通过Connect API,生产者/源和消费者/接收者通常需要自定义编码。 与Flume一样,邮件大小也有限制。 最后,为了能够进行通信,Kafka的生产者和消费者都必须就协议,格式和模式达成共识,这在某些情况下可能会出现问题。
Apache NiFi
NiFl与Flume和Kafka不同。 可以处理任意大小的消息。 NiFi在基于Web的拖放式UI的背后,在群集中运行,并提供实时控制,可轻松管理任何源与任何目标之间的数据移动。 它支持格式,架构,协议,速度和大小不同的分散源。
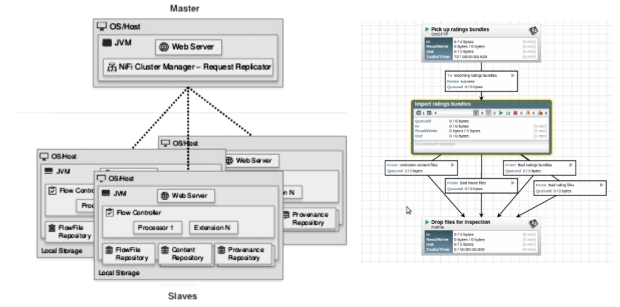
NiFi可以用于具有严格安全性和合规性要求的关键任务数据流,我们可以在其中可视化整个过程并立即进行实时更改。 在撰写本文时,它具有近200个开箱即用的处理器(包括Flume和Kafka处理器),可以立即拖放,配置和投入使用。 NiFi的一些关键功能是优先排序队列,数据可追溯性和每个连接的背压阈值配置。
尽管NiFi用来创建容错生产流水线,但它尚未像Kafka一样复制数据。 如果某个节点发生故障,则可以将流定向到另一个节点,但是排队到故障节点的数据将不得不等待,直到该节点恢复正常。 NiFi并不是成熟的ETL工具,也不是复杂计算和事件处理( CEP )的理想选择。 为此,它应该连接到Apache Flink,Spark Streaming或Storm之类的流框架。
组合方式
没有一个可以同时完成所有任务并满足您所有需求的单一工具。 结合使用以更好的方式完成不同任务的工具,可以增强功能,并在处理更多场景时增加灵活性。 根据您的需求,NiFi和Flume都可以充当Kafka的生产者和/或消费者。
Flume-Kafka集成非常流行,它有自己的名字: Flafka (我没有做这个)。 Flafka包括Kafka源,Kafka频道和Kafka水槽。 将Flume和Kafka结合使用可使Kafka避免自定义编码,并利用Flume经过战斗测试的源和接收器,而通过Kafka渠道存储的Flume事件将在Kafka经纪人之间进行存储和复制,以实现弹性。
组合工具可能看起来很浪费,因为它似乎在功能上造成了一些重叠。 对于 例如,NiFi和Kafka都提供经纪人来联系生产者和消费者。 但是,它们的做法有所不同:在NiFi中,大部分数据流逻辑都不位于生产者/消费者内部,而是位于代理中,从而可以进行集中控制。 NiFi的创建是为了做好一件重要的事情: 数据流管理 。 结合使用这两种工具,NiFi可以利用Kafka可靠的流数据存储,同时解决Kafka并非旨在解决的数据流挑战。
结论
总结:
还有更多要讨论的内容,但这将是书的主题而不是文章。 另外,由于此处提到的工具正在Swift发展,因此与所有其他有关新兴技术的简短分析一样,迟早也必将过时。
翻译自: https://www.javacodegeeks.com/2017/07/big-data-ingestion-flume-kafka-nifi.html















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









