






数据摄入
数据摄入是指为了立即使用数据或者将数据持久化,从而获取和导入数据的过程。数据摄入包括流式和批量两种方式:流式数据摄入主要指数据源一边产生数据一边导入;而批量数据摄入则主要指不同的数据块(chunk)周期性导入。由于存在大量的不同格式的数据,因此,如何以合理的速度以及过程摄入数据对于业务系统来说具有非常大的挑战。
对于流式数据的摄取,Druid提供了两种方式,分别是Push(推送)和Pull(拉取)。
采用Pull方式摄取数据,需要启动一个实时节点(Realtime Node),通过不同的Firehose摄入不同的流式数据。Firehose可以认为是Druid接入不同数据源的Adapter。例如从Kafka中摄取数据,就可以使用KafkaFirehose;从RabbitMQ中摄取数据,就可以使用RabbitMQFirehose。
采用Push方式摄取数据,需要使用Druid索引服务(Indexing Service)。索引服务会启动一个HTTP服务,数据通过调用这个HTTP服务推送到Druid系统。
Lambda架构
Lambda是实时处理框架Storm的作者Nathan Marz提出的用于同时处理离线和实时数据的架构理念。Lambda架构(LA)旨在满足一个稳定的大规模数据处理系统所需的容错性、低延迟、可扩展的特性。LA的可行性和必要性基于如下假设和原则。
任何数据系统可定义为:query=functional(all data)。
人为容错性(Human Falult-Tolerance):数据是易丢失的。
数据不可变性(Data Immutability):数据是只读的,不再变化。
重新计算(Recomputation):因为上面两个原则,运行函数重新计算结果是可能的
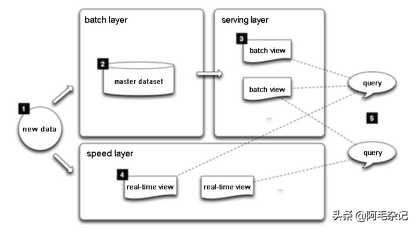
该架构具有如下特点。
所有新数据分别分发到批处理层和实时处理层。
批处理层有两个功能:管理主要的数据(该类数据的特点是只能增加,不能更新);为下一步计算出批处理视图做预计算。
服务层计算出批处理视图中的数据做索引,以提供低延时,即席查询。
实时处理层仅处理实时数据,并为服务层提供查询服务。
任何查询都可以通过实时处理层和批处理层的查询结果合并得到。
Druid在摄取数据时,对于超出时间窗口的数据会直接丢弃,这对于某些要求数据准确性的系统来说,是不可接受的。那么就需要重新摄入这部分数据,参考Lambda的思想,实现方式如图1-1所示。
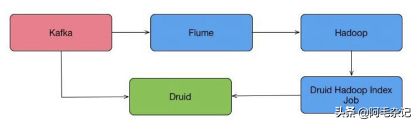
图1-1 Lambda思想的Druid应用架构
流程如下。
(1)源数据都进入Kafka。
(2)数据通过实时节点或者索引服务进入Druid中。
(3)Kafka的数据通过Flume备份到Hadoop。
(4)定时或者发现有数据丢失时,通过Druid Hadoop Index Job重新摄入数据。















 5992
5992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









