





在本演讲中,我将介绍用于Elasticsearch和Spring Data Elasticsearch的三个不同的客户端。 首先,让我们看一下Elasticsearch的一些基础知识。
弹性搜索
为了介绍elasticsearch,我使用的定义直接来自Elastic网站。
Elasticsearch是基于JSON的分布式搜索和分析引擎,旨在实现水平可伸缩性,最大的可靠性和易于管理的功能。
首先让我们看看基于JSON的搜索和分析引擎的含义。
要了解elasticsearch的功能,最好查看搜索页面的示例。 这是每个人都熟悉的,在Github上进行代码搜索。
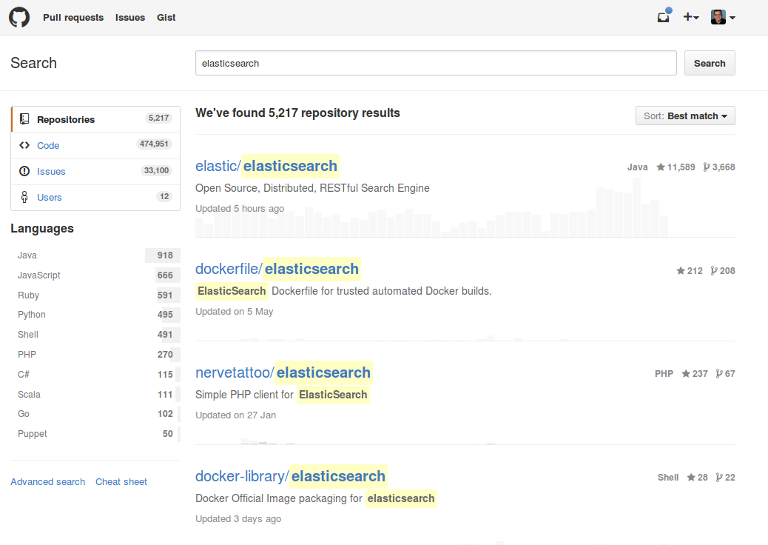
可以在单个搜索输入中输入关键字,下面是结果列表。 搜索引擎和其他数据库之间的显着特征之一是存在相关性的概念。 我们可以看到,对于我们的搜索词elasticsearch来说,搜索引擎的项目是第一位的。 人们在搜索该术语时很可能正在寻找项目。 用来确定结果是否比另一个结果更相关的因素可能因应用程序而异-我不知道Github在做什么,但是我可以想象除了经典的文本相关性功能之外,他们还在使用诸如流行度之类的因素。 像elasitcsearch这样的经典搜索引擎支持的网站上还有更多功能:突出显示结果中出现的内容,对列表进行分页并使用不同的条件进行排序。 在左侧,您可以看到所谓的构面,这些构面可用于根据找到的文档中的条件进一步细化结果列表。 这类似于在ebay和Amazon等电子商务网站上发现的功能。 为此,elasticsearch具有聚合功能,这也是其分析功能的基础。 使用弹性搜索也可以做到这一点。 在这种情况下,这一点更加明显– Github实际上是在使用Elasticsearch来搜索存储的大量数据。
如果要构建这样的搜索应用程序,则必须先安装引擎。 幸运的是,elasticsearch非常容易上手。 除了最近的Java运行时之外,没有其他特殊要求。 您可以从elastic网站上下载elasticsearch档案,将其解压缩并使用脚本启动elasticsearch。
# download archive
wget https://artifacts.elastic.co/downloads/
elasticsearch/elasticsearch-5.0.0.zip
unzip elasticsearch-5.0.0.zip
# on windows: elasticsearch.bat
elasticsearch-5.0.0/bin/elasticsearch对于生产用途,还有用于不同Linux发行版的软件包。 您可以看到通过在标准端口上执行HTTP GET请求来启动elasticsearch。 在示例中,我使用的是curl,它是用于执行HTTP请求的命令行客户端,可用于许多环境。
curl -XGET "http://localhost:9200"elasticsearch将使用包含有关安装信息的JSON文档回答此请求。
{
"name" : "LI8ZN-t",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "UvbMAoJ8TieUqugCGw7Xrw",
"version" : {
"number" : "5.0.0",
"build_hash" : "253032b",
"build_date" : "2016-10-26T04:37:51.531Z",
"build_snapshot" : false,
"lucene_version" : "6.2.0"
},
"tagline" : "You Know, for Search"
}对我们来说,最重要的事实是我们可以看到服务器已启动。 但是,还有关于Elasticsearch和Lucene的版本信息,Lucene是用于大多数搜索功能的基础库。
如果现在我们想将数据存储在elasticsearch中,我们也将其作为JSON文档发送,这次使用POST请求。 因为我非常喜欢新加坡的食物,所以我想构建一个应用程序,让我可以搜索自己喜欢的食物。 让我们索引第一道菜。
curl -XPOST "http://localhost:9200/food/dish" -d'
{
"food": "Hainanese Chicken Rice",
"tags": ["chicken", "rice"],
"favorite": {
"location": "Tian Tian",
"price": 5.00
}
}' 我们使用的端口与之前使用的端口相同,这次我们仅向URL添加两个片段: food和dish 。 第一个是索引的名称,即文件的逻辑集合。 第二种是类型。 它确定了我们要保存的文档的结构,即所谓的映射。
盘子本身被建模为文档。 elasticsearch支持不同的数据类型,如字符串,用于food的属性,就像在一个列表tags和喜欢的,甚至嵌入文档favorite文件。 除此之外,还有更多原始类型,例如数字,布尔值和特殊类型,例如地理坐标。
现在,我们可以索引另一个执行另一个POST请求的文档。
curl -XPOST "http://localhost:9200/food/dish" -d'
{
"food": "Ayam Penyet",
"tags": ["chicken", "indonesian"],
"spicy": true
}' 本文档的结构有些不同。 它不包含“ favorite子文档,但具有另一个“ spicy属性。 相同类型的文档可能会非常不同–但是请记住,您需要解释应用程序中的某些部分。 通常,您将拥有类似的文件。
将这些文档编入索引,就可以自动搜索它们。 一种选择是在/_search上执行GET请求,并将查询项添加为参数。
curl -XGET "http://localhost:9200/food/dish/_search?q=chicken"在两个文档中搜索鸡肉也将同时返回它们。 这是结果的摘录。
...
{"total":2,"max_score":0.3666863,"hits":[{"_index":"food","_type":"dish","_id":"AVg9cMwARrBlrY9tYBqX","_score":0.3666863,"_source":
{
"food": "Hainanese Chicken Rice",
"tags": ["chicken", "rice"],
"favorite": {
"location": "Tian Tian",
"price": 5.00
}
}},
... 有一些全局信息,例如找到的文档数量。 但最重要的属性是hits数组,其中包含我们索引盘的原始来源。
这样很容易上手,但是大多数情况下查询会更复杂。 这就是为什么Elasticsearch提供查询DSL(一种描述查询以及请求的任何其他搜索功能的JSON结构)的原因。
curl -XPOST "http://localhost:9200/food/dish/_search" -d'
{
"query": {
"bool": {
"must": {
"match": {
"_all": "rice"
}
},
"filter": {
"term": {
"tags.keyword": "chicken"
}
}
}
}
}' 我们正在搜索所有包含术语rice并且在tags也包含chicken文档。 使用.keyword访问字段允许进行精确搜索,并且是.keyword 5.0中的新功能。
除了搜索本身之外,您还可以使用查询DSL向Elasticsearch请求更多信息,例如高亮显示或自动补全或可用于构建构面功能的聚合。
让我们继续定义的另一部分。
Elasticsearch是[…]分布式[…],旨在实现水平可伸缩性,最大的可靠性
到目前为止,我们仅访问了一个Elasticsearch实例。
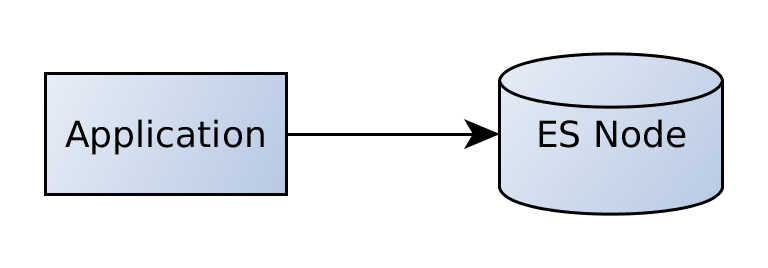
我们的应用程序将直接与该节点通信。 现在,由于Elasticsearch是为水平可伸缩性设计的,因此我们还可以添加更多节点。
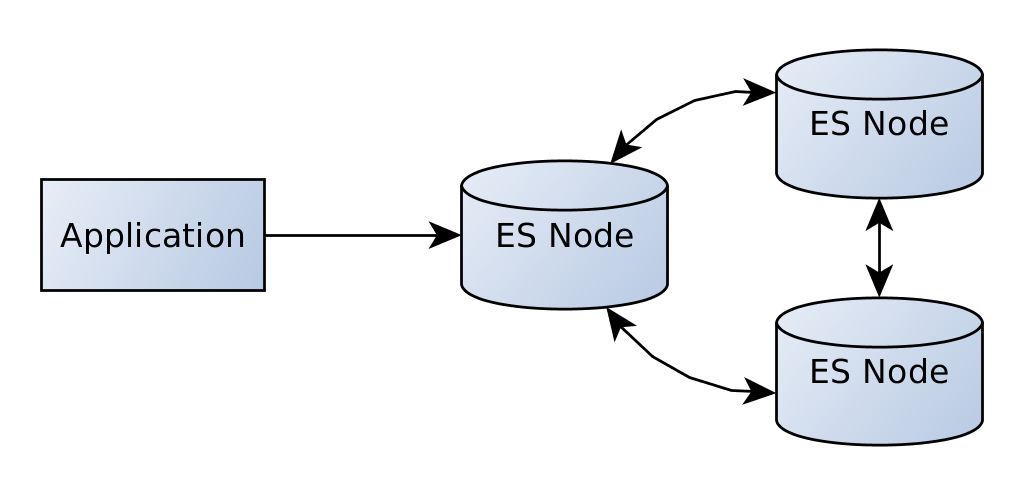
节点形成集群。 我们仍然可以与第一个节点通信,它将所有请求分发到集群的必要节点。 这对我们完全透明。
从一开始就使用Elasticsearch构建集群真的很容易,但是维护生产集群当然会更具挑战性。
现在,我们对Elasticsearch的功能有了基本的了解,让我们看看如何从Java应用程序访问它。
运输客户
传输客户端从一开始就可用,并且是最经常选择的客户端。 从elasticsearch 5.0开始,它具有自己的工件,可以将其集成到您的构建中,例如使用Gradle。
dependencies {
compile group: 'org.elasticsearch.client',
name: 'transport',
version: '5.0.0'
} Elasticsearch的所有功能都可以通过Client接口使用,一个具体的实例是TransportClient ,可以使用Settings对象来实例化它,并且可以具有一个或多个Elasticsearch节点地址。
TransportAddress address =
new InetSocketTransportAddress(
InetAddress.getByName("localhost"), 9300);
Client client = new PreBuiltTransportClient(Settings.EMPTY)
addTransportAddress(address); 然后, client为弹性搜索的不同功能提供方法。 首先,让我们再次搜索。 回想一下我们上面发布的查询的结构。
curl -XPOST "http://localhost:9200/food/dish/_search" -d'
{
"query": {
"bool": {
"must": {
"match": {
"_all": "rice"
}
},
"filter": {
"term": {
"tags.keyword": "chicken"
}
}
}
}
}' 一个bool查询,在其must区域中具有match查询,而在filter区域中具有term查询。
幸运的是,一旦有了这样的查询,就可以轻松地将其转换为Java等效项。
SearchResponse searchResponse = client
.prepareSearch("food")
.setQuery(
boolQuery().
must(matchQuery("_all", "rice")).
filter(termQuery("tags.keyword", "chicken")))
.execute().actionGet();
assertEquals(1, searchResponse.getHits().getTotalHits());
SearchHit hit = searchResponse.getHits().getAt(0);
String food = hit.getSource().get("food").toString(); 我们通过在client上调用prepareSearch来请求SearchSourceBuilder 。 在这里,我们可以使用静态帮助器方法设置查询。 再说一次,这是一个bool查询,在must区域有一个match查询,而在filter区域有一个term查询。
调用execute返回一个Future对象, actionGet是调用的阻塞部分。 SearchResponse表示使用HTTP接口进行搜索时可以看到的相同JSON结构。 然后,菜的来源可作为地图使用。
索引数据时,有不同的选项可用。 一种是使用jsonBuilder创建JSON表示形式。
XContentBuilder builder = jsonBuilder()
.startObject()
.field("food", "Roti Prata")
.array("tags", new String [] {"curry"})
.startObject("favorite")
.field("location", "Tiong Bahru")
.field("price", 2.00)
.endObject()
.endObject();它提供了可用于创建JSON文档结构的不同方法。 然后可以将其用作IndexRequest的源。
IndexResponse resp = client.prepareIndex("food","dish")
.setSource(builder)
.execute()
.actionGet(); 除了使用jsonBuilder还有其他几个可用选项。
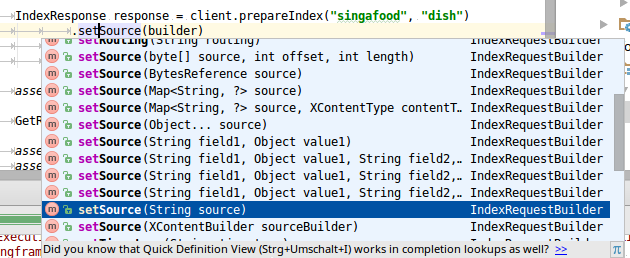
常见的选择是使用Map(一种接受字段名称和值以获取简单结构的便捷方法)或使用传递String的选项,通常将其与Jackson之类的库结合使用以进行序列化。
上面我们已经看到,传输客户端接受一个或多个Elasticsearch节点的地址。 您可能已经注意到,该端口不同于用于HTTP的端口,即9300而不是9200。这是因为客户端不通过http进行通信–它使用传输协议连接到现有集群,该二进制协议也是用于集群中的节点间通信。
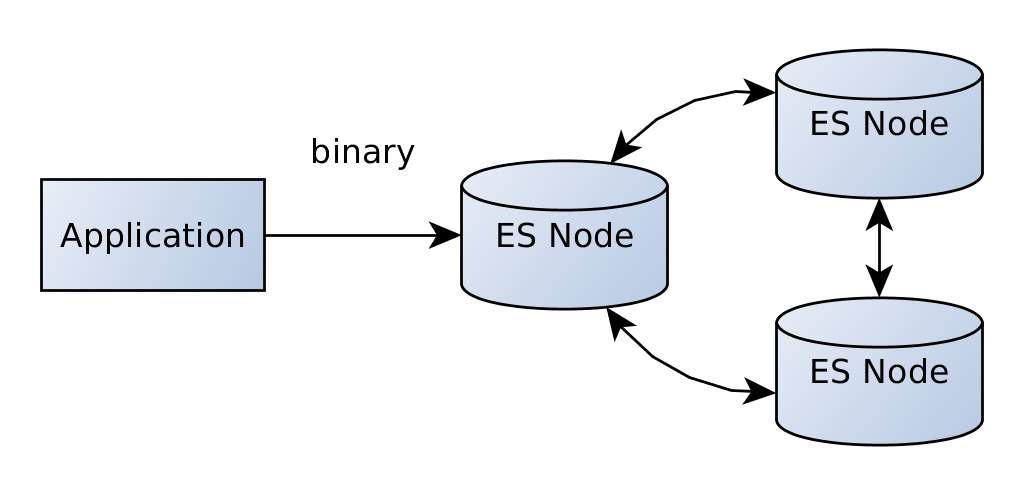
您可能还已经注意到,到目前为止,我们仅在与集群的一个节点通信。 一旦该节点发生故障,我们可能将无法再访问我们的数据。 如果您需要高可用性,则可以启用嗅探选项,该选项可使您的客户端与群集中的多个节点通信。
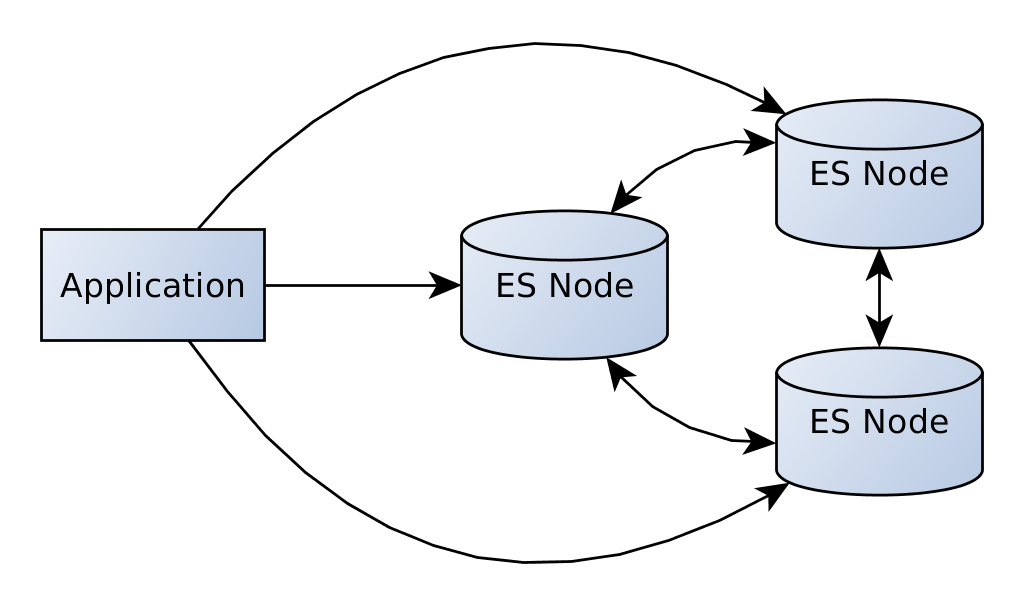
现在,当其中一个节点发生故障时,我们仍然可以使用其他节点访问数据。 创建客户端时,可以通过将client.transport.sniff设置为true来启用该功能。
TransportAddress address =
new InetSocketTransportAddress(
InetAddress.getByName("localhost"), 9300);
Settings settings = Settings.builder()
.put("client.transport.sniff", true)
.build();
Client client = new PreBuiltTransportClient(settings)
addTransportAddress(address);此功能通过使用elasticsearch的管理API之一从已知节点请求集群的当前状态来起作用。 配置后,此操作将在启动过程中以固定的间隔完成,默认情况下每5s进行一次。
嗅探是一项重要功能,即使在节点发生故障时,也可以确保您的应用程序保持正常运行。
使用传输客户端时,您会看到一些明显的好处:随着客户端随服务器一起提供(甚至包括对服务器的依赖关系),您可以确保所有当前API都可以在客户端代码中使用。 通信比HTTP上的JSON更有效,并且支持客户端负载平衡。
另一方面,也存在一些缺点:由于传输协议是内部协议,因此您需要在服务器和客户端上使用兼容的Elasticsearch版本。 同样,这出乎意料之外,这还意味着需要使用类似的JDK版本。 另外,您需要在应用程序中包括所有对Elasticsearch的依赖项。 这可能是一个巨大的问题,尤其是对于较大的现有应用程序。 例如,CMS可能已经发行了某些版本的Lucene。 通常,不可能像这样解决依赖冲突。
幸运的是,有一个解决方案。
RestClient
elasticsearch 5.0引入了一个新客户端,该客户端使用elasticsearch的HTTP API而不是内部协议。 这需要更少的依赖性。 同样,您也不需要太在乎版本-当前的客户端也可以与elasticsearch 2.x一起使用。
但是也有一个缺点–它还没有很多功能。
客户端也可以作为Maven工件使用。
dependencies {
compile group: 'org.elasticsearch.client',
name: 'rest',
version: '5.0.0'
}客户端仅取决于apache httpclient及其依赖项。 这是所有依赖项的Gradle列表。
+--- org.apache.httpcomponents:httpclient:4.5.2
+--- org.apache.httpcomponents:httpcore:4.4.5
+--- org.apache.httpcomponents:httpasyncclient:4.1.2
+--- org.apache.httpcomponents:httpcore-nio:4.4.5
+--- commons-codec:commons-codec:1.10
\--- commons-logging:commons-logging:1.1.3 可以通过传入一个或多个HttpHost来实例化它。
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http"))
.build(); 由于目前没有太多功能,因此大多数JSON都只能以String的形式使用。 这是一个执行match_all查询并使用帮助程序方法将响应转换为String的示例。
HttpEntity entity = new NStringEntity(
"{ \"query\": { \"match_all\": {}}}",
ContentType.APPLICATION_JSON);
// alternative: performRequestAsync
Response response = restClient.performRequest("POST", "/_search", emptyMap(), entity);
String json = toString(response.getEntity());
// ...索引数据也很低。 您只需将包含JSON文档的String发送到端点。 客户端支持使用单独的库进行嗅探。 除了具有更少的依赖关系并且elasticsearch版本不再那么重要的事实之外,操作还有另一个好处:现在可以将集群与应用程序分离,HTTP是与集群通信的唯一协议。
大多数功能直接取决于Apache http客户端。 支持使用基本身份验证,自定义标头和错误处理来设置超时。
目前,尚无查询支持。 如果您能够将elasticsearch依赖项添加到您的应用程序中(这当然会使某些好处再次SearchSourceBuilder ),则可以使用SearchSourceBuilder和相关功能为查询创建字符串。
除了新的RestClient之外,还有另一个具有更多功能的HTTP客户端:社区构建的客户端Jest。
笑话
Jest已经存在很长时间了,它是标准客户端的可行替代方案。 它也可以通过Maven Central获得。
dependencies {
compile group: 'io.searchbox',
name: 'jest',
version: '2.0.0'
} JestClient是允许将请求发送到JestClient的中央接口。 可以使用工厂创建。
JestClientFactory factory = new JestClientFactory();
factory.setHttpClientConfig(new HttpClientConfig
.Builder("http://localhost:9200")
.multiThreaded(true)
.build());
JestClient client = factory.getObject();与RestClient一样,Jest不支持生成查询。 您可以使用String模板创建它们,也可以重用elasticsearch构建器(缺点是必须再次管理所有依赖项)。
可以使用构建器来创建搜索请求。
String query = jsonStringThatMagicallyAppears;
Search search = new Search.Builder(query)
.addIndex("library")
.build();
SearchResult result = client.execute(search);
assertEquals(Integer.valueOf(1), result.getTotal());可以通过遍历Gson对象结构来处理结果,该对象可能变得相当复杂。
JsonObject jsonObject = result.getJsonObject();
JsonObject hitsObj = jsonObject.getAsJsonObject("hits");
JsonArray hits = hitsObj.getAsJsonArray("hits");
JsonObject hit = hits.get(0).getAsJsonObject();
// ... more boring code但这不是您通常与Jest合作的方式。 关于Jest的好处是它直接支持索引和搜索Java Bean。 例如,我们可以代表我们的餐具文件。
public class Dish {
private String food;
private List<String> tags;
private Favorite favorite;
@JestId
private String id;
// ... getters and setters
}然后可以从搜索结果中自动填充此类。
Dish dish = result.getFirstHit(Dish.class).source;
assertEquals("Roti Prata", dish.getFood());当然,bean支持也可以用于索引数据。
通过http访问elasticsearch时,Jest可能是一个很好的选择。 它具有许多有用的功能,例如在索引和搜索时支持bean,以及一种称为节点发现的嗅探功能。 不幸的是,您必须自己创建搜索查询,但RestClient也是如此。
现在我们已经研究了三个客户端,是时候在更高层次上看到抽象了。
Spring Data Elasticsearch
Spring Data项目家族提供了使用通用编程模型访问不同数据存储的权限。 它不会尝试提供所有商店的抽象,每个商店的特产仍然可用。 最令人印象深刻的功能是动态存储库,使您可以使用界面定义查询。 流行的模块是用于访问关系数据库的Spring Data JPA和Spring Data MongoDB。
像所有Spring模块一样,工件可以在Maven Central中使用。
dependencies {
compile group: 'org.springframework.data',
name: 'spring-data-elasticsearch',
version: '2.0.4.RELEASE'
}使用自定义批注将要建立索引的文档表示为Java Bean。
@Document(indexName = "spring_dish")
public class Dish {
@Id
private String id;
private String food;
private List<String> tags;
private Favorite favorite;
// more code
}可以使用不同的注释来定义如何在elasticsearch中存储文档。 在这种情况下,我们仅定义持久化文档时要使用的索引名称,以及用于存储由elasticsearch生成的id的属性。
为了访问文档,可以定义一个键入到餐具类的接口。 有不同的扩展接口, ElasticsearchCrudRepository提供通用的索引和搜索操作。
public interface DishRepository
extends ElasticsearchCrudRepository<Dish, String> {
}该模块提供用于XML配置的名称空间。
<elasticsearch:transport-client id="client" />
<bean name="elasticsearchTemplate"
class="o.s.d.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client"/>
</bean>
<elasticsearch:repositories
base-package="de.fhopf.elasticsearch.springdata" /> transport-client元素实例化了一个传输客户端, ElasticsearchTemplate提供了有关ElasticsearchTemplate的常用操作。 最后, repositories元素指示Spring Data扫描扩展Spring Data接口之一的接口。 它将自动为这些实例创建实例。
然后,您可以将存储库连接到应用程序中,并将其用于存储和查找Dish实例。
Dish mie = new Dish();
mie.setId("hokkien-prawn-mie");
mie.setFood("Hokkien Prawn Mie");
mie.setTags(Arrays.asList("noodles", "prawn"));
repository.save(Arrays.asList(hokkienPrawnMie));
// one line ommited
Iterable<Dish> dishes = repository.findAll();
Dish dish = repository.findOne("hokkien-prawn-mie");通过id检索文档对于搜索引擎而言不是很有趣。 要真正查询文档,您可以在界面中添加遵循特定命名约定的更多方法。
public interface DishRepository
extends ElasticsearchCrudRepository<Dish, String> {
List<Dish> findByFood(String food);
List<Dish> findByTagsAndFavoriteLocation(String tag, String location);
List<Dish> findByFavoritePriceLessThan(Double price);
@Query("{\"query\": {\"match_all\": {}}}")
List<Dish> customFindAll();
} 大多数方法以findBy开头,后跟一个或多个属性。 例如, findByFood将使用给定的参数查询田间food 。 结构化查询也是可能的,在这种情况下,通过添加lessThan 。 这将返回所有价格低于给定价格的菜肴。 最后一种方法使用另一种方法。 它不遵循命名约定,而是使用Query注释。 当然,此查询也可以包含参数的占位符。
总结一下,Spring Data Elasticsearch是在标准客户端之上的一个有趣的抽象。 它在某种程度上与某个Elasticsearch版本相关,当前版本使用2.2版。 有计划使其与5.x兼容,但这可能仍需要一些时间。 有一个拉取请求使用Jest进行通信,但尚不清楚是否以及何时将其合并。 不幸的是,项目中没有很多活动。
结论
我们研究了三个Java客户端和更高层次的抽象Spring Data Elasticsearch。 这些中的每一个都有其优点和缺点,并且没有建议在所有情况下都使用它。 传输客户端具有完整的API支持,但与elasticsearch依赖关系相关。 RestClient是未来,将有一天取代运输客户端。 从功能上讲,它目前处于较低水平。 Jest具有更丰富的API,但是是外部开发的,尽管项目中的提交者有活动,但Jest背后的公司似乎已不存在。 另一方面,Spring Data Elasticsearch更适合已经使用Spring Data且不希望直接与Elasticsearch API联系的开发人员。 它当前与标准客户端的版本绑定,开发活动很少。
翻译自: https://www.javacodegeeks.com/2016/11/java-clients-elasticsearch-transcript.html















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









