





该博客是该系列文章的第一篇,讨论了MapReduce设计模式一书中的一些设计模式,并展示了如何在Apache Spark(R)中实现这些模式。
在编写MapReduce或Spark程序时,考虑执行作业的数据流很有用。 即使Pig,Hive,Apache Drill和Spark数据框使分析数据变得更加容易,在较低级别理解流还是很有用的,就像使用Explain理解查询计划一样有价值。 考虑这一点的一种方法是对模式类型进行分组,这些模式是用于解决常见和常规数据处理问题的模板。 以下是MapReduce书籍中MapReduce模式的类型列表:
- 汇总模式
- 过滤模式
- 数据组织模式
- 联接模式
- 元模式
- 输入和输出模式
在这篇文章中,我们将介绍一种汇总模式,即数值汇总。
数值总结
数值汇总是一种用于计算数据汇总统计值的模式。 目的是按关键字段对记录进行分组,并计算每组的汇总,例如最小值,最大值,中位数。 MapReduce设计模式手册中的下图显示了该模式在MapReduce中的一般执行。
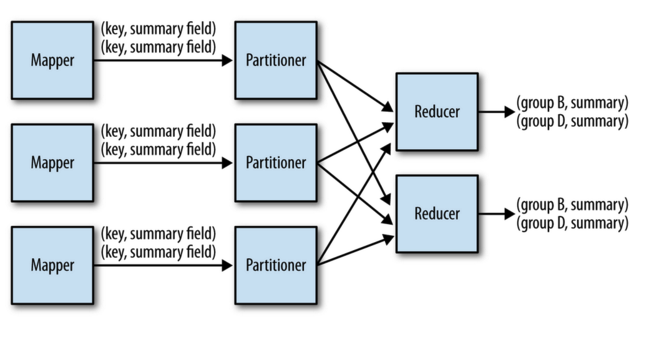
此聚合模式对应于在SQL中使用GROUP BY ,例如:
SELECT MIN(numericalcol1), MAX(numericalcol1),
COUNT(*) FROM table GROUP BY groupcol2;在Pig中,这对应于:
b = GROUP a BY groupcol2;
c = FOREACH b GENERATE group, MIN(a.numericalcol1),
MAX(a.numericalcol1), COUNT_STAR(a);在Spark中,键值对RDD通常用于按键分组以执行聚合,如MapReduce图所示,但是,使用Spark Pair RDDS,您不仅具有Map和Reduce 功能 ,还具有更多功能 。
我们将使用以前在Spark Dataframes上的博客中的数据集介绍一些汇总示例。 数据集是一个.csv文件,由在线拍卖数据组成。 每个拍卖都有一个与其关联的拍卖ID,并且可以有多个出价。 每行代表一个出价。 对于每个出价,我们都有以下信息:

(在代码框中,注释为绿色,输出为蓝色)
下面,我们从ebay.csv文件加载数据,然后使用Scala案例类定义与ebay.csv文件相对应的Auction模式。 然后,将map()转换应用于每个元素以创建Auction对象的AuctionRDD。
// SQLContext entry point for working with structured data
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
// Import Spark SQL data types and Row.
import org.apache.spark.sql._
//define the schema using a case class
case class Auction(auctionid: String, bid: Double, bidtime: Double, bidder: String, bidderrate: Integer, openbid: Double, price: Double, item: String, daystolive: Integer)
// create an RDD of Auction objects
val auctionRDD= sc.textFile("ebay.csv").map(_.split(",")).map(p => Auction(p(0),p(1).toDouble,p(2).toDouble,p(3),p(4).toInt,p(5).toDouble,p(6).toDouble,p(7),p(8).toInt ))下图显示了Spark的一般执行情况,用于计算项目每次竞价的平均出价。
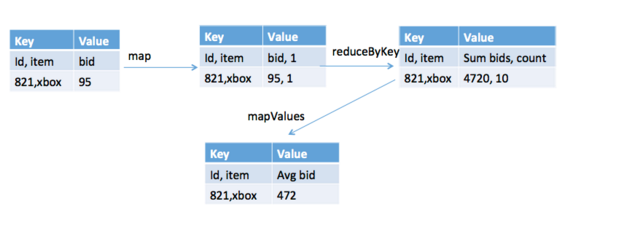
相应的代码如下所示。 首先,创建一个键值对,其中拍卖ID和商品为键,出价金额为1,例如(((id,item),bid amount,1))。 接下来,reduceBykey执行投标金额的总和和投标金额的总和,以获得总投标金额和计数。 mapValues计算平均值,即总出价金额/出价计数。
// create key value pairs of ( (auctionid, item) , (bid, 1))
val apair = auctionRDD.map(auction=>((auction.auctionid,auction.item), (auction.bid, 1)))
// reducebyKey to get the sum of bids and count sum
val atotalcount = apair.reduceByKey((x,y) => (x._1 + y._1, x._2 + y._2))
// get a couple results
atotalcount.take(2)
// Array(((1641062012,cartier),(4723.99,3)), ((2920322392,palm),(3677.96,32)))
// avg = total/count
val avgs = atotalcount.mapValues{ case (total, count) => total.toDouble / count }
// get a couple results
avgs.take(2)
// Array(((1641062012,cartier),1574.6633333333332), ((2920322392,palm),114.93625))
// This could also be written like this
val avgs =auctionRDD.map(auction=>((auction.auctionid,auction.item), (auction.bid, 1))).reduceByKey((x,y) => (x._1 + y._1, x._2 + y._2)).mapValues{ case (total, count) => total.toDouble / count }也可以使用java Math类或spark StatCounter类来计算统计信息,如下所示
import java.lang.Math// Calculate the minimum bid per auction
val amax = apair.reduceByKey(Math.min)
// get a couple results
amax.take(2)
// Array(((1641062012,cartier),1524.99), ((2920322392,palm),1.0))
import org.apache.spark.util.StatCounter
// Calculate statistics on the bid amount per auction
val astats = apair.groupByKey().mapValues(list => StatCounter(list))
// get a result
astats.take(1)
// Array(((1641062012,cartier),(count: 3, mean: 1574.663333, stdev: 35.126723, max: 1600.000000, min: 1524.990000)))Spark DataFrames提供了一种特定于域的语言来进行分布式数据操作,从而使执行聚合更加容易。 此外,DataFrame查询的性能要优于使用PairRDD进行编码,因为它们的执行是由查询优化器自动优化的。 这是一个使用DataFrames来按Auctionid和item获取最低,最高和平均出价的示例:
val auctionDF = auctionRDD.toDF()
// get the max, min, average bid by auctionid and item
auctionDF.groupBy("auctionid", "item").agg($"auctionid",$"item", max("bid"), min("bid"), avg("bid")).show
auctionid item MAX(bid) MIN(bid) AVG(bid)
3016429446 palm 193.0 120.0 167.54900054931642
8211851222 xbox 161.0 51.0 95.98892879486084您还可以使用Spark SQL在使用DataFrames时使用SQL。 本示例按Auctionid和Item获取最高,最低,平均出价。
// register as a temp table inorder to use sql
auctionDF .registerTempTable("auction")
// get the max, min, average bid by auctionid and item
val aStatDF = sqlContext.sql("SELECT auctionid, item, MAX(bid) as maxbid, min(bid) as minbid, avg(bid) as avgbid FROM auction GROUP BY auctionid, item")// show some results
aStatDF.show
auctionid item maxbid minbid avgbid
3016429446 palm 193.0 120.0 167.549
8211851222 xbox 161.0 51.0 95.98892857142857摘要
这是本系列文章的第一部分,该系列文章将讨论使用Spark实现的一些MapReduce设计模式。 讨论非常紧凑,有关模式的更多信息,请参阅MapReduce设计模式手册,有关Spark Pair RDD的更多信息,请参阅“ 学习Spark Key值对”一章。
参考和更多信息
翻译自: https://www.javacodegeeks.com/2015/11/mapreduce-design-patterns-implemented-in-apache-spark.html















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









