





最简单的Apache Lucene查询TermQuery匹配包含指定术语的任何文档,无论该术语出现在每个文档中的何处 。 使用BooleanQuery可以将多个TermQuery组合在一起,并完全控制哪些术语是可选的( SHOULD )和哪些是必需的( MUST )或不应该存在( MUST_NOT ),但是匹配仍然忽略每个术语在。文献。
有时您确实在乎术语的位置,在这种情况下,Lucene具有各种所谓的邻近查询。
最简单的邻近查询是PhraseQuery ,以匹配特定的令牌序列,例如“ Barack Obama”。 如图所示, PhraseQuery是一条简单的线性链:

默认情况下,短语必须精确匹配,但是如果您设置非零倾斜系数 ,则即使标记不完全按顺序排列,只要编辑距离在指定的倾斜范围内,文档仍然可以匹配。 例如,倾斜系数为1的“巴拉克·奥巴马”还将与包含“巴拉克·侯赛因·奥巴马”或“巴拉克·H·奥巴马”的文档匹配。 如下图所示:

现在,图中有多个路径,包括任意 ( * )转换以匹配任意标记。 (注意:虽然图形无法正确表达它,但此查询还会匹配一个文档,该文档的令牌Barack和Obama彼此位于同一位置,这有点奇怪!)
通常,邻近查询在CPU和IO资源上的开销都更大,因为对于每个潜在的文档命中而言,邻近查询必须加载,解码并访问另一个维度(位置)。 也就是说,对于精确的匹配(无斜率),使用通用语法,带状疱疹和ngram来索引索引中的其他“邻近项”可以在某些情况下极大地提高性能,但要以增加索引大小为代价。
MultiPhraseQuery是另一个邻近查询。 它通过在每个位置允许多个令牌来概括PhraseQuery ,例如:
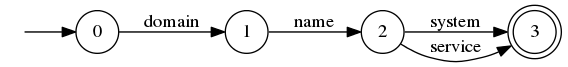
这与包含domain name system或domain name service任何文档匹配。 MultiPhraseQuery还接受坡度因数以允许非精确匹配。
最后,范围查询(例如SpanNearQuery , SpanFirstQuery )走得更远,允许您基于每个子句匹配的位置来构建复杂的复合查询。 它们的独特之处在于您可以任意嵌套它们。 例如,您可以先构建一个与SpanNearQuery = 1的巴拉克·奥巴马(Barack Obama)匹配的SpanNearQuery ,然后再另一个与乔治·布什(George Bush)匹配的对象,然后再创建一个SpanNearQuery ,将这两个都作为子条款,如果它们出现在彼此的10个术语之内,则进行匹配。
TermAutomatonQuery简介
从Lucene 4.10开始,将有一个新的邻近查询,以进一步概括MultiPhraseQuery和span查询:它允许您直接构建一个任意自动机,表达术语必须按顺序出现的方式,包括处理斜率的任何过渡。 这是一个例子:
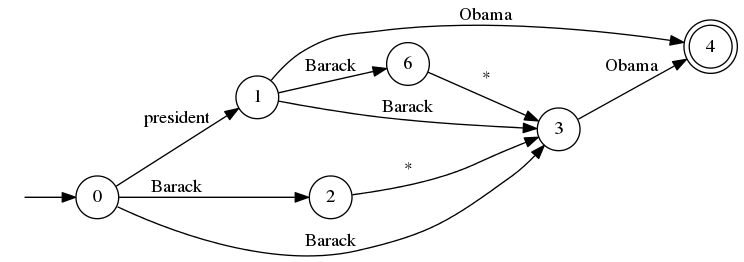
这是一个非常专业的查询,可让您精确控制组成匹配的令牌顺序。 您将按状态和按过渡构建自动机,包括显式添加任何过渡(对不起,尚无QueryParser支持,欢迎使用补丁!)。 完成之后,查询将确定自动机,然后使用与诸如FuzzyQuery之类的查询用于快速术语匹配的相同基础结构(例如CompiledAutomaton ),但将其应用于术语位置而不是术语字节。 该查询像短语查询一样天真的得分,在某些情况下可能不理想。
除了此新查询之外,还有一个简单的实用程序类TokenStreamToTermAutomatonQuery ,该类将任何图TokenStream转换为等效的TermAutomatonQuery 。 这很强大,因为它意味着即使是任意令牌流图也将在搜索时正确表示,并保留一些令牌化程序现在设置的PositionLengthAttribute 。
尽管这意味着您最终可以在查询时正确地应用任意令牌流图同义词,因为索引仍未存储PositionLengthAttribute ,索引时同义词仍不完全正确 。 这就是说,它是简单的建立一个TokenFilter写入位置长度为有效载荷,然后延长新TermAutomatonQuery从有效载荷读取和匹配过程中采用的是长度(补丁欢迎!)。
该查询可能非常慢,因为它假定每个术语都是可选的; 在许多情况下,确定所需的条件(例如上例中的奥巴马)并优化此类情况将很容易。 如果查询是从令牌流派生的,因此它没有周期并且不使用任何过渡,则枚举自动机接受的所有短语可能会更快(Lucene已经具有getFiniteStrings API可以对任何自动机),然后根据这些词组查询构造布尔查询。 这将匹配同一组文档,也将正确保留PositionLengthAttribute ,但是将分配不同的分数。
该代码非常新,并且肯定有一些令人兴奋的错误! 但是对于任何需要精确控制术语在文档中出现位置的应用程序来说,这都是一个不错的开始。
翻译自: https://www.javacodegeeks.com/2014/08/a-new-proximity-query-for-lucene-using-automatons.html















 2722
2722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









