





HashMap<K, V>是每个Java程序中快速,通用且无处不在的数据结构。 首先是一些基础知识。 您可能知道,它使用键的hashCode()和equals()方法在存储桶之间拆分值。 存储桶(箱)的数量应略高于映射中的条目数,以便每个存储桶仅保留很少(最好是一个)值。 当按键查找时,我们很快确定了存储桶(使用hashCode()模数number_of_buckets模),并且我们的商品在固定时间可用。
这应该已经为您所了解。 您可能还知道,哈希冲突对HashMap性能具有灾难性的影响。 当多个hashCode()值最终出现在同一存储桶中时,这些值将放置在临时链接列表中。 在最坏的情况下,当所有键都映射到同一存储桶时,会将哈希映射退化为链表–从O(1)到O(n)查找时间。 让我们首先对HashMap在Java 7(1.7.0_40)和Java 8(1.8.0-b132)中的正常情况下的行为进行基准测试。 为了完全控制hashCode()行为,我们定义了自定义Key类:
class Key implements Comparable<Key> {
private final int value;
Key(int value) {
this.value = value;
}
@Override
public int compareTo(Key o) {
return Integer.compare(this.value, o.value);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass())
return false;
Key key = (Key) o;
return value == key.value;
}
@Override
public int hashCode() {
return value;
}
} Key类行为良好:它覆盖equals()并提供了体面的hashCode() 。 为了避免过多的GC,我缓存了不可变的Key实例,而不是一遍又一遍地创建它们:
public class Keys {
public static final int MAX_KEY = 10_000_000;
private static final Key[] KEYS_CACHE = new Key[MAX_KEY];
static {
for (int i = 0; i < MAX_KEY; ++i) {
KEYS_CACHE[i] = new Key(i);
}
}
public static Key of(int value) {
return KEYS_CACHE[value];
}
} 现在我们准备进行一些实验。 我们的基准测试将使用连续键空间简单地创建不同大小(10的幂,从1到1百万)的HashMap 。 在基准测试本身中,我们将根据键查找值并测量所需的时间,具体取决于HashMap大小:
import com.google.caliper.Param;
import com.google.caliper.Runner;
import com.google.caliper.SimpleBenchmark;
public class MapBenchmark extends SimpleBenchmark {
private HashMap<Key, Integer> map;
@Param
private int mapSize;
@Override
protected void setUp() throws Exception {
map = new HashMap<>(mapSize);
for (int i = 0; i < mapSize; ++i) {
map.put(Keys.of(i), i);
}
}
public void timeMapGet(int reps) {
for (int i = 0; i < reps; i++) {
map.get(Keys.of(i % mapSize));
}
}
} 结果确认HashMap.get()确实是O(1):
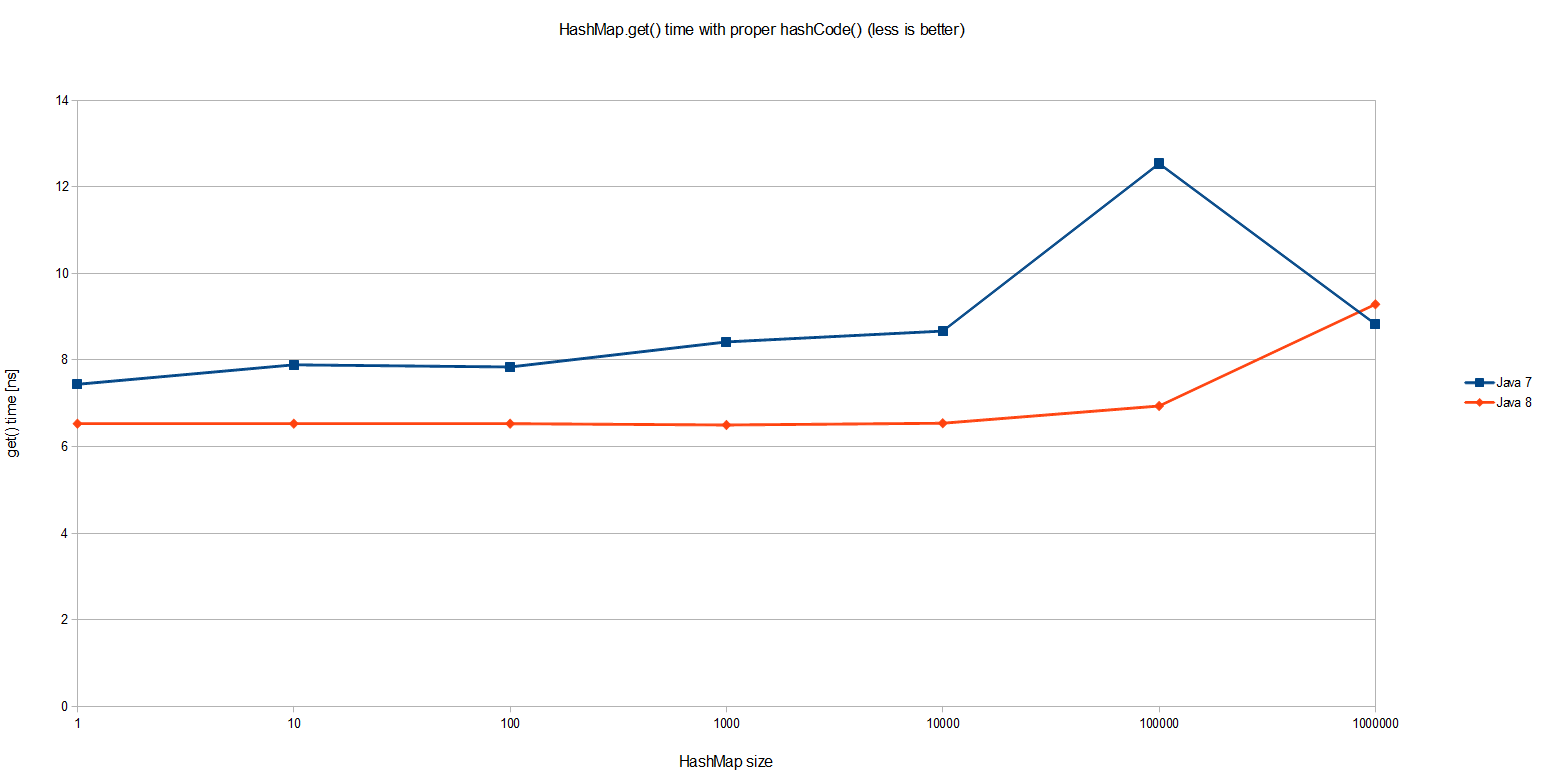
有趣的是,在简单的HashMap.get() Java 8平均比Java 7快20%。 整体性能同样令人感兴趣:即使在HashMap有100万个条目,一次查找所用的时间也不到10纳秒,这意味着我的机器上大约有20个CPU周期* 。 令人印象深刻! 但这不是我们要进行基准测试的结果。
假设我们有一个非常差的映射键,它总是返回相同的值。 这是最糟糕的情况,完全HashMap使用HashMap :
class Key implements Comparable<Key> {
//...
@Override
public int hashCode() {
return 0;
}
}我使用了完全相同的基准来查看它在各种地图尺寸下的行为(注意这是对数对数比例):
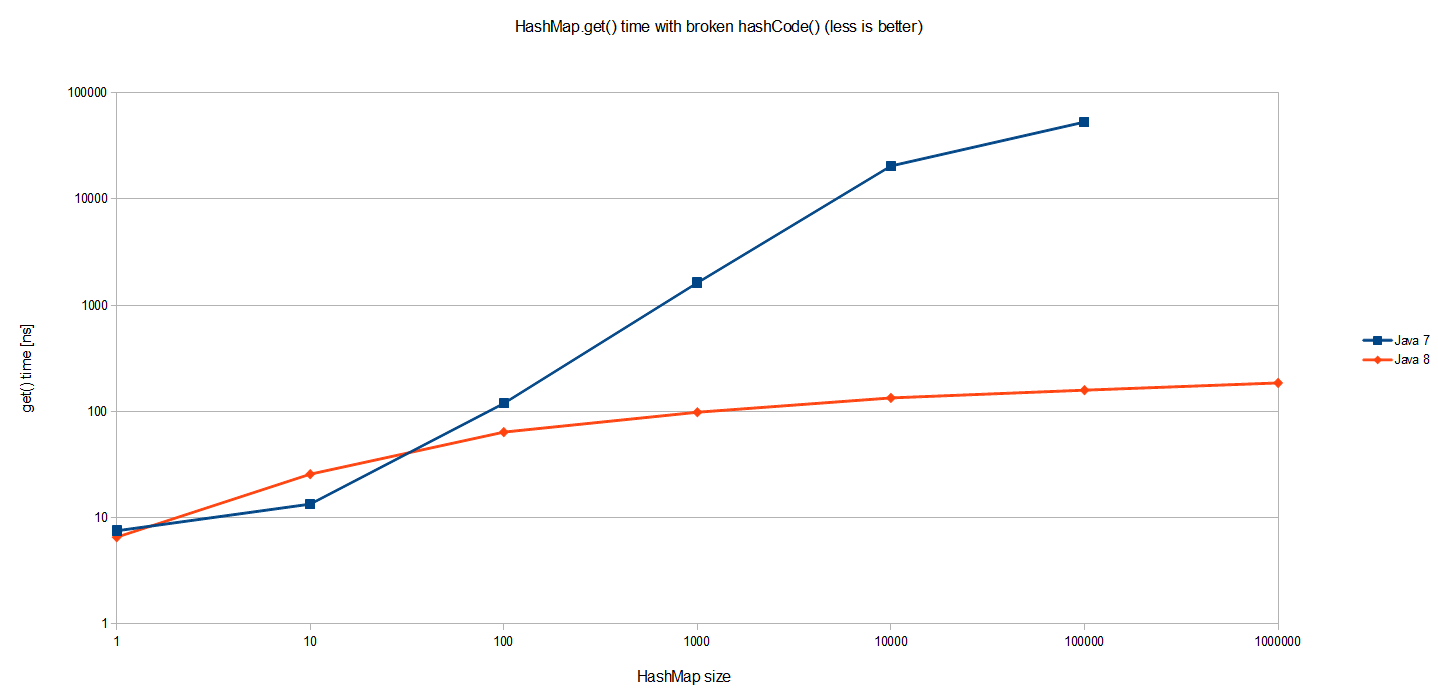
预计Java 7的结果。 HashMap.get()的成本与HashMap本身的大小成比例地增长。 由于所有条目都在一个巨大的链接列表中的同一存储桶中,因此查找一个条目平均需要遍历该列表的一半(大小为n)。 因此,O(n)复杂度如图所示。
但是Java 8的性能要好得多! 这是一个对数标度,因此我们实际上在谈论几个数量级的更好。 在灾难性哈希冲突的情况下,在JDK 8上执行的相同基准会产生O(logn)最坏情况的性能,如将JDK 8单独以对数线性比例可视化,则可以更好地看到:
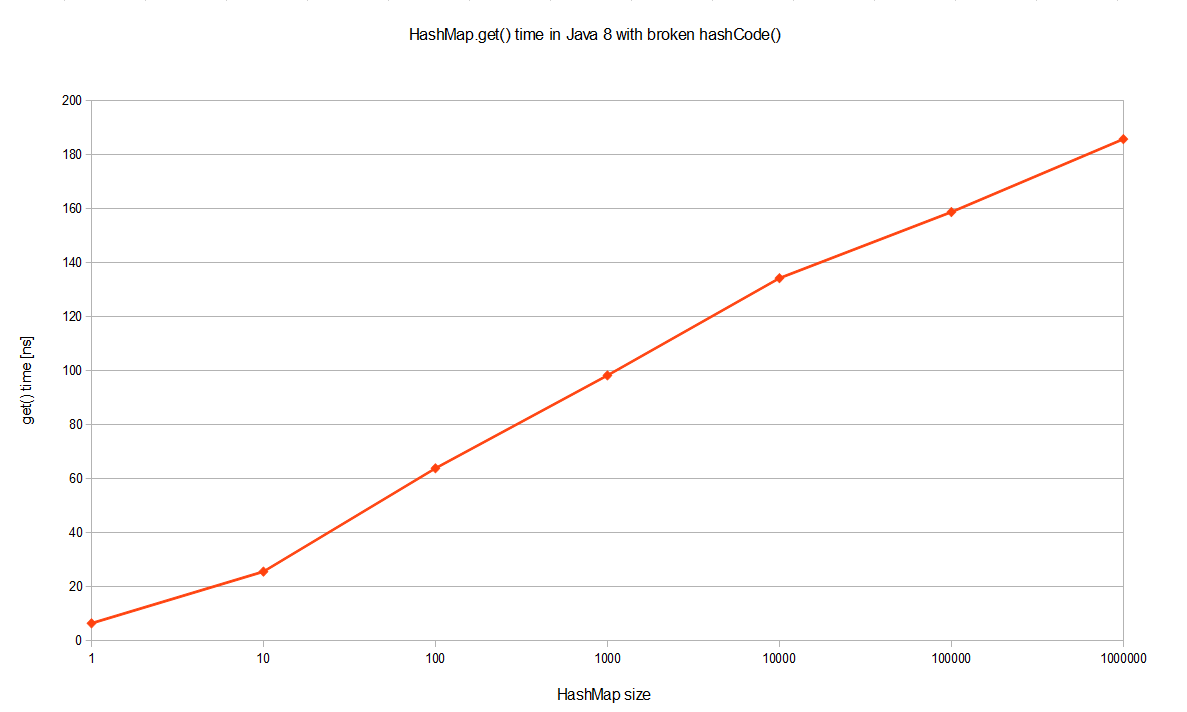
即使使用big-O表示法,如此巨大的性能改进背后的原因是什么? 好,在JEP-180中描述了此优化。 基本上,当存储桶过大时(当前: TREEIFY_THRESHOLD = 8 ), HashMap用树形图的临时实现动态替换它。 这样一来,我们不必感到悲观的O(n),而获得更好的O(logn)。 它是如何工作的? 好吧,以前具有冲突键的条目只是简单地附加到链表中,而后又需要遍历。 现在, HashMap使用哈希码作为分支变量,将列表提升为二叉树。 如果两个散列不同,但最终在同一个存储桶中,则认为一个散列较大并向右移动。 如果哈希值相等(如本例所示),则HashMap希望键是Comparable ,以便它可以建立一些顺序。 这不是HashMap密钥的要求,但显然是一种好习惯。 如果密钥不具有可比性,那么在发生大量哈希冲突的情况下,不要指望任何性能提高。
为什么所有这些都那么重要? 知道我们使用的哈希算法的恶意软件可能会处理数千个请求,这些请求将导致大量的哈希冲突。 重复访问此类密钥将严重影响服务器性能,从而有效地导致拒绝服务攻击。 在JDK 8中,从O(n)到O(logn)的惊人跳跃将阻止这种攻击媒介,也使性能更具预测性。 我希望这将最终说服您的老板升级。
*在Intel Core i7-3635QM @ 2.4 GHz,8 GiB RAM和SSD驱动器上执行的基准,在64位Windows 8.1和默认JVM设置上运行。
翻译自: https://www.javacodegeeks.com/2014/04/hashmap-performance-improvements-in-java-8.html















 4680
4680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









