





这篇文章涵盖了如何使用ElasticSearch-Hadoop从Hadoop系统读取数据并在ElasticSearch中对其进行索引。 它涵盖的功能是在最近n天中为每个客户的产品浏览量计数和热门搜索查询编制索引。 分析的数据可以进一步在网站上使用,以显示最近浏览过的客户,产品浏览次数和热门搜索查询字符串。
继续之前的文章
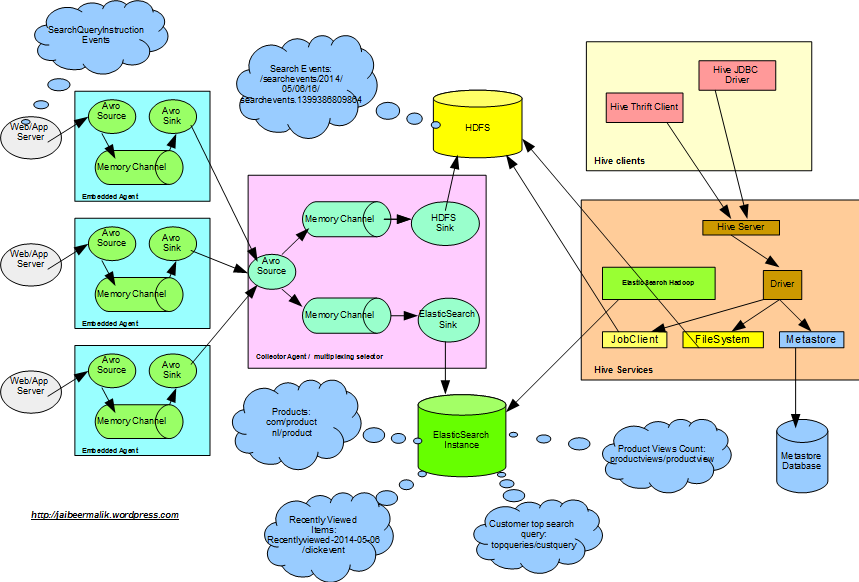
我们已经有使用Flume收集并存储在Hadoop HDFS和ElasticSearch中的客户搜索点击数据,以及如何使用Hive分析相同数据并生成统计数据。 在这里,我们将进一步了解如何使用分析后的数据来增强网站上的客户体验并使之与最终客户相关。
最近浏览过的商品
我们已经在第一部分中介绍了如何使用水槽ElasticSearch接收器将最近查看的商品目录索引到ElasticSearch实例,以及如何使用数据为客户显示实时点击的商品。
弹性搜索-Hadoop
Elasticsearch for Apache Hadoop允许Hadoop作业通过小型库和易于设置的方式与ElasticSearch进行交互。
Elasticsearch-hadoop-hive,允许使用Hive访问ElasticSearch。 正如上一篇文章中所分享的那样,我们在Hive表中提取了产品视图计数以及客户排名最高的搜索查询数据。 我们将读取相同的数据并将其索引到ElasticSearch,以便将其用于网站上的显示目的。
产品视图计数功能
采取一个方案来显示客户在最近n天中的每个产品总观看次数。 为了获得更好的用户体验,您可以使用相同的功能向最终客户显示其他客户对同一产品的看法。
蜂房数据用于产品视图
从配置单元表中选择示例数据:
# search.search_productviews : id, productid, viewcount 61, 61, 15 48, 48, 8 16, 16, 40 85, 85, 7
产品视图计数索引
创建Hive外部表“ search_productviews_to_es”以将数据索引到ElasticSearch实例。
Use search;
DROP TABLE IF EXISTS search_productviews_to_es;
CREATE EXTERNAL TABLE search_productviews_to_es (id STRING, productid BIGINT, viewcount INT) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'productviews/productview', 'es.nodes' = 'localhost', 'es.port' = '9210', 'es.input.json' = 'false', 'es.write.operation' = 'index', 'es.mapping.id' = 'id', 'es.index.auto.create' = 'yes');
INSERT OVERWRITE TABLE search_productviews_to_es SELECT qcust.id, qcust.productid, qcust.viewcount FROM search_productviews qcust;
- 创建外部表search_productviews_to_es指向ES实例
- 使用的ElasticSearch实例配置为localhost:9210
- 索引“ productviews”和文档类型“ productview”将用于索引数据
- 如果索引和mappin不存在,则会自动创建
- 如果基于ID字段已经存在,则插入覆盖将覆盖数据。
- 通过从另一个存储分析/统计数据的配置表“ search_productviews”中选择数据来插入数据。
执行Java中的Hive脚本以索引产品视图数据HiveSearchClicksServiceImpl.java
Collection<HiveScript> scripts = new ArrayList<>();
HiveScript script = new HiveScript(new ClassPathResource("hive/load-search_productviews_to_es.q"));
scripts.add(script);
hiveRunner.setScripts(scripts);
hiveRunner.call();
productviews索引样本数据
ElasticSearch索引中的样本数据存储如下:
{id=48, productid=48, viewcount=10}
{id=49, productid=49, viewcount=20}
{id=5, productid=5, viewcount=18}
{id=6, productid=6, viewcount=9}
客户热门搜索查询字符串功能
以一种情况为例,您可能希望显示单个客户或网站上所有客户的热门搜索查询字符串。 您可以使用它来显示网站上的热门搜索查询云。
Hive Data用于客户热门搜索查询
从配置单元表中选择示例数据:
# search.search_customerquery : id, querystring, count, customerid 61_queryString59, queryString59, 5, 61 298_queryString48, queryString48, 3, 298 440_queryString16, queryString16, 1, 440 47_queryString85, queryString85, 1, 47
客户热门搜索查询索引
创建Hive外部表“ search_customerquery_to_es”以将数据索引到ElasticSearch实例。
Use search;
DROP TABLE IF EXISTS search_customerquery_to_es;
CREATE EXTERNAL TABLE search_customerquery_to_es (id String, customerid BIGINT, querystring String, querycount INT) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'topqueries/custquery', 'es.nodes' = 'localhost', 'es.port' = '9210', 'es.input.json' = 'false', 'es.write.operation' = 'index', 'es.mapping.id' = 'id', 'es.index.auto.create' = 'yes');
INSERT OVERWRITE TABLE search_customerquery_to_es SELECT qcust.id, qcust.customerid, qcust.queryString, qcust.querycount FROM search_customerquery qcust;
- 创建外部表search_customerquery_to_es指向ES实例
- 使用的ElasticSearch实例配置为localhost:9210
- 索引“ topqueries”和文档类型“ custquery”将用于索引数据
- 如果索引和mappin不存在,则会自动创建
- 如果基于ID字段已经存在,则插入覆盖将覆盖数据。
- 通过从另一个存储分析/统计数据的配置单元表“ search_customerquery”中选择数据来插入数据。
在Java中执行Hive脚本以索引数据HiveSearchClicksServiceImpl.java
Collection<HiveScript> scripts = new ArrayList<>();
HiveScript script = new HiveScript(new ClassPathResource("hive/load-search_customerquery_to_es.q"));
scripts.add(script);
hiveRunner.setScripts(scripts);
hiveRunner.call();
topqueries索引样本数据
ElasticSearch实例上的topqueries索引数据如下所示:
{id=474_queryString95, querystring=queryString95, querycount=10, customerid=474}
{id=482_queryString43, querystring=queryString43, querycount=5, customerid=482}
{id=482_queryString64, querystring=queryString64, querycount=7, customerid=482}
{id=483_queryString6, querystring=queryString6, querycount=2, customerid=483}
{id=487_queryString86, querystring=queryString86, querycount=111, customerid=487}
{id=494_queryString67, querystring=queryString67, querycount=1, customerid=494}
上面描述的功能只是示例功能,当然需要扩展以映射到特定的业务场景。 这可能涵盖在网站上向客户显示搜索查询云或进一步进行商务智能分析的业务场景。
Spring数据
还包括用于测试目的的Spring ElasticSearch来创建ESRepository以对总记录进行计数并删除All。
检查服务以获取详细信息ElasticSearchRepoServiceImpl.java
产品总观看次数:
@Document(indexName = "productviews", type = "productview", indexStoreType = "fs", shards = 1, replicas = 0, refreshInterval = "-1")
public class ProductView {
@Id
private String id;
@Version
private Long version;
private Long productId;
private int viewCount;
...
...
}
public interface ProductViewElasticsearchRepository extends ElasticsearchCrudRepository<ProductView, String> { }
long count = productViewElasticsearchRepository.count();
客户热门搜索查询:
@Document(indexName = "topqueries", type = "custquery", indexStoreType = "fs", shards = 1, replicas = 0, refreshInterval = "-1")
public class CustomerTopQuery {
@Id
private String id;
@Version
private Long version;
private Long customerId;
private String queryString;
private int count;
...
...
}
public interface TopQueryElasticsearchRepository extends ElasticsearchCrudRepository<CustomerTopQuery, String> { }
long count = topQueryElasticsearchRepository.count();
在以后的文章中,我们将介绍使用计划的作业进一步分析数据,
- 使用Oozie计划针对配置单元分区进行协调的作业,并将作业捆绑以将数据索引到ElasticSearch。
- 使用Pig来计算唯一客户总数等















 2078
2078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









