





到目前为止,JDK 7已很好地掌握在开发人员手中,并且大多数人都听说过ForkJoin,但是没有多少人有时间或机会去尝试它。
它引起了,并且可能仍然引起一些混乱,与普通线程池有什么不同。 [1]
我在本文中的目标是通过一个代码示例来呈现一个更详细,但仍然简单的ForkJoin使用示例。
我计时并测量串行 , 线程池和ForkJoin方法的性能 。
这是github的前期内容: https : //github.com/fbunau/javaadvent-forkjoin
实际问题
想象一下,我们的系统中有某种组件可以在每毫秒时间内保持股票的最新价格。
这可以作为整数数组保存在内存中。 (如果我们以bps为单位)
该组件的客户进行如下查询:价格最低的是time1和time2之间的时间点?
这可以是自动算法,也可以只是GUI中进行矩形选择的人。
![]()
示例图像中有7个查询
让我们还想象一下,我们从一个Task中批处理的客户端中获得了许多这样的查询。
可以将它们分批处理,以减少网络流量和往返时间。
我们有组件可能获得的不同大小的任务,最多10个查询(带有GUI的人),最多100个,..最多1 000 0000个(某种自动化算法)。 我们的组件有很多这样的客户,每个客户都会产生不同大小的任务。 请参阅Task.TaskType
核心问题与解决方案
我们必须解决的核心问题是RMQ问题。 这是维基百科[2] :
“鉴于从一组有序集合(例如数字)中获取的对象数组,从i到j的范围最小查询(或RMQ)要求最小元素在子数组A[i, j] 。”
“例如,当A = [0, 5, 2, 5, 4, 3, 1, 6, 3]时,则A[3, 8] = [2, 5, 4, 3, 1, 6]的范围最小查询的答案A[3, 8] = [2, 5, 4, 3, 1, 6]是7 ,因为A[7] = 1 ”
存在一种用于解决该问题的有效数据结构,称为“细分树”。
我不会对此进行详细介绍,因为这篇经典的Topcoder文章[3]对此进行了很好的介绍。 对于ForkJoin示例,这本身并不重要,我选择它是因为它比简单的总和更有趣,并且其本质是基于fork-join的精神。 它划分要计算的任务,然后加入结果!
数据结构具有O(n)初始化时间和O(log N)查询时间,其中N是每个时间单位值数组的价格中的元素数量。
因此,任务T包含M要进行的查询。
在学术计算机科学方法中,您只是说我们将使用这种高效的数据结构处理每个任务,而复杂性将是:
![]()
您再没有比这更有效率的了! 是的,在理论上是冯·诺依曼机器上,但是您可以在实践中。
一个容易引起混淆的是,因为O(n/4) == O(n) ,所以在编写程序时,常数因子不计算在内,但确实如此!
停下来想一想,等待10或40分钟/小时/年是否一样?
平行进行
因此,考虑要解决的问题,我们如何使其更快? 由于现在每个计算设备都有更多的计算核心,因此让我们充分利用它们并立即执行更多操作。
我们可以使用Fork Join框架轻松地做到这一点。
我最初很想尝试一下RMQ数据结构并并行执行它的操作。 我攻击了本来已经是log N的东西。但这是一个很大的失败,对于调度程序来说,管理如此短时间的逻辑开销太大。
答案是最终攻击M_i恒定因子。
线程池
在介绍如何应用ForkJoin解决方案之前,让我们想象一下如何应用线程池。 请参阅: TaskProcessorPool.java
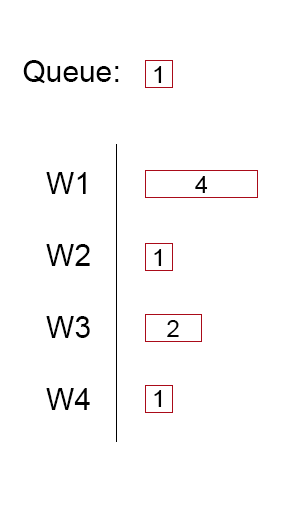
我们可以有4名工作人员的池,当我们有一个任务要做时,我们将其添加到队列中。 一旦有工作人员可用,它将从队列的开头检索待执行的任务,然后执行该任务。
尽管这对于具有相同大小的任务是很好的,并且大小相对中等且可预测,但是当要执行的任务大小不同时,就会遇到问题。 一名工人可能会因长期运行的任务而烦恼,而其他工人则无所事事。
在此图像中,如果不将更多任务添加到队列中,则线程池将在4个时间单位内完成16个可能的工作单位中的9个(效率为56%)
叉连接
当您位于问题域中时,可以将要解决的任务拆分为较小的任务,因此前叉联接很有用。
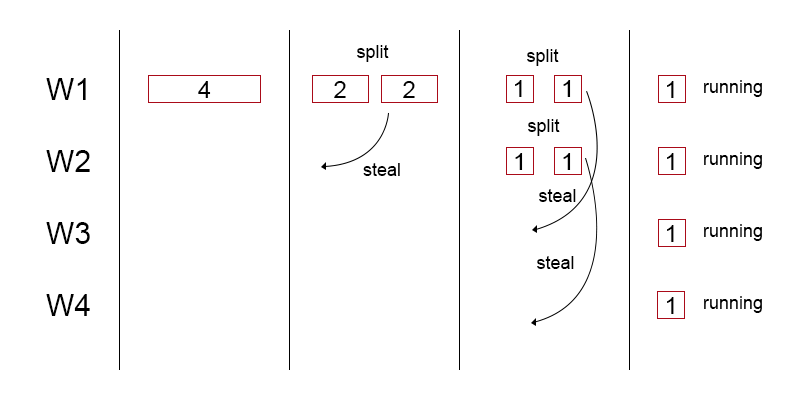
fork-join池的特殊之处在于它是一个窃取工作的线程池。
每个工作线程都维护任务的本地出队。 在执行新任务时,可以执行以下任一操作:
- 将任务拆分为较小的任务
- 如果任务足够小,则执行任务
当一个线程的出队中没有本地线程时,它将“窃取”,从另一个随机线程的队列后面弹出任务,并将其放入自己的线程中。 此任务尚未拆分的可能性很高。 因此,他将有很多工作要做。
与线程池相比,它们可以将现有任务拆分为较小的线程,而不是其他线程等待某些新工作,并帮助另一个线程处理较大的任务。
这是Doug Lea的原始论文,提供了更详细的解释: http : //gee.cs.oswego.edu/dl/papers/fj.pdf
回到我们的示例中,可以将一大批操作分为几批较少数量的操作。 请参阅: TaskProcessorFJ.java
大多数问题都具有像这样的线性运算,它不一定是特殊的并行问题,对此我们需要应用专门的并行算法来利用处理器上的核心。
你分多少钱? 您拆分任务,直到达到通常不再有意义的阈值为止。 例子:(拆分+获得工作的线程+上下文切换比实际执行任务更为重要)
对于大型XXL,我们必须执行1000000个查询操作。 我们可以将其分为2 500000个操作任务,并并行执行。 500000仍然很大吗? 是的,我们可以进一步拆分。 我选择了一组10000个操作作为阈值,在该阈值下没有任何拆分用途,我们可以在当前线程上执行它们。
Fork join并不会预先拆分所有任务,而是通过它进行工作。
绩效结果
在干净重启后,我对i5-2500 CPU @ 3.30GHz上具有4核/ 4线程的i5-2500 CPU的每种处理器实现进行了4次迭代。
结果如下:
Doing 4 runs for each of the 3 processors. Pls wait ...
TaskProcessorSimple: 7963
TaskProcessorSimple: 7757
TaskProcessorSimple: 7748
TaskProcessorSimple: 7744
TaskProcessorPool: 3933
TaskProcessorPool: 2906
TaskProcessorPool: 4477
TaskProcessorPool: 4160
TaskProcessorFJ: 2498
TaskProcessorFJ: 2498
TaskProcessorFJ: 2524
TaskProcessorFJ: 2511
Test completed.结论
即使您选择了正确的最佳数据结构,它也不会很快,直到您使用所有的资源。 即利用所有核心
在某些问题域中,ForkJoin绝对是对线程池的改进,值得探索在哪里可以应用它,我们将看到越来越多的并行代码。
您今天可以购买这种处理器 ,即12核/ 24线程。 现在,我们只需要编写软件来利用我们拥有的,将在将来获得的出色硬件即可。
代码在这里: https : //github.com/fbunau/javaadvent-forkjoin如果您想使用它的话
感谢您的宝贵时间,如果发现任何错误或需要添加的内容,请删除一些评论。
翻译自: https://www.javacodegeeks.com/2013/12/applying-forkjoin-from-optimal-to-fast.html















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









