





Apache Mahout是一个“可扩展的机器学习库”,其中包含各种单节点和分布式推荐算法的实现。 在我的上一篇博客文章中, 我描述了如何在单个节点上实现在线推荐系统来处理数据。 如果数据太大而无法放入内存(> 100M首选项数据点)怎么办? 然后我们别无选择,只能看一下Mahout的分布式推荐器实现!
分布式推荐器基于Apache Hadoop。 这是一项需要输入用户偏好列表,计算项目共现矩阵并为每个用户输出前K个建议的工作。 有关此博客如何工作以及如何在本地运行的介绍性博客,请参见此博客文章 。
我们当然可以在自定义的Hadoop群集上运行此作业,但是仅使用预先配置的作业(如EMR)会更快(且痛苦更少)。 但是,有一个小问题。 EMR上可用的最新Hadoop版本是1.0.3,其中包含Apache Lucene 2.9.4的jar。 但是,推荐器作业取决于Lucene 4.3.0,这将导致以下漂亮的堆栈跟踪:
2013-10-04 11:05:03,921 FATAL org.apache.hadoop.mapred.Child (main): Error running child : java.lang.NoSuchMethodError: org.apache.lucene.util.PriorityQueue.<init>(I)V
at org.apache.mahout.math.hadoop.similarity.cooccurrence.TopElementsQueue.<init>(TopElementsQueue.java:33)
at org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$UnsymmetrifyMapper.
map(RowSimilarityJob.java:405)
at org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$UnsymmetrifyMapper.
map(RowSimilarityJob.java:389)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:771)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:375)
at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1132)
at org.apache.hadoop.mapred.Child.main(Child.java:249)如何解决呢? 好吧,我们“只是”需要在EMR Hadoop安装中更新Lucene。 我们可以为此使用引导操作 。 具体步骤如下:
- 下载lucene-4.3.0.tgz(例如从此处下载)并将其上传到S3存储桶中; 将文件公开。
- 将该脚本也上传到存储桶中; 称之为例如
update-lucene.sh:#!/bin/bash cd /home/hadoop wget https://s3.amazonaws.com/bucket_name/bucket_path/lucene-4.3.0.tgz tar -xzf lucene-4.3.0.tgz cd lib rm lucene-*.jar cd .. cd lucene-4.3.0 find . | grep lucene- | grep jar$ | xargs -I {} cp {} ../lib该脚本将在Hadoop节点上运行,并将更新Lucene版本。 确保更改脚本并输入正确的存储桶名称和存储桶路径,以使其指向公共Lucene存档。
- mahout-core-0.8-job.jar到存储桶
- 最后,我们需要将输入数据上传到S3。 输出数据也将保存在S3上。
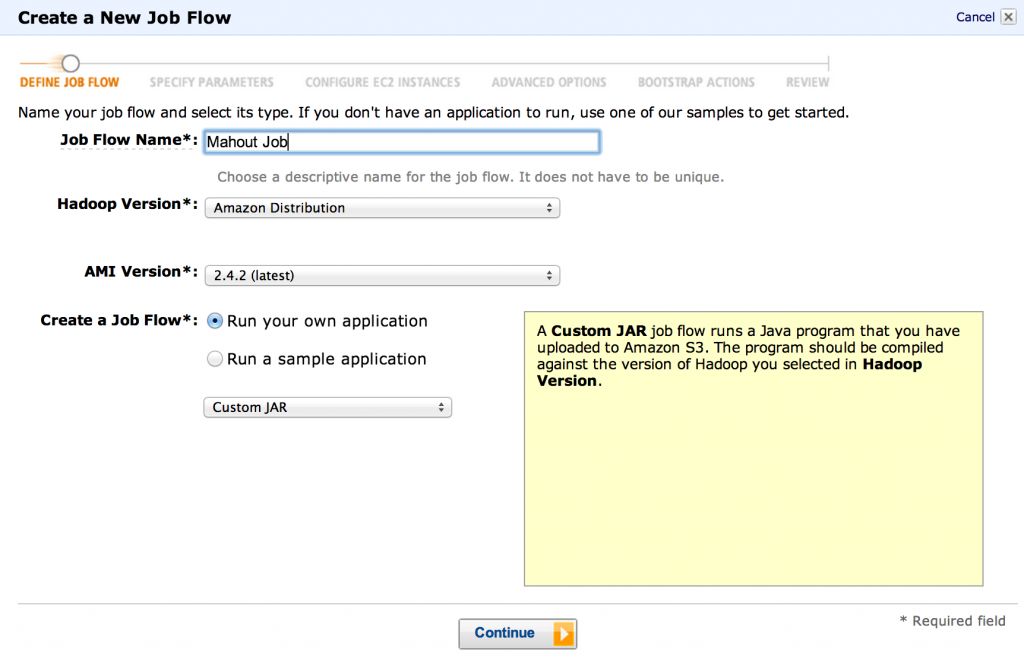
- 现在,我们可以开始设置EMR作业流程。 转到Amazon控制台上的EMR页面,并开始创建新的工作流程。 我们将使用“ Amazon Distribution” Hadoop版本,并使用“ Custom JAR”作为作业类型。
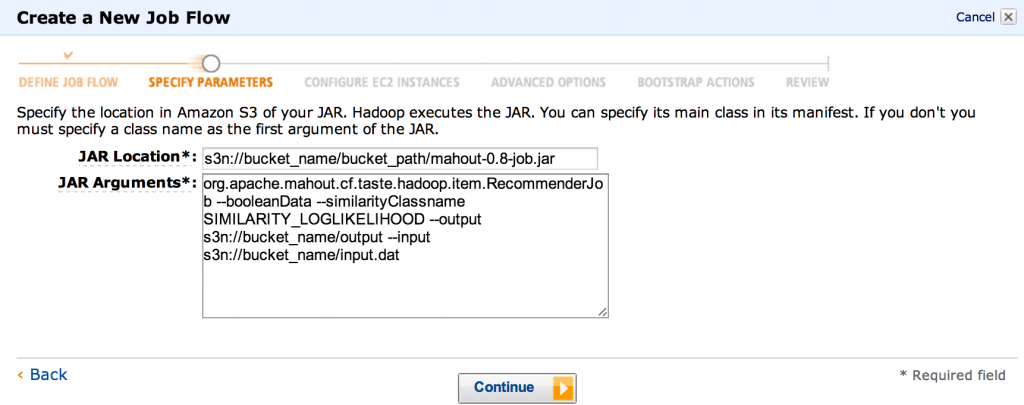
- “ JAR位置”必须指向我们上载Mahout jar的位置,例如
s3n://bucket_name/bucket_path/mahout-0.8-job.jar(请确保将其更改为指向真实的存储桶!)。 至于jar参数,我们将运行RecommenderJob并使用对数似然性:org.apache.mahout.cf.taste.hadoop.item.RecommenderJob --booleanData --similarityClassname SIMILARITY_LOGLIKELIHOOD --output s3n://bucket_name/output --input s3n://bucket_name/input.dat这也是指定S3上输入数据的位置以及应将输出写入何处的地方。
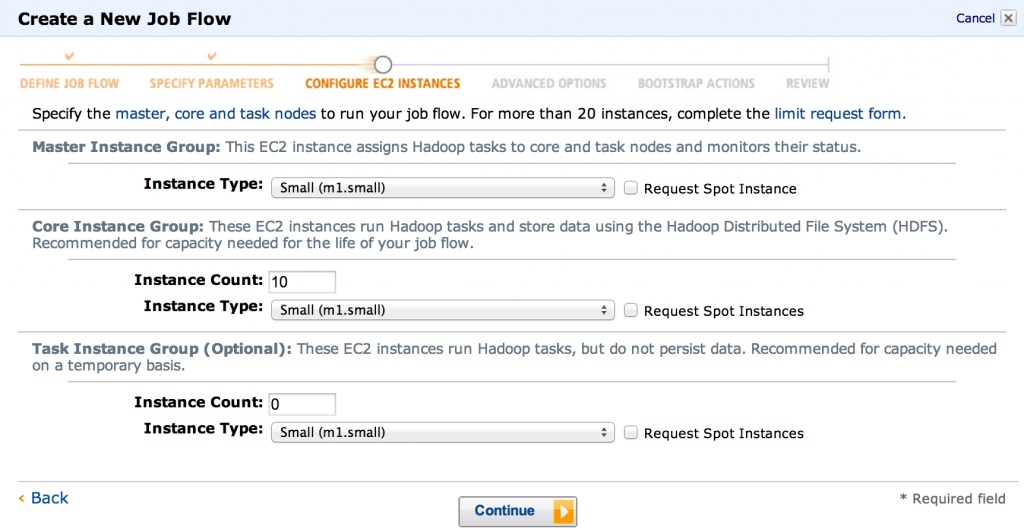
- 然后,我们可以选择要使用的计算机数量。 当然,这取决于输入数据的大小以及所需的结果速度。 这里主要要更改的是“核心实例组”计数。 2是测试的合理默认值。
- 我们可以保持高级选项不变
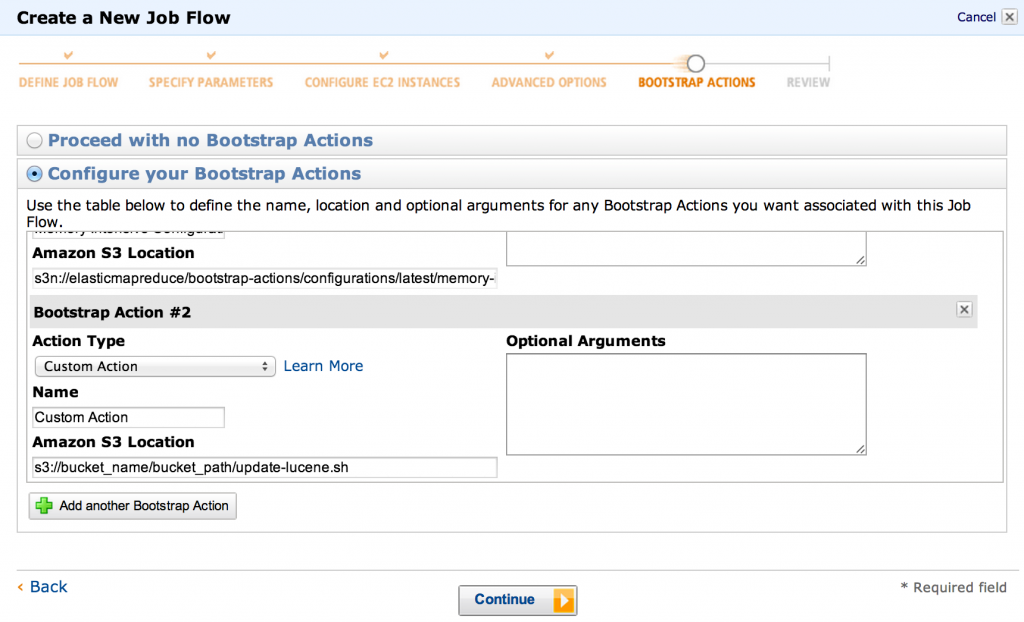
- 现在我们进入更重要的步骤之一:设置引导程序动作。 我们需要设置两个:
- 内存密集型配置(否则您会很快看到一个OOM)
- 我们的自定义update-lucene操作(路径应指向S3,例如
s3://bucket_name/bucket_path/update-lucene.sh)
就是这样! 现在,您可以创建并运行作业流程,在几分钟/几小时/几天之后,您将在S3上等待结果。















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









