





不久前,我发布了如何使用CLI设置EMR群集的信息。 在本文中,我将展示如何使用适用于AWS的Java SDK来设置集群。 展示如何使用Java AWS开发工具包执行此操作的最佳方法是展示完整的示例,因此,让我们开始吧。
- 设置一个新的Maven项目
为此,我创建了一个新的默认Maven项目。 您可以运行该项目中的主类来启动EMR集群并执行我在本文中创建的MapReduce作业:
package net.pascalalma.aws.emr;
import com.amazonaws.AmazonServiceException;
import com.amazonaws.auth.AWSCredentials;
import com.amazonaws.auth.PropertiesCredentials;
import com.amazonaws.regions.Region;
import com.amazonaws.regions.Regions;
import com.amazonaws.services.ec2.model.InstanceType;
import com.amazonaws.services.elasticmapreduce.AmazonElasticMapReduceClient;
import com.amazonaws.services.elasticmapreduce.model.*;
import com.amazonaws.services.elasticmapreduce.util.StepFactory;
import com.amazonaws.services.s3.AmazonS3;
import com.amazonaws.services.s3.AmazonS3Client;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import java.util.UUID;
/**
* Created with IntelliJ IDEA.
* User: pascal
* Date: 22-07-13
* Time: 20:45
*/
public class MyClient {
private static final String HADOOP_VERSION = "1.0.3";
private static final int INSTANCE_COUNT = 1;
private static final String INSTANCE_TYPE = InstanceType.M1Small.toString();
private static final UUID RANDOM_UUID = UUID.randomUUID();
private static final String FLOW_NAME = "dictionary-" + RANDOM_UUID.toString();
private static final String BUCKET_NAME = "map-reduce-intro";
private static final String S3N_HADOOP_JAR =
"s3n://" + BUCKET_NAME + "/job/MapReduce-1.0-SNAPSHOT.jar";
private static final String S3N_LOG_URI = "s3n://" + BUCKET_NAME + "/log/";
private static final String[] JOB_ARGS =
new String[]{"s3n://" + BUCKET_NAME + "/input/input.txt",
"s3n://" + BUCKET_NAME + "/result/" + FLOW_NAME};
private static final List<String> ARGS_AS_LIST = Arrays.asList(JOB_ARGS);
private static final List<JobFlowExecutionState> DONE_STATES = Arrays
.asList(new JobFlowExecutionState[]{JobFlowExecutionState.COMPLETED,
JobFlowExecutionState.FAILED,
JobFlowExecutionState.TERMINATED});
static AmazonS3 s3;
static AmazonElasticMapReduceClient emr;
private static void init() throws Exception {
AWSCredentials credentials = new PropertiesCredentials(
MyClient.class.getClassLoader().getResourceAsStream("AwsCredentials.properties"));
s3 = new AmazonS3Client(credentials);
emr = new AmazonElasticMapReduceClient(credentials);
emr.setRegion(Region.getRegion(Regions.EU_WEST_1));
}
private static JobFlowInstancesConfig configInstance() throws Exception {
// Configure instances to use
JobFlowInstancesConfig instance = new JobFlowInstancesConfig();
instance.setHadoopVersion(HADOOP_VERSION);
instance.setInstanceCount(INSTANCE_COUNT);
instance.setMasterInstanceType(INSTANCE_TYPE);
instance.setSlaveInstanceType(INSTANCE_TYPE);
// instance.setKeepJobFlowAliveWhenNoSteps(true);
// instance.setEc2KeyName("4synergy_palma");
return instance;
}
private static void runCluster() throws Exception {
// Configure the job flow
RunJobFlowRequest request = new RunJobFlowRequest(FLOW_NAME, configInstance());
request.setLogUri(S3N_LOG_URI);
// Configure the Hadoop jar to use
HadoopJarStepConfig jarConfig = new HadoopJarStepConfig(S3N_HADOOP_JAR);
jarConfig.setArgs(ARGS_AS_LIST);
try {
StepConfig enableDebugging = new StepConfig()
.withName("Enable debugging")
.withActionOnFailure("TERMINATE_JOB_FLOW")
.withHadoopJarStep(new StepFactory().newEnableDebuggingStep());
StepConfig runJar =
new StepConfig(S3N_HADOOP_JAR.substring(S3N_HADOOP_JAR.indexOf('/') + 1),
jarConfig);
request.setSteps(Arrays.asList(new StepConfig[]{enableDebugging, runJar}));
//Run the job flow
RunJobFlowResult result = emr.runJobFlow(request);
//Check the status of the running job
String lastState = "";
STATUS_LOOP:
while (true) {
DescribeJobFlowsRequest desc =
new DescribeJobFlowsRequest(
Arrays.asList(new String[]{result.getJobFlowId()}));
DescribeJobFlowsResult descResult = emr.describeJobFlows(desc);
for (JobFlowDetail detail : descResult.getJobFlows()) {
String state = detail.getExecutionStatusDetail().getState();
if (isDone(state)) {
System.out.println("Job " + state + ": " + detail.toString());
break STATUS_LOOP;
} else if (!lastState.equals(state)) {
lastState = state;
System.out.println("Job " + state + " at " + new Date().toString());
}
}
Thread.sleep(10000);
}
} catch (AmazonServiceException ase) {
System.out.println("Caught Exception: " + ase.getMessage());
System.out.println("Reponse Status Code: " + ase.getStatusCode());
System.out.println("Error Code: " + ase.getErrorCode());
System.out.println("Request ID: " + ase.getRequestId());
}
}
public static boolean isDone(String value) {
JobFlowExecutionState state = JobFlowExecutionState.fromValue(value);
return DONE_STATES.contains(state);
}
public static void main(String[] args) {
try {
init();
runCluster();
} catch (Exception e) {
e.printStackTrace();
}
}
} 在此类中,我首先声明一些常量,我认为这些常量是显而易见的。 在init()方法中,我使用添加到项目中的凭据属性文件。 我将此文件添加到了Maven项目的'/ main / resources'文件夹中。 它包含我的访问密钥和秘密密钥。
我还将EMR客户的区域设置为“ EU-WEST”。
下一个方法是“ configInstance()”。 在这种方法中,我通过设置Hadoop版本,实例数,实例大小等来创建和配置JobFlowInstance。您还可以配置'keepAlive'设置,以在作业完成后使集群保持活动状态。 在某些情况下这可能会有所帮助。 如果要使用此选项,则还可以设置要用于访问集群的密钥对,这可能很有用,因为如果不设置此密钥就无法访问集群。 方法“ runCluster()”是集群实际运行的地方。 它创建启动集群的请求。 在此请求中,添加了必须执行的步骤。 在我们的例子中,其中一个步骤是运行在先前步骤中创建的JAR文件。 我还添加了一个调试步骤,以便在集群完成并终止后我们可以访问调试日志记录。 我们可以简单地访问我用常量'S3N_LOG_URI'设置的S3存储桶中的日志文件。 创建此请求后,我们将基于此请求启动集群。 然后,我们每隔10秒钟拉动一次,以查看作业是否完成,并在控制台上显示一条消息,指示作业的当前状态。 要执行第一次运行,我们必须准备输入。
- 准备输入
作为作业的输入(有关此示例作业的更多信息,请参见此),我们必须使字典内容可用于EMR群集。 此外,我们必须使JAR文件可用,并确保输出和日志目录存在于我们的S3存储桶中。 有几种方法可以执行此操作:您还可以通过使用SDK以编程方式来执行此操作,也可以通过从命令行使用S3cmd来执行此操作,或者使用AWS管理控制台来执行此操作 。 只要最终得到类似的设置,就可以了:
- s3:// map-reduce-intro
- s3:// map-reduce-intro / input
- s3://map-reduce-intro/input/input.txt
- s3:// map-reduce-intro / job
- s3://map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar
- s3:// map-reduce-intro / log
- s3:// map-reduce-intro / result
或在使用S3cmd时如下所示:
s3cmd-1.5.0-alpha1$ s3cmd ls --recursive s3://map-reduce-intro/
2013-07-20 13:06 469941 s3://map-reduce-intro/input/input.txt
2013-07-20 14:12 5491 s3://map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar
2013-08-06 14:30 0 s3://map-reduce-intro/log/
2013-08-06 14:27 0 s3://map-reduce-intro/result/在上面的示例中,我已经在代码中引入了S3客户端。 您还可以使用它来准备输入或获取输出,作为客户工作的一部分。
- 运行集群
一切就绪后,我们就可以运行作业。 我只是在IntelliJ中运行'MyClient'的主要方法,并在控制台中获得以下输出:
Job STARTING at Tue Aug 06 16:31:55 CEST 2013
Job RUNNING at Tue Aug 06 16:36:18 CEST 2013
Job SHUTTING_DOWN at Tue Aug 06 16:38:40 CEST 2013
Job COMPLETED: {
JobFlowId: j-JDB14HVTRC1L
,Name: dictionary-8288df47-8aef-4ad3-badf-ee352a4a7c43
,LogUri: s3n://map-reduce-intro/log/,AmiVersion: 2.4.0
,ExecutionStatusDetail: {State: COMPLETED,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013
,StartDateTime: Tue Aug 06 16:36:14 CEST 2013
,ReadyDateTime: Tue Aug 06 16:36:14 CEST 2013
,EndDateTime: Tue Aug 06 16:39:02 CEST 2013
,LastStateChangeReason: Steps completed}
,Instances: {MasterInstanceType: m1.small
,MasterPublicDnsName: ec2-54-216-104-11.eu-west-1.compute.amazonaws.com
,MasterInstanceId: i-93268ddf
,InstanceCount: 1
,InstanceGroups: [{InstanceGroupId: ig-2LURHNAK5NVKZ
,Name: master
,Market: ON_DEMAND
,InstanceRole: MASTER
,InstanceType: m1.small
,InstanceRequestCount: 1
,InstanceRunningCount: 0
,State: ENDED
,LastStateChangeReason: Job flow terminated
,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013
,StartDateTime: Tue Aug 06 16:34:28 CEST 2013
,ReadyDateTime: Tue Aug 06 16:36:10 CEST 2013
,EndDateTime: Tue Aug 06 16:39:02 CEST 2013}]
,NormalizedInstanceHours: 1
,Ec2KeyName: 4synergy_palma
,Placement: {AvailabilityZone: eu-west-1a}
,KeepJobFlowAliveWhenNoSteps: false
,TerminationProtected: false
,HadoopVersion: 1.0.3}
,Steps: [
{StepConfig: {Name: Enable debugging
,ActionOnFailure: TERMINATE_JOB_FLOW
,HadoopJarStep: {Properties: []
,Jar: s3://us-east-1.elasticmapreduce/libs/script-runner/script-runner.jar
,Args: [s3://us-east-1.elasticmapreduce/libs/state-pusher/0.1/fetch]}
}
,ExecutionStatusDetail: {State: COMPLETED,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013
,StartDateTime: Tue Aug 06 16:36:12 CEST 2013
,EndDateTime: Tue Aug 06 16:36:40 CEST 2013
,}
}
, {StepConfig: {Name: /map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar
,ActionOnFailure: TERMINATE_JOB_FLOW
,HadoopJarStep: {Properties: []
,Jar: s3n://map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar
,Args: [s3n://map-reduce-intro/input/input.txt
, s3n://map-reduce-intro/result/dictionary-8288df47-8aef-4ad3-badf-ee352a4a7c43]}
}
,ExecutionStatusDetail: {State: COMPLETED
,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013
,StartDateTime: Tue Aug 06 16:36:40 CEST 2013
,EndDateTime: Tue Aug 06 16:38:10 CEST 2013
,}
}]
,BootstrapActions: []
,SupportedProducts: []
,VisibleToAllUsers: false
,}
Process finished with exit code 0当然,我们在S3存储桶中配置的“结果”文件夹中有一个结果:
![]()
我将结果转移到我的本地计算机上,并进行了查看:
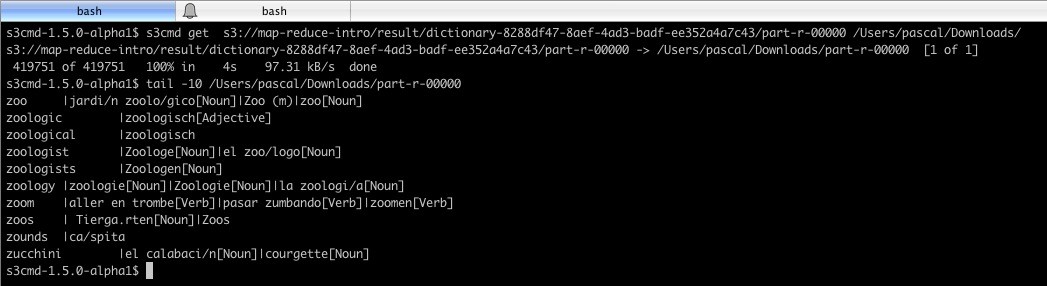
这样就可以得出这个简单的结论,但我认为,这是创建Hadoop作业并在对它进行单元测试之后在群集上运行它的完整示例,就像对待所有软件一样。
以该设置为基础,可以轻松地提出更复杂的业务案例,并对其进行测试和配置以在AWS EMR上运行。
翻译自: https://www.javacodegeeks.com/2013/09/run-your-hadoop-mapreduce-job-on-amazon-emr.html















 3146
3146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









