





Apache Hadoop软件库是一个框架,该框架允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。 它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。
库本身不用于依靠硬件来提供高可用性,而是被设计用来检测和处理应用程序层的故障,因此可以在计算机集群的顶部提供高可用性服务,每台计算机都容易出现故障。 Hadoop库包含两个主要组件HDFS和MapReduce,在本文中,我们将深入研究HDFS的每个部分,并了解其内部工作方式。
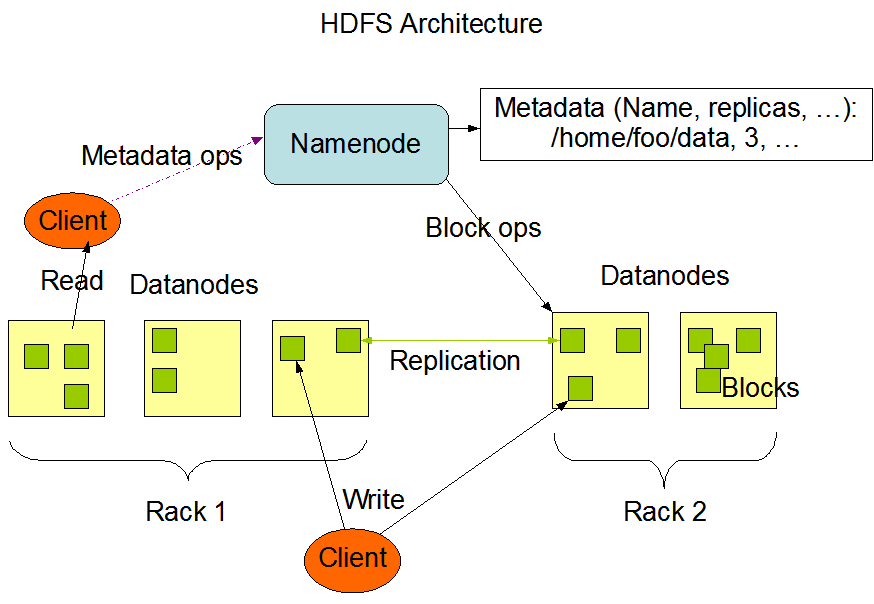
HDFS具有主/从体系结构。 HDFS群集由单个NameNode和管理文件系统名称空间并控制客户端对文件的访问的主服务器组成。 此外,还有许多数据节点,通常是集群中每个节点一个,用于管理与它们所运行的节点相连的存储。
HDFS公开了文件系统名称空间,并允许用户数据存储在文件中。 在内部,文件被分成一个或多个块,这些块存储在一组DataNode中。 NameNode执行文件系统名称空间操作,例如打开,关闭和重命名文件和目录。 它还确定块到DataNode的映射。 DataNode负责处理来自文件系统客户端的读写请求。 DataNode还根据NameNode的指令执行块创建,删除和复制。
HDFS分析
在使用JArchitect分析Hadoop 之后 ,这是hdfs项目的依赖关系图。
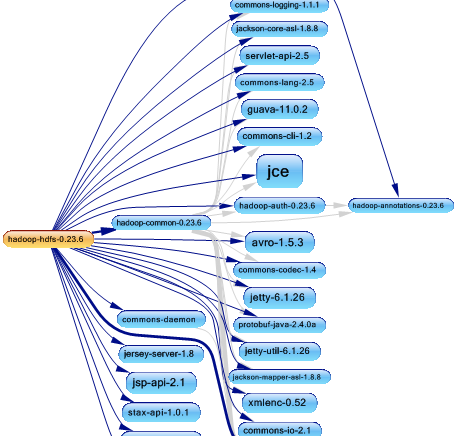
为了完成其工作,hdfs使用了许多第三方库,例如番石榴,码头,杰克逊等。 DSM(设计结构矩阵)为我们提供了有关使用每个库的权重的更多信息。
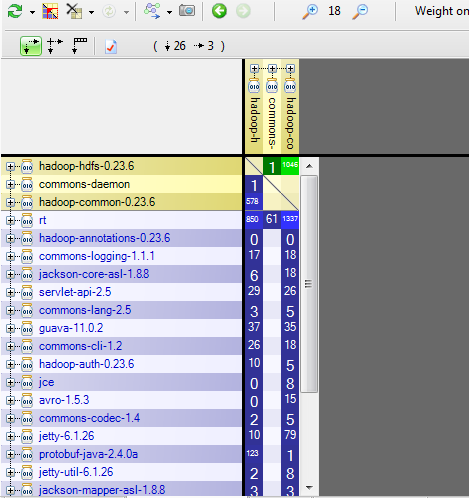
HDFS主要使用rt,hadoop-common和protobuf库。 当使用外部库时,最好检查一下我们是否可以轻松地将另一个第三方库更改为另一个库而不影响整个应用程序,这有很多原因可以鼓励我们更改第三方库。 另一个库可以:
- 具有更多功能
- 表现更好
- 更安全
让我们以jetty lib为例,并搜索hdfs中的哪些方法直接使用它。 从方法中的m中,其中m.IsUsing(“ jetty-6.1.26”)&& m.ParentProject.Name ==“ hadoop-hdfs-0.23.6”选择新的{m,m.NbBCInstructions}
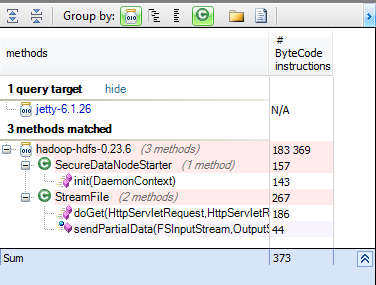
只有很少的方法直接使用jetty lib,而用另一种方法进行更改将非常容易。 通常,当您仅可以在某些类中使用外部库时,进行隔离非常有趣,它可以帮助轻松地维护和发展项目。 现在让我们发现主要的HDFS组件:
数据节点
启动
为了发现如何启动数据节点,让我们在hdfs jar的所有入口点之前进行搜索。 从m中的方法中的m.Name.Contains(“ main(String [])”)&& m.IsStatic选择新的{m,m.NbBCInstructions}
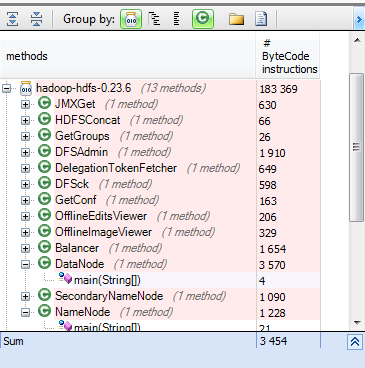
hdfs具有许多条目,例如DFSAdmin,DfSsc,Balancer和HDFSConcat。 对于数据节点,相关的入口点是DataNode类,这是调用其main方法时发生的情况。
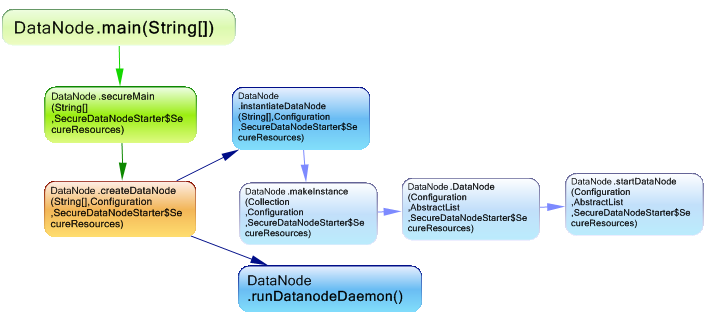
main方法调用第一个securemain并将参数securityresources传递给它,当在非安全群集中启动该节点时,此参数为null,但是在安全环境中启动该节点的情况下,将为该参数分配安全资源。 SecureResources类包含两个属性:
- StreamingSocket:用于将数据流传输到datanode的安全端口。
- listner:Web服务器的安全侦听器。
这是从DataNode.StartDataNode调用的方法。
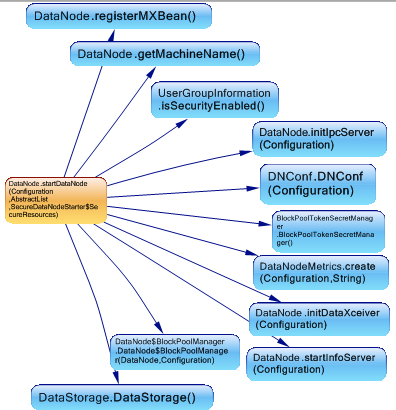
此方法初始化IPCServer,DataXceiver(这是用于处理传入/传出数据流的线程),创建数据节点度量实例。
如何管理数据?
DataNode类具有名为FSDatasetinterface类型的数据的属性。 FSDatasetinterface是用于基础存储的接口,用于存储数据节点的块。 让我们搜索Hadoop中可用的实现。 从类型为t.Implement(“ org.apache.hadoop.hdfs.server.datanode.FSDatasetInterface”)选择新的{t,t.NbBCInstructions}的类型中
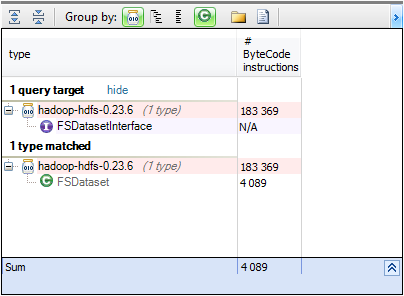
Hadoop提供了FSDataset,它管理一组数据块并将其存储在目录中。 使用接口可实现低耦合,并使设计非常灵活,但是,如果使用实现而不是接口,我们将失去这一优势,并且要检查是否在任何地方都使用interfaceDataSet表示数据,让我们使用FSDataSet搜索所有方法。 从m.IsUsing(“ org.apache.hadoop.hdfs.server.datanode.FSDataset”)中选择新的{m,m.NbBCInstructions}的方法中的m
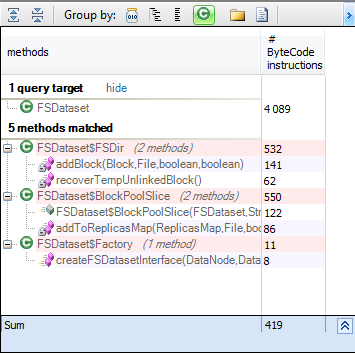
只有FSDataSet内部类直接使用它,而在所有其他地方都使用interfaceDataSet,这使得更改数据集类型的可能性变得非常容易。 但是,如何更改interfaceDataSet并给出自己的实现? 为此,让我们搜索FSDataSet的创建位置。
从方法的m中开始,让depth0 = m.DepthOfCreateA(“ org.apache.hadoop.hdfs.server.datanode.FSDataset”),其中depth0 == 1选择新的{m,depth0}

工厂模式用于创建实例。 问题是,如果该工厂直接在getFactory方法中创建实现,则必须更改Hadoop代码以为其提供自定义数据集管理器。 让我们发现getFactory方法使用了哪些方法。 从m.IsUsedBy(“ org.apache.hadoop.hdfs.server.datanode.FSDatasetInterface $ Factory.getFactory(Configuration)”)中选择新的{m,m.NbBCInstructions}
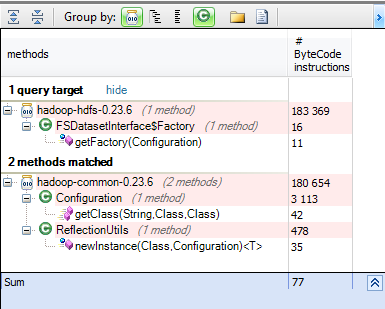
好消息是工厂使用Configuration来获取类的实现,因此我们只能通过配置给出自定义的DataSet,我们还可以搜索配置可以提供的所有类。
从m.IsUsing(“ org.apache.hadoop.conf.Configuration.getClass(String,Class,Class)”)中选择新的{m,m.NbBCInstructions}的方法中的m
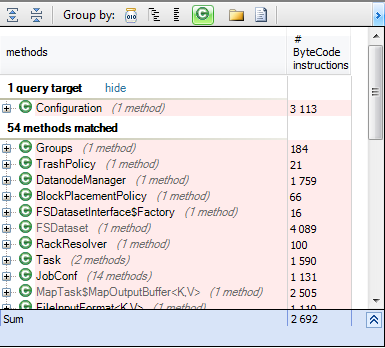
可以在不更改其源代码的情况下将许多类注入Hadoop框架,这使其非常灵活。
名称节点
NameNode是所有HDFS元数据的仲裁器和存储库。 该系统的设计方式是,用户数据永远不会流过NameNode。 这是启动名称节点时调用的一些方法。
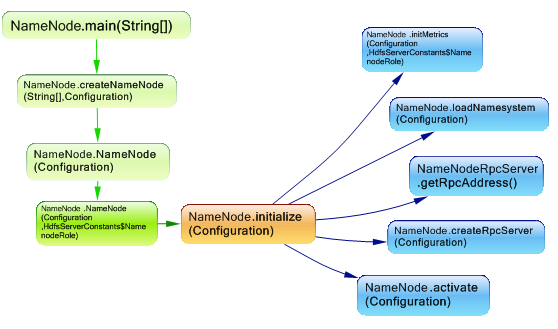
创建了RPC服务器,并加载了fsnamesystem,下面是对这两个组件的快速浏览:
NameNodeRpcServer
NameNodeRpcServer负责处理对NameNode的所有RPC调用。 例如,当启动一个数据节点时,它必须在NameNode上注册自己,rpc服务器接收该请求并将其转发到fsnamesystem,后者将其重定向到dataNodeManager。
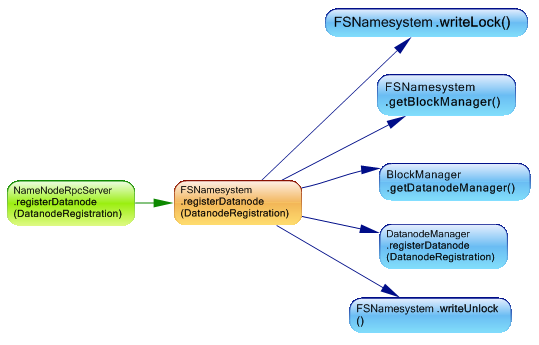
另一个示例是当接收到数据块时。 从m.IsUsedBy(“ org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.blockReceived(DatanodeRegistration,String,Block [],String [])”)中的m中选择新的{m,m.NbBCInstructions}
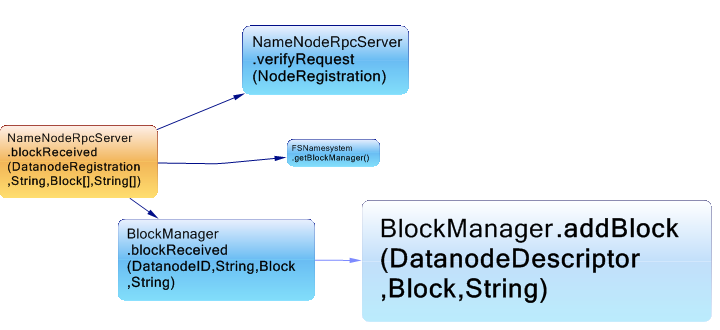
图中的每个矩形与代码指令的字节数成正比,我们可以观察到BlockManager.addBlock可以完成大部分工作。 Haddop有趣的是,每个类都有特定的职责,并且任何请求都将重定向到相应的管理器。
FS名称系统
HDFS支持传统的分层文件组织。 用户或应用程序可以创建目录并将文件存储在这些目录中。 文件系统名称空间层次结构与大多数其他现有文件系统相似。 可以创建和删除文件,将文件从一个目录移动到另一个目录或重命名文件。 例如,这是有关符号链接创建的依赖图。

HDFS客户端
DFSClient可以连接到Hadoop Filesystem并执行基本文件任务。 它使用ClientProtocol与NameNode守护程序进行通信,并直接连接到DataNode以读取/写入块数据。
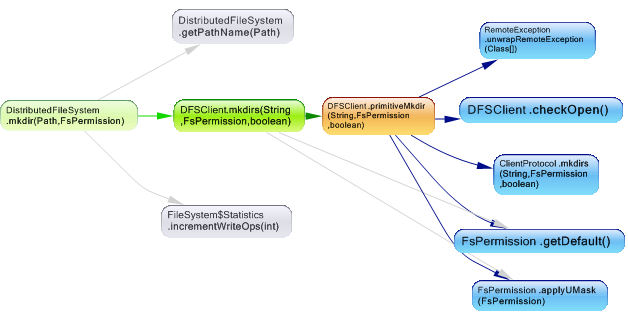
Hadoop DFS用户应获取DistributedFileSystem的实例,该实例使用DFSClient处理文件系统任务。 DistributedFileSystem充当外观并将请求重定向到DFSClient类,这是有关创建目录请求的依赖关系图。
结论:
以用户身份使用框架非常有趣,但是深入该框架可以为我们提供更多信息,以便更好地理解它,并轻松地使其适应我们的需求。 Hadoop是许多公司使用的功能强大的框架,其中大多数公司都需要对其进行自定义,所幸的是,Hadoop非常灵活,允许我们在不更改源代码的情况下更改行为。
翻译自: https://www.javacodegeeks.com/2013/04/how-hadoop-works-hdfs-case-study.html















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









