





为什么生产日志无法帮助您找到错误的真正根本原因?
询问您是否使用日志文件监视您的应用程序几乎就像询问…您是否喝水。 我们都使用日志,但是我们如何使用它们则是一个完全不同的问题。
在下面的文章中,我们将对日志进行更深入的研究,并了解日志的用法和向日志中写入的内容。 我们走吧。
我们的研发团队对Aviv Danziger表示了极大的帮助,感谢他为我们提供和处理数据的巨大帮助。
基础工作
我们寻求答案需要大量数据,因此我们选择了Google BigQuery。 几个月前,我们首次使用它来查看GitHub的顶级Java项目如何使用logs 。
对于我们当前的帖子,我们在GitHub上排名前40万的Java存储库中,按它们在2016年获得的星级排名进行了排名。在这些存储库中,我们过滤掉了Android,示例项目和简单的测试程序,从而为我们提供了15797个存储库。
然后,我们提取了包含100多个日志记录语句的存储库,这给我们留下了1,463个存储库可以使用。 现在,是时候为所有使我们彻夜难眠的问题找到答案的时候了。
TL; DR:主要要点
如果您不喜欢饼图,柱形图或条形图,并且想跳过主要课程而直接进入甜点,那么以下是我们了解的关于日志记录及其实际操作的5个关键点:
1.日志实际上并没有我们想像的那么多,即使它们每天最多可以增加数百GB。 超过50%的语句没有有关应用程序可变状态的信息
2.在生产中,禁用了全部日志记录语句的64%
3.达到生产状态的日志记录语句的变量比平均开发水平的日志记录语句少35% 4. “永远不要发生” 5.有一种更好的方法来解决生产中的错误
1.多少个记录语句实际上包含变量?
我们要检查的第一件事是每个语句中发出了多少个变量。 我们选择在每个存储库中按从0个变量到5个及以上的比例对数据进行切片。 然后,我们对总数进行了计算,并对研究中所有项目的平均细分情况有所了解。
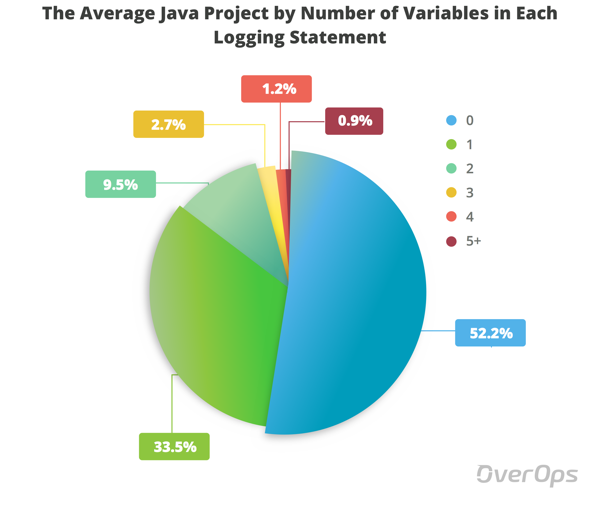
按变量数计算的平均Java项目
如您所见,普通的Java项目不会在其日志记录语句的50%以上记录任何变量。 我们还可以看到,只有0.95%的日志记录语句发出5个或更多变量。
这意味着日志所捕获的有关应用程序的信息有限,而找出实际发生的情况可能就像在日志文件中搜索针头一样。
2.生产中激活了多少个记录语句?
开发和生产环境有所不同,原因有很多,其中之一就是它们与日志记录的关系。 在开发中,所有日志级别均已激活。 但是,在生产中仅会激活ERROR和WARN。 让我们看看这种分解是什么样的。
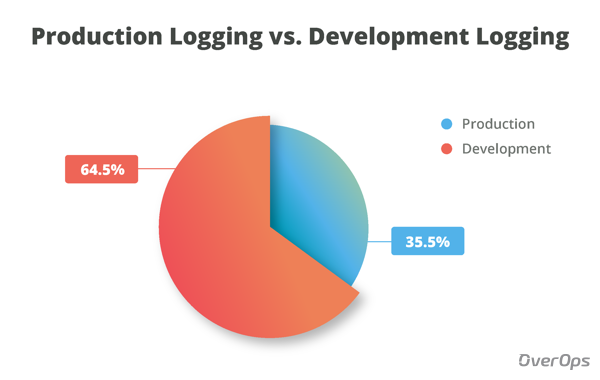
生产与开发日志
该图表显示,普通的Java应用程序具有35.5%的唯一日志记录语句,这些语句有可能在生产中被激活(ERROR,WARN),以及64.5%的语句仅在开发中被激活(TRACE,INFO,DEBUG)。
3.每个日志级别的平均变量数是多少?
因此,开发人员不仅会跳过语句中的变量,而且普通的Java应用程序首先不会向生产日志发送那么多的语句。
现在,我们决定分别查看每个日志级别,并计算相应语句中变量的平均数量。
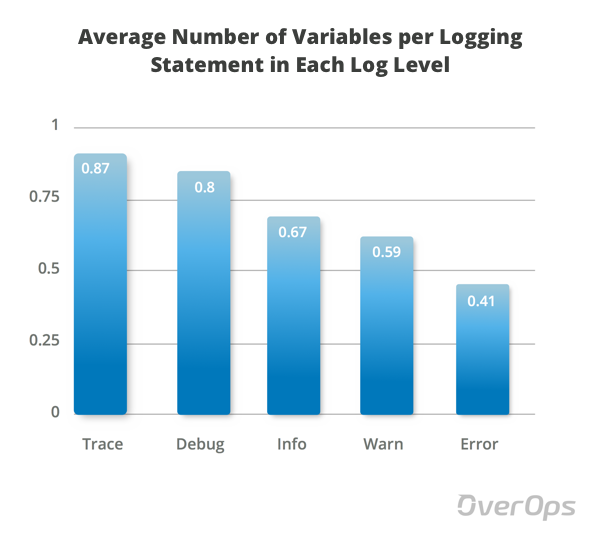
每个记录语句的平均变量数
平均值表明,TRACE,DEBUG和INFO语句比WARN和ERROR包含更多的变量。 考虑到前三个变量的平均数量是0.78,而后两个变量的平均数量是0.5,“更多”是一个礼貌的单词。
这意味着生产日志记录语句包含的变量比开发日志记录语句少35%。 另外,正如我们前面所看到的,它们的总数也要低得多。
如果要在日志中搜索有关您的应用程序发生了什么的线索,但显示为空白–这就是它发生的原因。 不用担心,有更好的方法。
通过OverOps ,您可以查看任何异常,记录的错误或警告背后的变量,而无需依赖实际记录的信息。 您将能够在事件的整个调用堆栈中查看完整的源代码和变量状态。 即使未将其打印到日志文件中。 OverOps还向您显示250条在错误之前记录的DEBUG,TRACE和INFO级别的语句,即使它们已关闭并且从未到达日志文件,也正在生产中。
我们很乐意向您展示其工作原理, 请点击此处安排演示 。
4.这永远不会发生
由于我们已经掌握了所有这些日志记录语句的信息,因此我们决定从中获得一些乐趣。 我们发现有58条提及“这绝不应该发生”。
我们只能说,如果它永远不会发生,则至少要有一个体面才能打印出一个变量或2,因此您将能够看到它为什么仍会发生��
我们是如何做到的?
如前所述,要获取此数据,我们首先必须过滤掉不相关的Java存储库,然后将重点放在具有超过100个日志记录语句的存储库上,这给我们留下了1,463个存储库。
然后,我们添加了一些正则表达式魔术,并删除了所有日志行:
SELECT *
FROM [java-log-levels-usage:java_log_level_usage.top_repos_java_contents_lines_no_android_no_arduino]
WHERE REGEXP_MATCH(line, r'.*((LOGGER|Logger|logger|LOG|Log|log)[.](trace|info|debug|warn|warning|error|fatal|severe|config|fine|finer|finest)).*')
OR REGEXP_MATCH(line, r'.*((Level|Priority)[.](TRACE|TRACE_INT|X_TRACE_INT|INFO|INFO_INT|DEBUG|DEBUG_INT|WARN|WARN_INT|WARNING|WARNING_INT|ERROR|ERROR_INT)).*')
OR REGEXP_MATCH(line, r'.*((Level|Priority)[.](FATAL|FATAL_INT|SEVERE|SEVERE_INT|CONFIG|CONFIG_INT|FINE|FINE_INT|FINER|FINER_INT|FINEST|FINEST_INT|ALL|OFF)).*')现在我们有了数据,我们开始对其进行切片。 首先,我们筛选出每个日志级别的变量数量:
SELECT sample_repo_name
,log_level
,CASE WHEN parametersCount + concatenationCount = 0 THEN "0"
WHEN parametersCount + concatenationCount = 1 THEN "1"
WHEN parametersCount + concatenationCount = 2 THEN "2"
WHEN parametersCount + concatenationCount = 3 THEN "3"
WHEN parametersCount + concatenationCount = 4 THEN "4"
WHEN parametersCount + concatenationCount >= 5 THEN "5+"
END total_params_tier
,SUM(parametersCount + concatenationCount) total_params
,SUM(CASE WHEN parametersCount > 0 THEN 1 ELSE 0 END) has_parameters
,SUM(CASE WHEN concatenationCount > 0 THEN 1 ELSE 0 END) has_concatenation
,SUM(CASE WHEN parametersCount = 0 AND concatenationCount = 0 THEN 1 ELSE 0 END) has_none
,SUM(CASE WHEN parametersCount > 0 AND concatenationCount > 0 THEN 1 ELSE 0 END) has_both
,COUNT(1) logging_statements
,SUM(parametersCount) parameters_count
,SUM(concatenationCount) concatenation_count
,SUM(CASE WHEN isComment = true THEN 1 ELSE 0 END) comment_count
,SUM(CASE WHEN shouldNeverHappen = true THEN 1 ELSE 0 END) should_never_happen_count
FROM [java-log-levels-usage:java_log_level_usage.top_repos_java_log_lines_no_android_no_arduino_attributes]
GROUP BY sample_repo_name
,log_level
,total_params_tier然后计算每个层的平均使用量。 这就是我们获得总存储库语句的平均百分比的方式。
SELECT total_params_tier
,AVG(logging_statements / total_repo_logging_statements) percent_out_of_total_repo_statements
,SUM(total_params) total_params
,SUM(logging_statements) logging_statements
,SUM(has_parameters) has_parameters
,SUM(has_concatenation) has_concatenation
,SUM(has_none) has_none
,SUM(has_both) has_both
,SUM(parameters_count) parameters_count
,SUM(concatenation_count) concatenation_count
,SUM(comment_count) comment_count
,SUM(should_never_happen_count) should_never_happen_count
FROM (SELECT sample_repo_name
,total_params_tier
,SUM(total_params) total_params
,SUM(logging_statements) logging_statements
,SUM(logging_statements) OVER (PARTITION BY sample_repo_name) total_repo_logging_statements
,SUM(has_parameters) has_parameters
,SUM(has_concatenation) has_concatenation
,SUM(has_none) has_none
,SUM(has_both) has_both
,SUM(parameters_count) parameters_count
,SUM(concatenation_count) concatenation_count
,SUM(comment_count) comment_count
,SUM(should_never_happen_count) should_never_happen_count
FROM [java-log-levels-usage:java_log_level_usage.top_repos_java_log_lines_no_android_no_arduino_attributes_counters_with_params_count]
GROUP BY sample_repo_name
,total_params_tier)
WHERE total_repo_logging_statements >= 100
GROUP BY total_params_tier
ORDER BY 1,2最后的想法
我们都使用日志文件,但是似乎大多数人都认为它们是理所当然的。 有了众多的日志管理工具,我们忘记了控制我们自己的代码-并使它对于我们理解,调试和修复很有意义。
翻译自: https://www.javacodegeeks.com/2017/02/github-research-50-java-logging-statements-written-wrong.html















 89
89

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









