





apache ignite
在本文中, “使用Apache Ignite进行高性能内存计算”一书的作者将讨论使用Apache Strom和Apache Ignite进行复杂的事件处理。 本文的一部分摘自
书 。
术语“复杂事件处理”或CEP没有广泛或高度接受的定义。 Wikipedia的以下引用可以简要描述什么是复杂事件处理:
“复杂事件处理(CEP)主要是一个事件处理概念,用于处理多个事件,以识别事件云中有意义的事件为目标。 CEP采用的技术包括检测许多事件的复杂模式,事件相关性和抽象性,事件层次结构以及事件之间的因果关系,成员关系和时间安排以及事件驱动过程。
为简单起见,复杂事件处理(CEP)是一种用于在真实世界中永不停止或流式传输事件数据的低延迟过滤,聚合和计算的技术。 在IT环境中,原始基础结构和业务事件的数量和速度均呈指数级增长。 此外,移动设备的爆炸式增长和高速连接的普遍性加剧了移动数据的爆炸式增长。 同时,对业务流程敏捷性和执行的需求仅在增长。 这两个趋势给组织施加了压力,要求它们提高其能力以支持事件驱动的实施架构模式。 实时事件处理需要基础架构和应用程序开发环境来执行事件处理要求。 这些要求通常包括从日常使用案例扩展到极高的速度或各种数据和事件吞吐量的需求,潜在的延迟时间以微秒为单位,而不是响应时间的秒数。
Apache Ignite允许在内存中以可伸缩且容错的方式处理连续不断的数据流,而不是在数据到达数据库后对其进行分析。 这不仅使您能够关联关系并从大量数据中检测有意义的模式,还可以更快,更高效地完成此操作。 事件历史记录可以在内存中保留任何时间长度(对于长时间运行的事件序列至关重要),也可以作为事务记录在存储的数据库中。
Apache Ignite CEP可以在众多行业中使用,以下是一些一流的用例:
- 金融服务:执行实时风险分析,监视和报告金融交易以及欺诈检测的能力。
- 电信:能够执行实时呼叫详细记录以及SMS监视和DDoS攻击。
- IT系统和基础架构:能够实时检测故障或不可用的应用程序或服务器的能力。
- 物流:能够实时跟踪装运和订单处理,并报告可能的到货延迟。
还有更多的工业或功能领域,您可以在其中使用Apache Ignite处理流事件数据,例如保险,运输和公共部门。 复杂事件处理或CEP包含其过程的三个主要部分:
- 事件捕获或数据摄取。
- 计算或计算这些数据。
- React或行动。
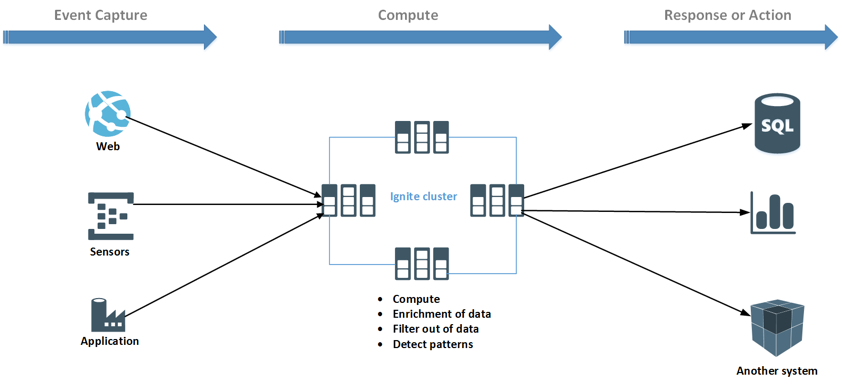
如上图所示,数据是从不同来源获取的。 源可以是任何传感器(IoT),Web应用程序或行业应用程序。 可以直接在Ignite群集上以收集方式并发处理流数据。 另外,数据可以从其他来源丰富或过滤掉。 计算数据后,可以将计算或汇总的数据导出到其他系统以进行可视化或采取措施。
Apache Ignite Storm Streamer模块提供了通过Storm到Ignite缓存的流传输。 在开始使用Ignite流媒体之前,让我们看一下Apache Storm,以获取有关Apache Storm的一些基础知识。
Apache Storm是一个分布式容错实时计算系统。 在短时间内,Apache Storm成为分布式实时处理系统的标准,该系统使您可以处理大量数据。 Apache Storm项目是开源的,用Java和Clojure编写。 它成为实时分析的首选。 Apache Ignite Storm流媒体模块提供了一种方便的方法,可通过Storm将数据流传输到Ignite缓存。
关键概念:
Apache Storm从一端读取原始数据流,并将其通过一系列小型处理单元,然后在另一端输出处理后的信息。 让我们详细了解Apache Storm的主要组件–
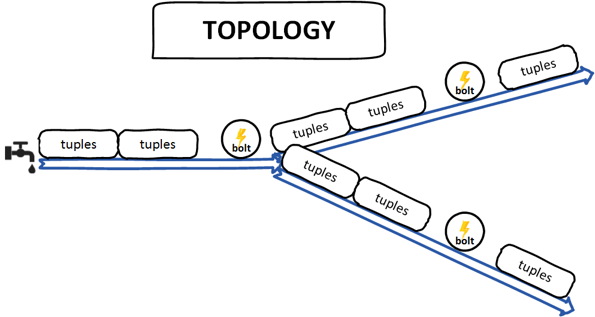
元组 –它是Storm的主要数据结构。 这是元素的有序列表。 通常,元组支持所有基本数据类型。

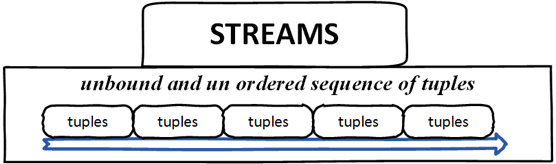
流 –这是一个无界且无序的元组序列。
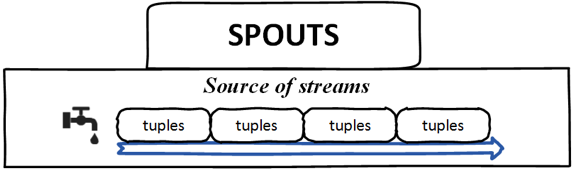
嘴 -流的来源,简单来说,壶嘴从拓扑中的源读取数据。 喷嘴可以是可靠的或不可靠的。 喷口可以与队列,Web日志,事件数据等对话。
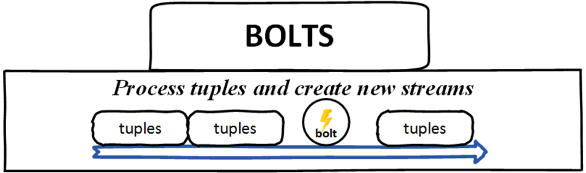
螺栓 –螺栓是逻辑处理单元,它负责处理数据和创建新的流。 螺栓可以执行过滤,聚合,联接,与文件/数据库交互等操作。 螺栓从喷嘴接收数据,然后发射到一个或多个螺栓。
拓扑 –拓扑是“喷口和螺栓”的有向图,该图的每个节点都包含数据处理逻辑(螺栓),而连接边定义数据(流)的流。
与Hadoop不同,Storm可使拓扑永久运行直到您将其杀死。 一个简单的拓扑结构从喷口开始,从源头发射流到螺栓以处理数据。 Apache Storm的主要工作是运行拓扑,并将在给定的时间运行任意数量的拓扑。
开箱即用的Ignite提供了Storm Bolt(StormStreamer)的实现,以将计算的数据流式传输到Ignite缓存中。 另一方面,您可以记下自定义的Strom Bolt,以将流数据提取到Ignite中。 要开发自定义的Storm Bolt,只需实现* BaseBasicBolt *或* IRichBolt * Storm接口。 但是,如果决定使用StormStreamer,则必须配置一些属性才能正确运行Ignite Bolt。 所有必填属性如下所示:
| 没有 | 物业名称 | 描述 |
|---|---|---|
| 1个 | 快取名称 | 将在其中存储数据的Ignite缓存的缓存名称。 |
| 2 | IgniteTupleField | 命名“点燃元组”字段,通过它在拓扑中获取元组数据。 默认情况下,该值为ignite。 |
| 3 | IgniteConfigFile | 此属性将设置Ignite弹簧配置 文件。 允许您向和发送消息和使用消息 从点燃主题。 |
| 4 | 允许覆盖 | 它将启用覆盖缓存中的现有值,默认值为false。 |
| 5 | 自动刷新频率 | 自动刷新频率(以毫秒为单位)。 从本质上讲,这是拖缆将在 尝试将到目前为止添加的所有数据提交到远程 节点。 默认值为10秒。 |
掌握了基础知识之后,我们来构建一些有用的工具来检查Ignite StormStreamer的工作方式。 该应用程序的基本思想是设计喷嘴和螺栓的一种拓扑,该拓扑可以处理来自交通日志文件的大量数据,并在特定值超过预定义阈值时触发警报。 使用拓扑,可以逐行读取日志文件,并且该拓扑旨在监视传入的数据。 在我们的例子中,日志文件将包含数据,例如车辆注册号,速度和来自高速公路交通摄像头的高速公路名称。 如果车辆超过速度限制(例如120km / h),Storm拓扑会将数据发送到Ignite缓存。
接下来的清单将显示我们将在示例中使用的CSV文件类型,其中包含车辆数据信息,例如车辆注册号,车辆行驶的速度和高速公路的位置。
AB 123, 160, North city
BC 123, 170, South city
CD 234, 40, South city
DE 123, 40, East city
EF 123, 190, South city
GH 123, 150, West city
XY 123, 110, North city
GF 123, 100, South city
PO 234, 140, South city
XX 123, 110, East city
YY 123, 120, South city
ZQ 123, 100, West city 以上示例的思想取自Dobbs博士的期刊。 由于本书不是为了研究Apache Storm,因此我将使示例尽可能简单。 另外,我还添加了著名的Storm单词计数示例,该示例通过StormStreamer模块将单词计数值提取到Ignite缓存中。 如果您对代码感到好奇,可以通过以下网址获得
Chapter-cep / storm 。 上面的CSV文件将成为Storm拓扑的来源。
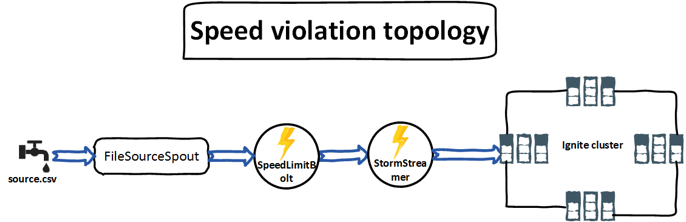
如上图所示, FileSourceSpout接受输入的CSV日志文件,逐行读取数据,并将数据发送到SpeedLimitBolt以进行进一步的阈值处理。 处理完成后,如果发现有任何超过速度限制的汽车,则将数据发送到Ignite StormStreamer螺栓,然后将其提取到缓存中。 让我们深入了解Storm拓扑。
第1步:
因为这是一个Storm拓扑,所以必须在maven项目中添加Storm和Ignite StormStreamer依赖项。
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-storm</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-core</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.10.0</version>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>在撰写本书时,仅支持Apache Storm版本0.10.0。 请注意,按照Ignite文档中的描述,您不需要任何Kafka模块即可运行或执行此示例。
第2步:
创建的Ignite配置文件(见例如,ignite.xml文件/chapter-cep/storm/src/resources/example-ignite.xml ),并确保它是可以从类路径。 Ignite配置的内容与本章的上一部分相同。
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util.xsd">
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<!-- Enable client mode. -->
<property name="clientMode" value="true"/>
<!-- Cache accessed from IgniteSink. -->
<property name="cacheConfiguration">
<list>
<!-- Partitioned cache example configuration with configurations adjusted to server nodes'. -->
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="atomicityMode" value="ATOMIC"/>
<property name="name" value="testCache"/>
</bean>
</list>
</property>
<!-- Enable cache events. -->
<property name="includeEventTypes">
<list>
<!-- Cache events (only EVT_CACHE_OBJECT_PUT for tests). -->
<util:constant static-field="org.apache.ignite.events.EventType.EVT_CACHE_OBJECT_PUT"/>
</list>
</property>
<!-- Explicitly configure TCP discovery SPI to provide list of initial nodes. -->
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
<list>
<value>127.0.0.1:47500</value>
</list>
</property>
</bean>
</property>
</bean>
</property>
</bean>
</beans>第三步:
创建一个ignite-storm.properties文件,以添加缓存名称,元组名称和Ignite配置的名称,如下所示。
cache.name=testCache
tuple.name=ignite
ignite.spring.xml=example-ignite.xml第4步:
接下来,创建FileSourceSpout Java类,如下所示,
public class FileSourceSpout extends BaseRichSpout {
private static final Logger LOGGER = LogManager.getLogger(FileSourceSpout.class);
private SpoutOutputCollector outputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.outputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
try {
Path filePath = Paths.get(this.getClass().getClassLoader().getResource("source.csv").toURI());
try(Stream<String> lines = Files.lines(filePath)){
lines.forEach(line ->{
outputCollector.emit(new Values(line));
});
} catch(IOException e){
LOGGER.error(e.getMessage());
}
} catch (URISyntaxException e) {
LOGGER.error(e.getMessage());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("trafficLog"));
}
}FileSourceSpout代码具有三种重要方法
- open():此方法将在spout的开头被调用,并为您提供上下文信息。
- nextTuple():此方法将允许您一次将一个元组传递给Storm拓扑以进行处理,在这种方法中,我逐行读取CSV文件,并将该行作为元组发出给螺栓。
- defineOutputFields():此方法声明输出元组的名称,在本例中,名称应为trafficLog。
步骤5:
现在创建实现BaseBasicBolt接口的SpeedLimitBolt.java类。
public class SpeedLimitBolt extends BaseBasicBolt {
private static final String IGNITE_FIELD = "ignite";
private static final int SPEED_THRESHOLD = 120;
private static final Logger LOGGER = LogManager.getLogger(SpeedLimitBolt.class);
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
String line = (String)tuple.getValue(0);
if(!line.isEmpty()){
String[] elements = line.split(",");
// we are interested in speed and the car registration number
int speed = Integer.valueOf((elements[1]).trim());
String car = elements[0];
if(speed > SPEED_THRESHOLD){
TreeMap<String, Integer> carValue = new TreeMap<String, Integer>();
carValue.put(car, speed);
basicOutputCollector.emit(new Values(carValue));
LOGGER.info("Speed violation found:"+ car + " speed:" + speed);
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields(IGNITE_FIELD));
}
}让我们再次逐行进行。
- execute():这是实现螺栓的业务逻辑的方法,在这种情况下,我用逗号分隔行并检查汽车的速度限制。 如果给定汽车的速度限制高于阈值,则我们将从该元组创建新的树图数据类型,并将该元组发送到下一个螺栓,在本例中,下一个螺栓将是StormStreamer。
- defineOutputFields():此方法类似于FileSourceSpout中的clarifyOutputFields()方法,它声明将返回Ignite元组以进行进一步处理。
请注意,元组名称IGNITE在这里很重要, StormStreamer将仅处理名称为Ignite的元组。
步骤6:
现在是时候创建我们的拓扑来运行我们的示例了。 拓扑将喷口和螺栓绑在一张图中,该图定义了数据如何在组件之间流动。 它还提供了Storm在创建集群中组件实例时使用的并行提示。 要实现拓扑,请在src \ main \ java \ com \ blu \ imdg \ storm \ topology目录中创建一个名为SpeedViolationTopology.java的新文件。 使用以下内容作为文件的内容:
public class SpeedViolationTopology {
private static final int STORM_EXECUTORS = 2;
public static void main(String[] args) throws Exception {
if (getProperties() == null || getProperties().isEmpty()) {
System.out.println("Property file <ignite-storm.property> is not found or empty");
return;
}
// Ignite Stream Ibolt
final StormStreamer<String, String> stormStreamer = new StormStreamer<>();
stormStreamer.setAutoFlushFrequency(10L);
stormStreamer.setAllowOverwrite(true);
stormStreamer.setCacheName(getProperties().getProperty("cache.name"));
stormStreamer.setIgniteTupleField(getProperties().getProperty("tuple.name"));
stormStreamer.setIgniteConfigFile(getProperties().getProperty("ignite.spring.xml"));
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new FileSourceSpout(), 1);
builder.setBolt("limit", new SpeedLimitBolt(), 1).fieldsGrouping("spout", new Fields("trafficLog"));
// set ignite bolt
builder.setBolt("ignite-bolt", stormStreamer, STORM_EXECUTORS).shuffleGrouping("limit");
Config conf = new Config();
conf.setDebug(false);
conf.setMaxTaskParallelism(1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("speed-violation", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
private static Properties getProperties() {
Properties properties = new Properties();
InputStream ins = SpeedViolationTopology.class.getClassLoader().getResourceAsStream("ignite-storm.properties");
try {
properties.load(ins);
} catch (IOException e) {
e.printStackTrace();
properties = null;
}
return properties;
}
}让我们再次逐行进行。 首先,我们阅读ignite-strom.properties文件以获取所有必要的参数,然后再配置StormStreamer螺栓。 风暴拓扑基本上是一个Thrift结构。 TopologyBuilder类提供了一种简单而优雅的方法来构建复杂的Storm拓扑。 TopologyBuilder类具有setSpout和setBolt的方法。 接下来,我们使用“拓扑”构建器构建Storm拓扑,并添加了带有名称spout和1执行程序的并行提示的spout。
我们还将SpeedLimitBolt定义为具有1个执行程序的并行提示的拓扑。 接下来,我们使用shufflegrouping设置StormStreamer螺栓, shufflegrouping订阅该螺栓,并在StormStreamer螺栓的各个实例之间平均分配元组(限制)。
出于开发目的,我们使用LocalCluster实例创建本地集群,并使用SubmitTopology方法提交拓扑。 将拓扑提交到集群后,我们将等待10秒钟,等待集群计算提交的拓扑,然后使用LocalCluster的 shutdown方法关闭集群。
步骤7:
接下来,首先运行Apache Ignite或集群的本地节点。 构建maven项目后,使用以下命令在本地运行拓扑。
mvn compile exec:java -Dstorm.topology=com.blu.imdg.storm.topology.SpeedViolationTopology该应用程序将产生很多系统日志,如下所示。
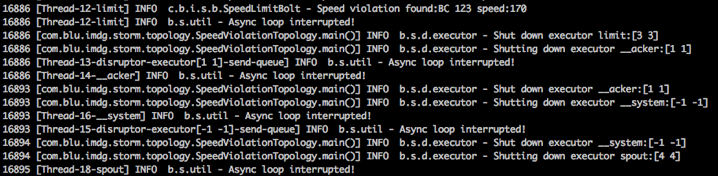
现在,如果我们通过ignitevisior验证了Ignite缓存,我们应该将以下输出输出到控制台中。

输出显示结果,这是我们期望的。 从我们的source.csv日志文件中,只有五辆车超过了120 km / h的速度限制。
这几乎是对Ignite Storm Streamer的实用概述的总结。 如果您对Ignite Camel或Ignite Flume Streamer感到好奇,请参阅“使用Apache Ignite进行高性能内存计算”一书 。 您也可以与作者联系以获取该书的免费副本,该书可以免费分发给学生和教师。
翻译自: https://www.javacodegeeks.com/2016/10/complex-event-processing-cep-apache-storm-apache-ignite.html
apache ignite

















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









