





组织机构代码输入测试用例
在编写单元测试时,我们主要关注业务的正确性。 我们将竭尽所能,开开心心地走在最前沿。 我们有时会进行微基准测试并衡量吞吐量。 但是经常遗漏的一个方面是当输入过大时我们的代码如何表现? 我们测试了如何处理正常的输入文件,格式错误的文件,空文件,丢失的文件……但是对于超大的输入文件呢?
让我们从一个真实的用例开始。 您已获得将GPX ( GPS交换格式 ,基本上为XML)实现为JSON转换的任务。 我之所以选择GPX并不是出于特殊原因,它只是您可能遇到的另一种XML格式,例如在用GPS接收器记录远足或骑自行车时。 我还认为使用XML中的一些标准而不是另一个“人员数据库”会很好。 在GPX文件中,有数百个平面<wpt/>条目,每个条目代表时空的一个点:
<gpx>
<wpt lat="42.438878" lon="-71.119277">
<ele>44.586548</ele>
<time>2001-11-28T21:05:28Z</time>
<name>5066</name>
<desc><![CDATA[5066]]></desc>
<sym>Crossing</sym>
<type><![CDATA[Crossing]]></type>
</wpt>
<wpt lat="42.439227" lon="-71.119689">
<ele>57.607200</ele>
<time>2001-06-02T03:26:55Z</time>
<name>5067</name>
<desc><![CDATA[5067]]></desc>
<sym>Dot</sym>
<type><![CDATA[Intersection]]></type>
</wpt>
<!-- ...more... -->
</gpx> 完整示例: www.topografix.com/fells_loop.gpx 。 我们的任务是提取每个单独的<wpt/>元素,丢弃没有lat或lon属性的元素,并以以下格式存储回JSON:
[
{"lat": 42.438878,"lon": -71.119277},
{"lat": 42.439227,"lon": -71.119689}
...more...
] 这很简单! 首先,我从使用JDK和GPX 1.0 XSD架构的 xjc实用程序生成JAXB类开始。 请注意,GPX 1.1是撰写本文时的最新版本,但是我得到的示例使用1.0。 对于JSON编组,我使用了Jackson 。 完整,可运行且经过测试的程序如下所示:
import org.apache.commons.io.FileUtils;
import org.codehaus.jackson.map.ObjectMapper;
import javax.xml.bind.JAXBException;
public class GpxTransformation {
private final ObjectMapper jsonMapper = new ObjectMapper();
private final JAXBContext jaxbContext;
public GpxTransformation() throws JAXBException {
jaxbContext = JAXBContext.newInstance("com.topografix.gpx._1._0");
}
public void transform(File inputFile, File outputFile) throws JAXBException, IOException {
final List<Gpx.Wpt> waypoints = loadWaypoints(inputFile);
final List<LatLong> coordinates = toCoordinates(waypoints);
dumpJson(coordinates, outputFile);
}
private List<Gpx.Wpt> loadWaypoints(File inputFile) throws JAXBException, IOException {
String xmlContents = FileUtils.readFileToString(inputFile, UTF_8);
final Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
final Gpx gpx = (Gpx) unmarshaller.unmarshal(new StringReader(xmlContents));
return gpx.getWpt();
}
private static List<LatLong> toCoordinates(List<Gpx.Wpt> waypoints) {
return waypoints
.stream()
.filter(wpt -> wpt.getLat() != null)
.filter(wpt -> wpt.getLon() != null)
.map(LatLong::new)
.collect(toList());
}
private void dumpJson(List<LatLong> coordinates, File outputFile) throws IOException {
final String resultJson = jsonMapper.writeValueAsString(coordinates);
FileUtils.writeStringToFile(outputFile, resultJson);
}
}
class LatLong {
private final double lat;
private final double lon;
LatLong(Gpx.Wpt waypoint) {
this.lat = waypoint.getLat().doubleValue();
this.lon = waypoint.getLon().doubleValue();
}
public double getLat() { return lat; }
public double getLon() { return lon; }
} 看起来还不错,尽管我故意留下了一些陷阱。 我们加载GPX XML文件,将航点提取到List ,然后将该列表转换为轻量级的LatLong对象,首先过滤掉损坏的航点。 最后,我们将List<LatLong>转储到磁盘。 然而,有一天,极其漫长的自行车骑行使我们的系统因OutOfMemoryError崩溃。 你知道发生什么了吗? 上传到我们的应用程序中的GPX文件很大,比我们预期的要大得多。 现在再看一下上面的实现,并计算在多少个地方分配了必要的内存?
但是,如果要立即进行重构,请就在此处停止! 我们想练习TDD,对吗? 我们想在代码中限制WTF /分钟因素吗? 我有一个理论,许多“ WTF”不是由粗心和缺乏经验的程序员引起的。 通常是由于这些周五晚些时候的生产问题,完全出乎意料的输入和不可预测的副作用。 代码获得了越来越多的变通办法,难以理解的重构,以及比人们预期的更复杂的逻辑。 有时不希望使用错误的代码,但是由于我们早已忘记了这种情况,因此需要使用错误的代码。 因此,如果有一天您看到不可能发生的null检查或可能已被库替换的手写代码,请考虑上下文。 话虽这么说,让我们从编写测试证明我们的未来重构开始。 如果有一天某人“固定”我们的代码,并假设“这位愚蠢的程序员”在没有充分理由的情况下使事情复杂化,那么自动化测试将准确地说明原因 。
我们的测试将仅尝试转换疯狂的大输入文件。 但是在开始之前,我们必须对原始实现进行一些重构,以使它实现InputStream和OutputStream而不是输入和输出File -没有理由将我们的实现仅限于文件系统:
步骤0a:使其可测试
import org.apache.commons.io.IOUtils;
public class GpxTransformation {
//...
public void transform(File inputFile, File outputFile) throws JAXBException, IOException {
try (
InputStream input =
new BufferedInputStream(new FileInputStream(inputFile));
OutputStream output =
new BufferedOutputStream(new FileOutputStream(outputFile))) {
transform(input, output);
}
}
public void transform(InputStream input, OutputStream output) throws JAXBException, IOException {
final List<Gpx.Wpt> waypoints = loadWaypoints(input);
final List<LatLong> coordinates = toCoordinates(waypoints);
dumpJson(coordinates, output);
}
private List<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException {
String xmlContents = IOUtils.toString(input, UTF_8);
final Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
final Gpx gpx = (Gpx) unmarshaller.unmarshal(new StringReader(xmlContents));
return gpx.getWpt();
}
//...
private void dumpJson(List<LatLong> coordinates, OutputStream output) throws IOException {
final String resultJson = jsonMapper.writeValueAsString(coordinates);
output.write(resultJson.getBytes(UTF_8));
}
}步骤0b:编写输入(压力)测试
输入将从头使用来产生repeat(byte[] sample, int times)实用程序开发较早 。 基本上,我们将重复数百万次相同的<wpt/>项,并用GPX页眉和页脚将其包装起来,以便其格式正确。 通常,我会考虑将样本放在src/test/resources ,但我希望此代码能够自我包含。 注意,我们既不在乎实际的输入,也不在乎输出。 这已经过测试。 如果转换成功(如果需要,我们可以添加一些超时),那么就可以了。 如果由于任何异常而失败,很可能是OutOfMemoryError ,则是测试失败(错误):
import org.apache.commons.io.FileUtils
import org.apache.commons.io.output.NullOutputStream
import spock.lang.Specification
import spock.lang.Unroll
import static org.apache.commons.io.FileUtils.ONE_GB
import static org.apache.commons.io.FileUtils.ONE_KB
import static org.apache.commons.io.FileUtils.ONE_MB
@Unroll
class LargeInputSpec extends Specification {
final GpxTransformation transformation = new GpxTransformation()
final byte[] header = """<?xml version="1.0"?>
<gpx
version="1.0"
creator="ExpertGPS 1.1 - http://www.topografix.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.topografix.com/GPX/1/0"
xsi:schemaLocation="http://www.topografix.com/GPX/1/0 http://www.topografix.com/GPX/1/0/gpx.xsd">
<time>2002-02-27T17:18:33Z</time>
""".getBytes(UTF_8)
final byte[] gpxSample = """
<wpt lat="42.438878" lon="-71.119277">
<ele>44.586548</ele>
<time>2001-11-28T21:05:28Z</time>
<name>5066</name>
<desc><![CDATA[5066]]></desc>
<sym>Crossing</sym>
<type><![CDATA[Crossing]]></type>
</wpt>
""".getBytes(UTF_8)
final byte[] footer = """</gpx>""".getBytes(UTF_8)
def "Should not fail with OOM for input of size #readableBytes"() {
given:
int repeats = size / gpxSample.length
InputStream xml = withHeaderAndFooter(
RepeatedInputStream.repeat(gpxSample, repeats))
expect:
transformation.transform(xml, new NullOutputStream())
where:
size << [ONE_KB, ONE_MB, 10 * ONE_MB, 100 * ONE_MB, ONE_GB, 8 * ONE_GB, 32 * ONE_GB]
readableBytes = FileUtils.byteCountToDisplaySize(size)
}
private InputStream withHeaderAndFooter(InputStream samples) {
InputStream withHeader = new SequenceInputStream(
new ByteArrayInputStream(header), samples)
return new SequenceInputStream(
withHeader, new ByteArrayInputStream(footer))
}
} 实际上,这里有7个测试,运行GPX到JSON转换以输入大小:1 KiB,1 MiB,10 MiB,100 MiB,1 GiB,8 GiB和32 GiB。 我在JDK 8u11x64上使用以下选项运行这些测试: -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xmx1g 。 1 GiB的内存很多,但显然不能容纳整个输入文件在内存中:
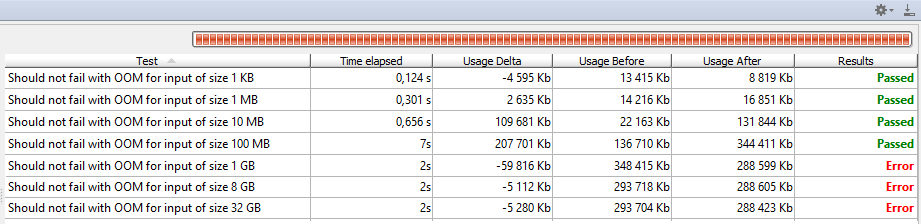
当小测试通过时,高于1 GiB的输入将快速失败。
步骤1:避免将整个文件保留在
堆栈跟踪揭示了问题所在:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3326)
at java.lang.AbstractStringBuilder.expandCapacity(AbstractStringBuilder.java:137)
at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:121)
at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:569)
at java.lang.StringBuilder.append(StringBuilder.java:190)
at org.apache.commons.io.output.StringBuilderWriter.write(StringBuilderWriter.java:138)
at org.apache.commons.io.IOUtils.copyLarge(IOUtils.java:2002)
at org.apache.commons.io.IOUtils.copyLarge(IOUtils.java:1980)
at org.apache.commons.io.IOUtils.copy(IOUtils.java:1957)
at org.apache.commons.io.IOUtils.copy(IOUtils.java:1907)
at org.apache.commons.io.IOUtils.toString(IOUtils.java:778)
at com.nurkiewicz.gpx.GpxTransformation.loadWaypoints(GpxTransformation.java:56)
at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:50) loadWaypoints急切地将input GPX文件加载到String (请参阅: IOUtils.toString(input, UTF_8) ),以便稍后对其进行解析。 这有点愚蠢,尤其是因为JAXB Unmarshaller可以轻松地直接读取InputStream 。 让我们修复它:
private List<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException {
final Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
final Gpx gpx = (Gpx) unmarshaller.unmarshal(input);
return gpx.getWpt();
}
private void dumpJson(List<LatLong> coordinates, OutputStream output) throws IOException {
jsonMapper.writeValue(output, coordinates);
} 同样,我们修复了dumpJson因为它首先将JSON转储到String ,然后将该String复制到OutputStream 。 结果略好一些,但再次出现1 GiB失败,这一次是进入Full GC的无限死亡循环并最终抛出:
java.lang.OutOfMemoryError: Java heap space
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.LeafPropertyLoader.text(LeafPropertyLoader.java:50)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallingContext.text(UnmarshallingContext.java:527)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.SAXConnector.processText(SAXConnector.java:208)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.SAXConnector.endElement(SAXConnector.java:171)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.endElement(AbstractSAXParser.java:609)
[...snap...]
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:649)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal0(UnmarshallerImpl.java:243)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal(UnmarshallerImpl.java:214)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:157)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:204)
at com.nurkiewicz.gpx.GpxTransformation.loadWaypoints(GpxTransformation.java:54)
at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:47)第2步:(不好)用StAX替换JAXB
我们可以怀疑,现在的主要问题是使用JAXB进行XML解析,JAXB总是将整个XML文件映射到Java对象中。 很难想象为什么将1 GiB文件转换为对象图会失败。 我们希望以某种方式更好地控制读取XML并将其分块使用。 传统上在这种情况下使用SAX,但是SAX API中的推式编程模型非常不便。 SAX使用回调机制,该机制具有很高的侵入性,并且不易读。 StAX(用于XML的流API)在更高级别上工作,公开了拉模型。 这意味着客户代码决定何时以及消耗多少输入。 这使我们可以更好地控制输入,并具有更大的灵活性。 为了使您熟悉该API,以下代码几乎等同于loadWaypoints() ,但是我跳过了<wpt/>属性,这些属性以后不再需要:
private List<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException, XMLStreamException {
final XMLInputFactory factory = XMLInputFactory.newInstance();
final XMLStreamReader reader = factory.createXMLStreamReader(input);
final List<Gpx.Wpt> waypoints = new ArrayList<>();
while (reader.hasNext()) {
switch (reader.next()) {
case XMLStreamConstants.START_ELEMENT:
if (reader.getLocalName().equals("wpt")) {
waypoints.add(parseWaypoint(reader));
}
break;
}
}
return waypoints;
}
private Gpx.Wpt parseWaypoint(XMLStreamReader reader) {
final Gpx.Wpt wpt = new Gpx.Wpt();
final String lat = reader.getAttributeValue("", "lat");
if (lat != null) {
wpt.setLat(new BigDecimal(lat));
}
final String lon = reader.getAttributeValue("", "lon");
if (lon != null) {
wpt.setLon(new BigDecimal(lon));
}
return wpt;
} 看看我们如何明确地向XMLStreamReader请求更多数据? 然而事实是,我们正在使用更多的低级别的API( 和更大量的代码),并不意味着它必须是更好的,如果使用不当。 我们一直在构建庞大的waypoints列表,因此再次看到OutOfMemoryError也就不足为奇了:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3204)
at java.util.Arrays.copyOf(Arrays.java:3175)
at java.util.ArrayList.grow(ArrayList.java:246)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:220)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:212)
at java.util.ArrayList.add(ArrayList.java:443)
at com.nurkiewicz.gpx.GpxTransformation.loadWaypoints(GpxTransformation.java:65)
at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:52)正是我们所期望的。 好消息是,1个吉布测试通过(1个吉布堆),所以我们有几分在正确的方向前进。 但是由于GC过多,需要1分钟才能完成。
步骤3:正确实施StAX
注意,在上一个示例中使用StAX的实现与SAX一样好。 但是,我选择StAX的原因是我们现在可以将XML文件转换为Iterator<Gpx.Wpt> 。 该迭代器仅在被询问时才懒散地使用XML文件。 以后我们也可以延迟使用该迭代器,这意味着我们不再将整个文件保留在内存中。 迭代器虽然笨拙,但是比直接使用XML或使用SAX回调要好得多:
import com.google.common.collect.AbstractIterator;
private Iterator<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException, XMLStreamException {
final XMLInputFactory factory = XMLInputFactory.newInstance();
final XMLStreamReader reader = factory.createXMLStreamReader(input);
return new AbstractIterator<Gpx.Wpt>() {
@Override
protected Gpx.Wpt computeNext() {
try {
return tryPullNextWaypoint();
} catch (XMLStreamException e) {
throw Throwables.propagate(e);
}
}
private Gpx.Wpt tryPullNextWaypoint() throws XMLStreamException {
while (reader.hasNext()) {
int event = reader.next();
switch (event) {
case XMLStreamConstants.START_ELEMENT:
if (reader.getLocalName().equals("wpt")) {
return parseWaypoint(reader);
}
break;
case XMLStreamConstants.END_ELEMENT:
if (reader.getLocalName().equals("gpx")) {
return endOfData();
}
break;
}
}
throw new IllegalStateException("XML file didn't finish with </gpx> element, malformed?");
}
};
} 这变得越来越复杂! 我正在使用来自Guava的AbstractIterator来处理乏味的hasNext()状态。 每当有人尝试从迭代器中提取下一个Gpx.Wpt项(或调用hasNext() )时,我们都会消耗一点XML,足以返回一个条目。 如果XMLStreamReader遇到XML的结尾( </gpx>标记),我们将通过返回endOfData()通知迭代器结束。 这是一个非常方便的模式,其中XML被懒惰地读取并通过方便的迭代器提供服务。 仅此实现就消耗很少的,恒定的内存量。 但是,我们将API从List<Gpx.Wpt>更改为Iterator<Gpx.Wpt> ,这将强制更改其余实现:
private static List<LatLong> toCoordinates(Iterator<Gpx.Wpt> waypoints) {
final Spliterator<Gpx.Wpt> spliterator =
Spliterators.spliteratorUnknownSize(waypoints, Spliterator.ORDERED);
return StreamSupport
.stream(spliterator, false)
.filter(wpt -> wpt.getLat() != null)
.filter(wpt -> wpt.getLon() != null)
.map(LatLong::new)
.collect(toList());
} toCoordinates()以前接受List<Gpx.Wpt> 。 迭代器无法直接转换为Stream ,因此我们需要通过Spliterator笨拙的转换。 你认为结束了吗? ! GiB测试通过得更快一些,但要求更高的测试却像以前一样失败了:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3175)
at java.util.ArrayList.grow(ArrayList.java:246)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:220)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:212)
at java.util.ArrayList.add(ArrayList.java:443)
at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175)
at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175)
at java.util.Iterator.forEachRemaining(Iterator.java:116)
at java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:512)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:502)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at com.nurkiewicz.gpx.GpxTransformation.toCoordinates(GpxTransformation.java:118)
at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:58)
at com.nurkiewicz.LargeInputSpec.Should not fail with OOM for input of size #readableBytes(LargeInputSpec.groovy:49) 请记住,并非总是从实际上消耗大量内存的地方抛出OutOfMemoryError 。 幸运的是,这次并非如此。 仔细查看底部: collect(toList()) 。
步骤4:避免流和收集器
这真令人失望。 溪流和收集器的设计完全是为了支持懒惰。 但是,实际上不可能有效地实现从流到迭代器的收集器(另请参见: Java 8中编写自定义收集器以及分组,采样和批处理–自定义收集器的简介 ),这是一个很大的设计缺陷。 因此,我们必须完全忘记流,并一直使用简单的迭代器。 迭代器不是很优雅,但是可以逐项消耗输入,可以完全控制内存消耗。 我们需要一种方法filter()输入迭代器,丢弃损坏的项并将map()条目map()到另一个表示形式。 番石榴再次提供了一些方便的实用程序,完全替换了stream() :
private static Iterator<LatLong> toCoordinates(Iterator<Gpx.Wpt> waypoints) {
final Iterator<Gpx.Wpt> filtered = Iterators
.filter(waypoints, wpt ->
wpt.getLat() != null &&
wpt.getLon() != null);
return Iterators.transform(filtered, LatLong::new);
} Iterator<Gpx.Wpt>在, Iterator<LatLong>出。 没有进行任何处理,几乎没有触及XML文件,几乎没有内存消耗。 幸运的是,Jackson接受了迭代器并透明地读取它们,从而迭代生成JSON。 因此,存储器消耗也保持较低。 猜猜是什么,我们做到了!
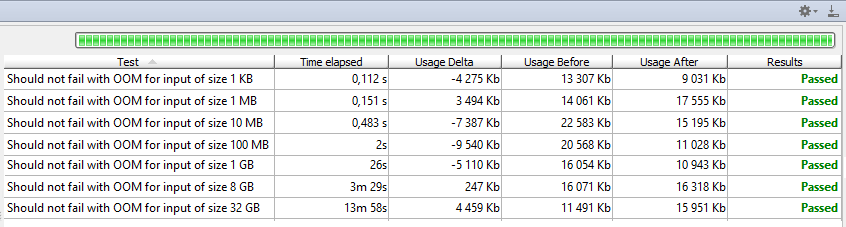
内存消耗低且稳定,我认为我们可以放心地假设它是恒定的。 我们的代码处理速度约为40 MiB / s,因此处理32 GiB大约需要14分钟,不要感到惊讶。 哦,我是否提到我使用-Xmx32M运行了最后一个测试? 没错,使用较少的数千倍内存即可成功处理32 GiB,而不会造成任何性能损失。 与最初实施相比,减少了3000倍。 事实上,最后一个使用迭代器的解决方案甚至能够处理无限的XML流。 这实际上不只是理论上的情况,想象一下某种流API会产生永无止境的消息流…
最终实施
这是我们完整的代码:
package com.nurkiewicz.gpx;
import com.google.common.base.Throwables;
import com.google.common.collect.AbstractIterator;
import com.google.common.collect.Iterators;
import com.topografix.gpx._1._0.Gpx;
import org.codehaus.jackson.map.ObjectMapper;
import javax.xml.bind.JAXBException;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamException;
import javax.xml.stream.XMLStreamReader;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.math.BigDecimal;
import java.util.Iterator;
public class GpxTransformation {
private static final ObjectMapper jsonMapper = new ObjectMapper();
public void transform(File inputFile, File outputFile) throws JAXBException, IOException, XMLStreamException {
try (
InputStream input =
new BufferedInputStream(new FileInputStream(inputFile));
OutputStream output =
new BufferedOutputStream(new FileOutputStream(outputFile))) {
transform(input, output);
}
}
public void transform(InputStream input, OutputStream output) throws JAXBException, IOException, XMLStreamException {
final Iterator<Gpx.Wpt> waypoints = loadWaypoints(input);
final Iterator<LatLong> coordinates = toCoordinates(waypoints);
dumpJson(coordinates, output);
}
private Iterator<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException, XMLStreamException {
final XMLInputFactory factory = XMLInputFactory.newInstance();
final XMLStreamReader reader = factory.createXMLStreamReader(input);
return new AbstractIterator<Gpx.Wpt>() {
@Override
protected Gpx.Wpt computeNext() {
try {
return tryPullNextWaypoint();
} catch (XMLStreamException e) {
throw Throwables.propagate(e);
}
}
private Gpx.Wpt tryPullNextWaypoint() throws XMLStreamException {
while (reader.hasNext()) {
int event = reader.next();
switch (event) {
case XMLStreamConstants.START_ELEMENT:
if (reader.getLocalName().equals("wpt")) {
return parseWaypoint(reader);
}
break;
case XMLStreamConstants.END_ELEMENT:
if (reader.getLocalName().equals("gpx")) {
return endOfData();
}
break;
}
}
throw new IllegalStateException("XML file didn't finish with </gpx> element, malformed?");
}
};
}
private Gpx.Wpt parseWaypoint(XMLStreamReader reader) {
final Gpx.Wpt wpt = new Gpx.Wpt();
final String lat = reader.getAttributeValue("", "lat");
if (lat != null) {
wpt.setLat(new BigDecimal(lat));
}
final String lon = reader.getAttributeValue("", "lon");
if (lon != null) {
wpt.setLon(new BigDecimal(lon));
}
return wpt;
}
private static Iterator<LatLong> toCoordinates(Iterator<Gpx.Wpt> waypoints) {
final Iterator<Gpx.Wpt> filtered = Iterators
.filter(waypoints, wpt ->
wpt.getLat() != null &&
wpt.getLon() != null);
return Iterators.transform(filtered, LatLong::new);
}
private void dumpJson(Iterator<LatLong> coordinates, OutputStream output) throws IOException {
jsonMapper.writeValue(output, coordinates);
}
}摘要(TL; DR)
如果您没有足够的耐心执行所有步骤,则可以参考以下三点:
- 您的首要目标是简单 。 最初的JAXB实现非常好(进行了少量修改),如果您的代码不必处理大量输入,则应保持这种状态。
- 针对超大型输入 (例如,使用生成的
InputStream)生成千兆字节的输入,以测试您的代码 。 巨大的数据集是边缘情况的另一个例子。 一次不要手动测试。 一不小心的更改或“改进”可能会破坏您的性能。 - 优化不是编写不良代码的借口 。 注意,我们的实现仍然是可组合的,并且易于遵循。 如果我们通过SAX并简单地内联SAX回调中的所有逻辑,则可维护性将受到极大影响。
翻译自: https://www.javacodegeeks.com/2014/08/testing-code-for-excessively-large-inputs.html
组织机构代码输入测试用例















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









