





 本文探讨如何利用增量编码优化字节数组到二进制的转换,尤其针对低方差、单调的浮点数集。这种方法在高频交易系统的市场数据消息序列化中,能显著降低延迟和提高空间效率。
本文探讨如何利用增量编码优化字节数组到二进制的转换,尤其针对低方差、单调的浮点数集。这种方法在高频交易系统的市场数据消息序列化中,能显著降低延迟和提高空间效率。
字节数组转为二进制数 c#
低延迟系统需要高性能的消息处理和传递。 由于在大多数情况下,数据必须通过有线传输或序列化才能保持持久性,因此编码和解码消息已成为处理管道的重要组成部分。 高性能数据编码的最佳结果通常涉及应用程序数据细节的知识。 本文介绍的技术是一个很好的示例,说明了如何利用数据的某些方面在延迟和空间复杂度方面都有利于编码。
通常,高频交易系统周围传递的最大消息以订单簿摘录的形式表示某种交换状态。 即,典型的市场数据(报价)消息包含标识工具的信息和代表订单簿顶部的一组值。 数据集的强制性成员是以实数表示的价格/汇率信息(用于买卖双方)。
从优化的角度来看,使该数据集非常有趣的原因是:
- 单调的
- 低方差
- 非负*
因此,在实践中,我们处理的是浮点数集,这些浮点数不仅经过排序(升序出价和降价要求),而且相邻值彼此相对“接近”。 请记住,消息处理延迟对于大多数交易系统而言至关重要,因此市场行情波动,因为关键实体之一需要尽可能高效地传递。
让我演示如何利用所有这些功能将数字数据编码为非常紧凑的二进制形式。 首先,两个前导图说明了不同序列化方法之间的差异:
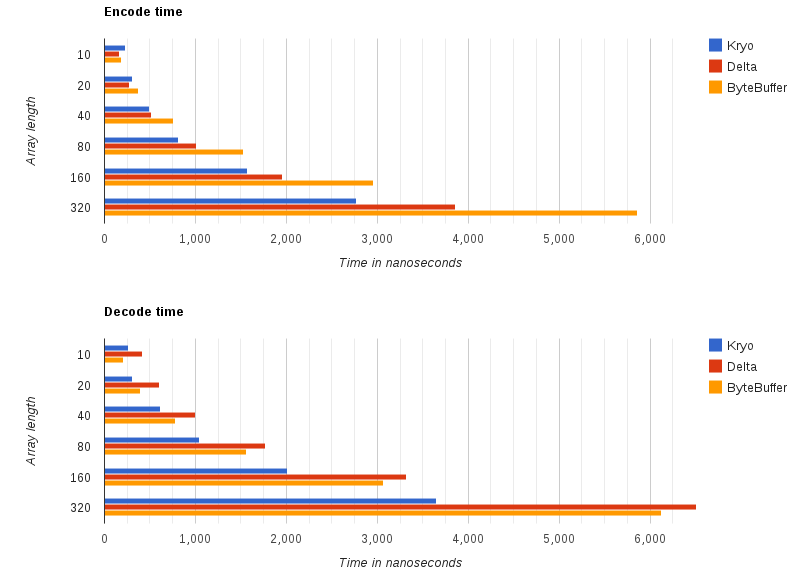
到目前为止,我们可以看到,与基于标准ByteBuffer的序列化相比,增量编码在编码时间上可获得更好的结果,但是一旦数组长度超过40,它就会比Kryo (最流行的高性能序列化库之一)更差。不过,在这里重要的是一个典型的用例场景,对于高频交易,市场消息恰好适合阵列长度的10-40
当我们检查生成的消息大小(作为数组长度的函数)时,它会变得更加有趣:
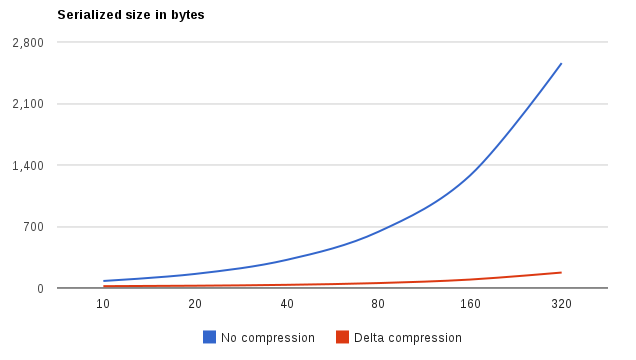
此时,应用增量编码的好处将变得显而易见(蓝色曲线同样适用于字节缓冲区和Kryo序列化)。 这里发生的是,在掌握了一些有关要处理的数据的特定知识之后,可以安全地进行假设,从而导致序列化占用更多的CPU资源,但是在空间方面却要荒唐得多。 增量压缩背后的想法非常简单。 让我们从一个整数数组开始:
- [85103、85111、85122、85129、85142、85144、85150、85165、85177]
如果这些是整数,则不进行任何压缩就必须使用4 * 9 = 36字节来存储数据。 在这组数字中,特别有趣的是,它们彼此相对紧密地聚集在一起。 我们可以通过引用第一个值轻松地减少存储数据所需的字节数,然后生成一个对应的增量数组:
- 参考:85103,[8、19、26、39、41、47、62、74]
哇! 现在我们可以缩小为字节数组。 让我们再次进行计算。 我们需要4个字节作为参考值(仍为int),每个增量= 8 * 1个字节= 12个字节。
与原始的36个字节相比,这是一个很大的改进,但仍有一些优化的余地。 与其从参考值计算增量,不如依次存储每个前任的差异:
- 参考:85103,[8、11、7、13、2、6、15、12]
结果是一组具有低方差和标准偏差的非单调数字。 我希望事情已经明确了。 尽管如此,还是值得详细说明。
至此,我们最终得到的是一组二进制编码的理想选择。 对于我们的示例,这仅意味着可以在单个字节中容纳2个增量。 我们只需要一个半字节(4位)即可容纳0-15范围内的值,因此我们可以轻松地最终将原始数组压缩为4(供参考)+ 8 * 1/2 = 8个字节。
由于价格是用十进制数字表示的,因此应用带有二进制编码的增量压缩将涉及建立最大支持的精度并将小数作为整数(将它们乘以10 ^精度),从而使精度为6的1.12345678成为1123456整数。 到目前为止,所有这些都是纯粹的理论推测,本文开头有一些预告片。 我想这是演示如何使用2个非常简单的类在Java中实现这些想法的恰当时机。
我们将从编码方面开始:
package eu.codearte.encoder;
import java.nio.ByteBuffer;
import static eu.codearte.encoder.Constants.*;
public class BinaryDeltaEncoder {
public static final int MAX_LENGTH_MASK = ~(1 << (LENGTH_BITS - 1));
public ByteBuffer buffer;
public double[] doubles;
public int[] deltas;
public int deltaSize, multiplier, idx;
public void encode(final double[] values, final int[] temp, final int precision, final ByteBuffer buf) {
if (precision >= 1 << PRECISION_BITS) throw new IllegalArgumentException();
if ((values.length & MAX_LENGTH_MASK) != values.length) throw new IllegalArgumentException();
doubles = values; deltas = temp; buffer = buf;
multiplier = Utils.pow(10, precision);
calculateDeltaVector();
if (deltaSize > DELTA_SIZE_BITS) throw new IllegalArgumentException();
buffer.putLong((long) precision << (LENGTH_BITS + DELTA_SIZE_BITS) | (long) deltaSize << LENGTH_BITS | values.length);
buffer.putLong(roundAndPromote(values[0]));
idx = 1;
encodeDeltas();
}
private void calculateDeltaVector() {
long maxDelta = 0, currentValue = roundAndPromote(doubles[0]);
for (int i = 1; i < doubles.length; i++) {
deltas[i] = (int) (-currentValue + (currentValue = roundAndPromote(doubles[i])));
if (deltas[i] > maxDelta) maxDelta = deltas[i];
}
deltaSize = Long.SIZE - Long.numberOfLeadingZeros(maxDelta);
}
private void encodeDeltas() {
if (idx >= doubles.length) return;
final int remainingBits = (doubles.length - idx) * deltaSize;
if (remainingBits >= Long.SIZE || deltaSize > Integer.SIZE) buffer.putLong(encodeBits(Long.SIZE));
else if (remainingBits >= Integer.SIZE || deltaSize > Short.SIZE) buffer.putInt((int) encodeBits(Integer.SIZE));
else if (remainingBits >= Short.SIZE || deltaSize > Byte.SIZE) buffer.putShort((short) encodeBits(Short.SIZE));
else buffer.put((byte) encodeBits(Byte.SIZE));
encodeDeltas();
}
private long encodeBits(final int typeSize) {
long bits = 0L;
for (int pos = typeSize - deltaSize; pos >= 0 && idx < deltas.length; pos -= deltaSize)
bits |= (long) deltas[idx++] << pos;
return bits;
}
private long roundAndPromote(final double value) {
return (long) (value * multiplier + .5d);
}
}在详细介绍之前,请先介绍几句话。 该代码不是完整的,成熟的解决方案。 它的唯一目的是演示提高应用程序序列化协议的某些位的难易程度。 由于它受到了微基准测试,因此它也不会引起gc压力,因为即使是最快的次要gc的影响也会严重扭曲最终结果,从而使api变得丑陋。 该实现也是次优的,尤其是在CPU方面,但是证明微优化不是本文的目标。 话虽如此,让我们看看它的作用(大括号中的行号)。
编码方法首先进行一些基本的健全性检查{17,18},计算将十进制转换为整数{20}所使用的乘数,并计算calculateDeltaVector()。 这又有两个作用。
- 通过将小数转换为整数,从前任减去,最后将结果存储在临时数组{33}中,计算整个集合的滚动增量
- 作为副作用,得出表示增量{34,36}所需的最大位数
然后,encode()方法存储正确反序列化所需的一些元数据。 它以位为单位打包精度,增量大小,并以前64位{24}打包数组长度。 然后,它存储参考值{25}并启动二进制编码{27}。
编码增量执行以下操作:
- 检查它是否已经处理了所有数组条目,如果已退出则退出{40}
- 计算要编码的剩余位数{41}
- 选择最合适的类型(给定大小,以位为单位),对剩余的位进行编码,然后将这些位写入缓冲区{43-46}
- 递归{47}
最后一点可能需要详细说明是encodeBits()方法本身。 根据在参数中传递的类型大小(以位为单位),它循环一个临时long,其唯一目的是充当位集,并写入代表从long值的最高有效部分到最低有效部分的连续增量的位(范围为字号)。
正如预期的那样,解码与编码完全相反,并且主要是关于使用元数据来重建原始double数组,直至达到指定的精度:
package eu.codearte.encoder;
import java.nio.ByteBuffer;
import static eu.codearte.encoder.Constants.DELTA_SIZE_BITS;
import static eu.codearte.encoder.Constants.LENGTH_BITS;
public class BinaryDeltaDecoder {
private ByteBuffer buffer;
private double[] doubles;
private long current;
private double divisor;
private int deltaSize, length, mask;
public void decode(final ByteBuffer buffer, final double[] doubles) {
this.buffer = buffer; this.doubles = doubles;
final long bits = this.buffer.getLong();
divisor = Math.pow(10, bits >>> (LENGTH_BITS + DELTA_SIZE_BITS));
deltaSize = (int) (bits >>> LENGTH_BITS) & 0x3FFFFFF;
length = (int) (bits & 0xFFFFFFFF);
doubles[0] = (current = this.buffer.getLong()) / divisor;
mask = (1 << deltaSize) - 1;
decodeDeltas(1);
}
private void decodeDeltas(final int idx) {
if (idx == length) return;
final int remainingBits = (length - idx) * deltaSize;
if (remainingBits >= Long.SIZE) decodeBits(idx, buffer.getLong(), Long.SIZE);
else if (remainingBits >= Integer.SIZE) decodeBits(idx, buffer.getInt(), Integer.SIZE);
else if (remainingBits >= Short.SIZE) decodeBits(idx, buffer.getShort(), Short.SIZE);
else decodeBits(idx, buffer.get(), Byte.SIZE);
}
private void decodeBits(int idx, final long bits, final int typeSize) {
for (int offset = typeSize - deltaSize; offset >= 0 && idx < length; offset -= deltaSize)
doubles[idx++] = (current += ((bits >>> offset) & mask)) / divisor;
decodeDeltas(idx);
}
} 带有一些测试类的源代码可以在这里找到。 请记住,即使事实证明该代码可以正常工作,也不适合生产。 您绝对可以使它工作而无需临时数组,用聪明的方法代替最大数组大小时替换全数组扫描,或者通过进行倒数近似除以重量级除法就可以摆脱困境。 随意选择这些提示或应用不同的微优化,并构建自己的专有增量编码协议。 对于对延迟敏感的交易应用程序而言,它具有很大的区别,可将液体工具的市场数据消息大小减小20-30倍。 当然,如果切换到增量压缩二进制编码会对您的应用程序生态系统带来任何价值,那么您必须弄清楚自己。 随便发表评论与您的发现!
字节数组转为二进制数 c#
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









