









论文地址:链接
https://arxiv.org/abs/2308.02236
FB-BEV: BEV Representation from Forward-Backward View Transformations
本文是一篇关于Bird-Eye-View(BEV)视觉识别的研究论文。BEV视觉识别是一种在自动驾驶领域广泛使用的技术,用于识别和定位路面上的物体。论文提出的方法称为Forward-Backward View Transformation(FB-BEV),是一种结合了前向和反向投影的方法,以解决现有的BEV视觉识别方法的局限性(BEV 特征稀疏或由于投影不准确而导致假阳性特征)。
相关工作
前向投影方法
- Lift-Splat-Shoot (LSS):利用深度分布投影多视图特征到BEV空间。
- BEVDet:将前向投影应用于多视图3D检测领域。
- CaDDN和BEVDepth:利用LiDAR点云生成深度真值用于监督深度预测模块,其中BEVDepth展示了准确的深度预测模块显著提升模型性能的重要性。
- MatrixVT:专注于提高BEV生成过程中的计算效率,而不是单纯的稠密化BEV特征。
反向投影方法
- OFT:初期的反向投影方法之一。
- BEVFormer:使用伪装采样点和时序特征进行多视图感知,不引入体素化的表示,从而减少资源消耗。
- BEVFormerV2:将现代图像骨干网络(Backbone)适配于BEV感知。
- PolarFormer和PolarDETR:采用极坐标进行投影,减少空间感知中的不确定性。
- PersFormer :使用逆透视映射(IPM)来引导图像空间上的投影点。
无投影方法
- PETR和PETRv2:通过全局注意力机制隐式地学习视图变换。
- CFT:利用视图感知注意力自适应地学习每个视图所需的BEV特征,无需依赖相机校准参数。
- BEVSegFormer :自动学习3D和2D空间之间的对应关系,而不依赖于投影过程。
现有的BEV视觉识别方法可以分为两类:前向投影和反向投影。
前向投影方法通过估计每个像素的深度值并使用相机标定参数来确定每个像素在3D空间中的位置。
这种方法的优点是可以生成稀疏的BEV特征,但缺点是难以准确估计每个像素的深度值。
反向投影方法则是通过定义3D空间中的体素位置并将其投影到2D图像上来生成BEV特征。
这种方法的优点是可以生成稠密的BEV特征,但缺点是难以准确地确定体素的位置。
为了解决上述问题,本文提出的FB-BEV方法通过结合前向和反向投影来生成稠密的BEV特征。
具体来说,FB-BEV方法首先使用前向投影生成一个稀疏的BEV特征,然后使用反向投影来填充空白的BEV网格。通过这种方法,FB-BEV可以同时利用前向和反向投影的优点,生成高质量的BEV特征。
为了克服现有视图变换模块的局限性,本文提出了一种新型的前向-反向视图变换方法FB-BEV,主要包括三个关键模块:
- 前向投影模块 (F-VTM):生成初始稀疏的BEV表示。
- 遵循LSS的范式,分别进行Lift和Splat操作,将2D图像中的每个像素特征投影到3D体素空间,并聚合特征值。
- 前景区域建议网络 (FRPN):选择前景BEV网格进行优化。
- 生成的BEV特征较为稀疏,通过简单的分割网络生成二分掩码,仅提取感兴趣的前景BEV网格RoI进行后续优化。
- 深度感知反向投影模块 (B-VTM):对前景BEV网格进行优化。Depth-Aware(based on the spatial cross-attention in BEVFormer)
- 提出深度一致性机制,通过计算3D点和其对应2D投影点间的深度一致性,改进投影质量。引入深度一致性的反向投影方法可以生成辨别力更强的BEV特征,同时保证以任意分辨率稠密填充3D空间。
方法

-
首先从 2D 主干提取多视图特征,并使用深度网络Depth Net生成深度分布D。
-
然后使用前向投影模块F-VTM来生成 BEV 特征 𝐵 (含空白网格)。前景区域建议网络FRPN 生成前景掩模并将前景感兴趣区域 (RoI) 网格馈送到下一个深度感知反向投影模块 (Grids { 𝑎 , 𝑏 , 𝑐 , 𝑑 } 图中)。
-
深度感知反向投影模块B-VTM使用 RoI 网格作为 BEV 查询,并通过使用深度一致性机制将它们投影回图像来细化这些查询。最后,我们得到了BEV特征 𝐵 ′ 。
-
深度感知反向投影基于 BEVFormer 中的空间交叉注意力。利用本文的深度一致性,我们可以通过以下方式直接将 SCA 演变成深度感知 SCA (SCA da ):
S C A d a ( Q x , y , F ) = ∑ i = 1 N c ∑ j = 1 N r e f F d ( Q x , y , P i ( x , y , z j ) , F i ) ⋅ w c i j \mathrm{SCA}_{da}(Q_{x,y},F)=\sum\limits_{i = 1}^{N_{\mathrm{c}}}\sum\limits_{j = 1}^{N_{\mathrm{ref}}}\mathcal{F}_{d}(Q_{x, y},\mathcal{P}_{i}(x,y,z_{j}),F_{i})\cdot\boldsymbol{w}_{c}^{ij} SCAda(Qx,y,F)=i=1∑Ncj=1∑NrefFd(Qx,y,Pi(x,y,zj),Fi)⋅wcij
w c i j {w}_{c}^{ij} wcij是3D点 ( x , y , z j z_{j} zj ) 和 2D 点 ( u i , v i )之间的深度一致性
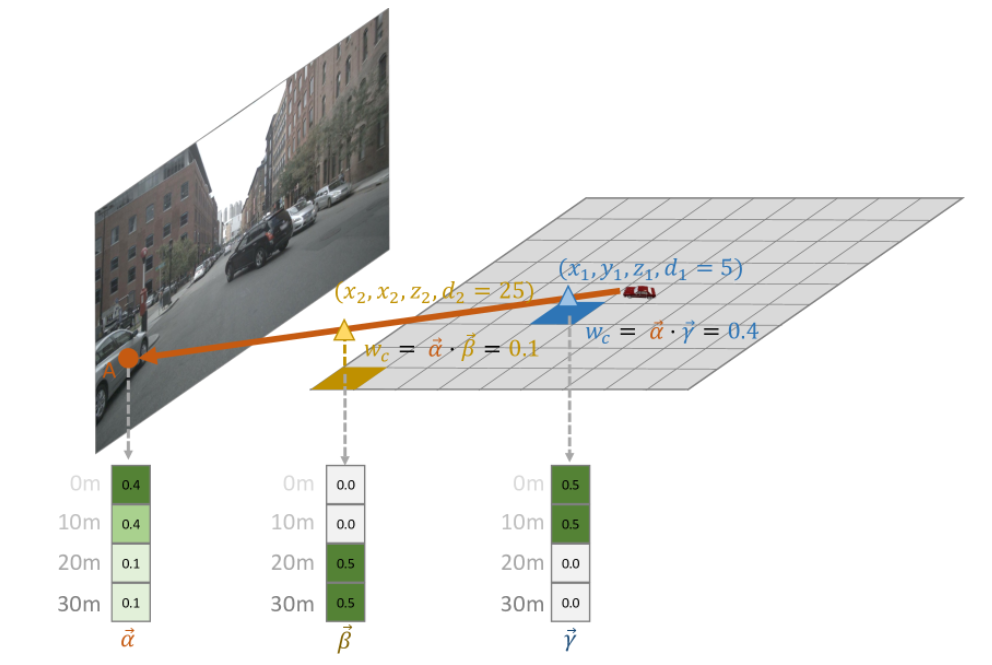
深度一致性可以计算为 𝛼 → ⋅ 𝛾 → = 0.4 和 𝛼 → ⋅ 𝛽 → = 0.1 。较近的点 ( 𝑥 1 , 𝑦 1 , 𝑧 1 ) 从而拥有更高的特征权重和更高的一致性。(深度一致性与正向投影中的深度权重具有类似的作用)
-
整体架构
- 多视图的2D骨干网生成图像特征。
- 深度网络生成深度分布。
- 前向投影模块生成BEV特征B。
- 前景区域建议网络生成前景蒙版,并提取前景BEV网格。
- 通过深度感知反向投影模块优化前景BEV网格,得到最终的BEV特征B’。
- 基于BEV特征B’进行3D检测。
实验
- 默认使用ResNet-50,并且每个图像大小为256x704。训练过程中,采用CBGS策略,并且在图像和BEV都进行数据增强,包括:随机缩放、反转、旋转。默认情况,我们模型训练20个epoch,使用的batchsize为64,并且采用AdamW作为优化器,初始学习率为2e-4。
- FB-BEV方法在nuScenes val数据集上的3D检测结果,以及和两个方法BEVDet和BEVFormer的对比。在不使用时间信息或深度监控的情况下,我们的方法以 2.4% NDS 和 2.7% NDS 的显著优势优于 BEVDet 和 BEVFormer。
- 消融实验: 我们比较了在 FB-BEV 和 BEVFormer 中采用深度感知后向投影的结果。采用深度感知投影后,BEVFormer 的 NDS 得分提高了 0.9%。
结论
本文提出一种前后投影模式,解决当下投影方法的种种不足——通过解决前向投影生成的稀疏特征,以及在反向投影中引入深度信息,构建了一个更加准确的投影关系。这两个阶段的视图转换模块,适合更高分辨率的BEV特征表示,并且可以应用于超长距离的目标监测或高分辨率的占据感知。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









