







本文主要介绍本地模式下实时流测试环境的搭建,这里主要采用Storm+Kafka+Zookeeper架构,具体步骤如下:
- 安装启动Zookeeper,具体步骤见我之前转载的博客http://blog.csdn.net/do_yourself_go_on/article/details/73930809
- 安装启动Kafka,具体步骤见我之前转载的博客http://blog.csdn.net/do_yourself_go_on/article/details/73930438;
这一步中还需要完成这样两件事:
(1)首先创建一个topic,这里我创建了一个topic,名字为firstTopic
(2)启动一个Producer,为了后面实时产生数据并进行单词统计测试 编写Storm的单词计数测试程序
(1)首先贴出pom.xml文件代码:<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.stromdemo</groupId> <artifactId>StormDemo</artifactId> <version>1.0-SNAPSHOT</version> <packaging>jar</packaging> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <!-- see comment below... This fixes an annoyance with intellij --> <provided.scope>provided</provided.scope> </properties> <profiles> <profile> <id>intellij</id> <properties> <provided.scope>compile</provided.scope> </properties> </profile> </profiles> <repositories> <!-- Repository where we can found the storm dependencies --> <repository> <id>clojars.org</id> <url>http://clojars.org/repo</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <!-- 这里的版本号必须和集群中的storm版本保持一致--> <version>1.1.0</version> <!-- U当打包时,不能把storm打进去,必须是provided。而在本地开发调试时必须将该行去掉。ctrl + / --> <!--<scope>${provided.scope}</scope>--> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka</artifactId> <version>1.1.0</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.10.2.0</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <!-- 保证打包时有入口函数 --> <archive> <manifest> <mainClass>com.kafka.MyKafkaTopology</mainClass> </manifest> </archive> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> </plugins> </build> </project>(2)然后是基于kafka整合的单词计数程序:
package com.kafka;
import org.apache.log4j.Logger;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.kafka.*;
import org.apache.storm.spout.SchemeAsMultiScheme;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
/**
* Created by Administrator on 2017/6/29.
*/
public class MyKafkaTopology {
public static class KafkaWordSplitter extends BaseRichBolt {
private static final Logger LOG = Logger.getLogger(KafkaWordSplitter.class);
private static final long serialVersionUID = 886149197481637894L;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String line = input.getString(0);
LOG.info("RECV[kafka -> splitter] " + line);
String[] words = line.split("\\s+");
for(String word : words) {
LOG.info("EMIT[splitter -> counter] " + word);
collector.emit(input, new Values(word, 1));
}
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
public static class WordCounter extends BaseRichBolt {
private static final Logger LOG = Logger.getLogger(WordCounter.class);
private static final long serialVersionUID = 886149197481637894L;
private OutputCollector collector;
private Map<String, AtomicInteger> counterMap;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
this.counterMap = new HashMap<String, AtomicInteger>();
}
@Override
public void execute(Tuple input) {
String word = input.getString(0);
int count = input.getInteger(1);
LOG.info("RECV[splitter -> counter] " + word + " : " + count);
AtomicInteger ai = this.counterMap.get(word);
if(ai == null) {
ai = new AtomicInteger();
this.counterMap.put(word, ai);
}
ai.addAndGet(count);
System.out.printf("%s\t%d\n", word, ai.intValue());
collector.ack(input);
LOG.info("CHECK statistics map: " + this.counterMap);
}
@Override
public void cleanup() {
LOG.info("The final result:");
Iterator<Map.Entry<String, AtomicInteger>> iter = this.counterMap.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry<String, AtomicInteger> entry = iter.next();
LOG.info(entry.getKey() + "\t:\t" + entry.getValue().get());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException, InterruptedException, AuthorizationException {
String zks = "localhost:2181";
String topic = "firstTopic";
//在Zookeeper根目录下面创建一个kafka文件夹,然后创建kafka分区时候也要定位到此文件夹,即--zookeeper localhose:2181/kafka,不然可能会报错误:org.apache.zookeeper.KeeperException$NoNodeException
KeeperErrorCode = NoNode
String zkRoot = "/kafka";
String id = "word";
BrokerHosts brokerHosts = new ZkHosts(zks);
SpoutConfig spoutConf = new SpoutConfig(brokerHosts, topic, zkRoot, id);
//这一句话一定要写,不然解析kafka中数据会出错:java.lang.RuntimeException: java.lang.ClassCastException: [B cannot be cast to java.lang.String
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
//spoutConf.forceFromStart = false;
spoutConf.zkServers = Arrays.asList(new String[] {"localhost"});
spoutConf.zkPort = 2181;
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-reader", new KafkaSpout(spoutConf), 1); // Kafka我们创建了一个1分区的Topic,这里并行度设置为1
builder.setBolt("word-splitter", new KafkaWordSplitter(), 1).shuffleGrouping("kafka-reader");
builder.setBolt("word-counter", new WordCounter()).fieldsGrouping("word-splitter", new Fields("word"));
Config conf = new Config();
String name = MyKafkaTopology.class.getSimpleName();
if (args != null && args.length > 0) {
// Nimbus host name passed from command line
//conf.put(Config.NIMBUS_HOST, args[0]);
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(name, conf, builder.createTopology());
} else {
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(name, conf, builder.createTopology());
//Thread.sleep(60000);
//cluster.shutdown();
}
}
}
运行程序,在Producer命令窗里面输入数据,单词计数程序会实时统计出来每个单词的数量,如下图所示:
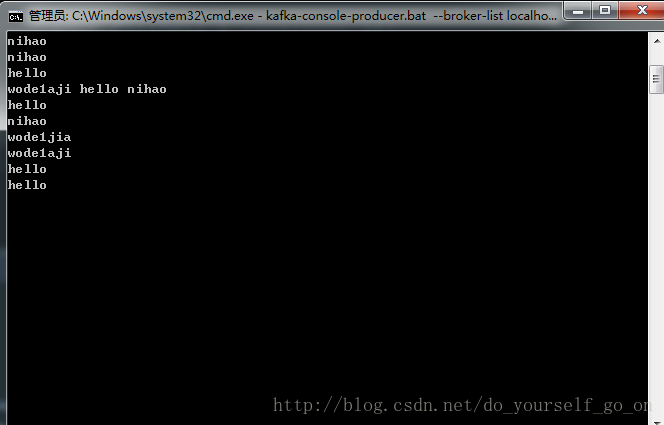
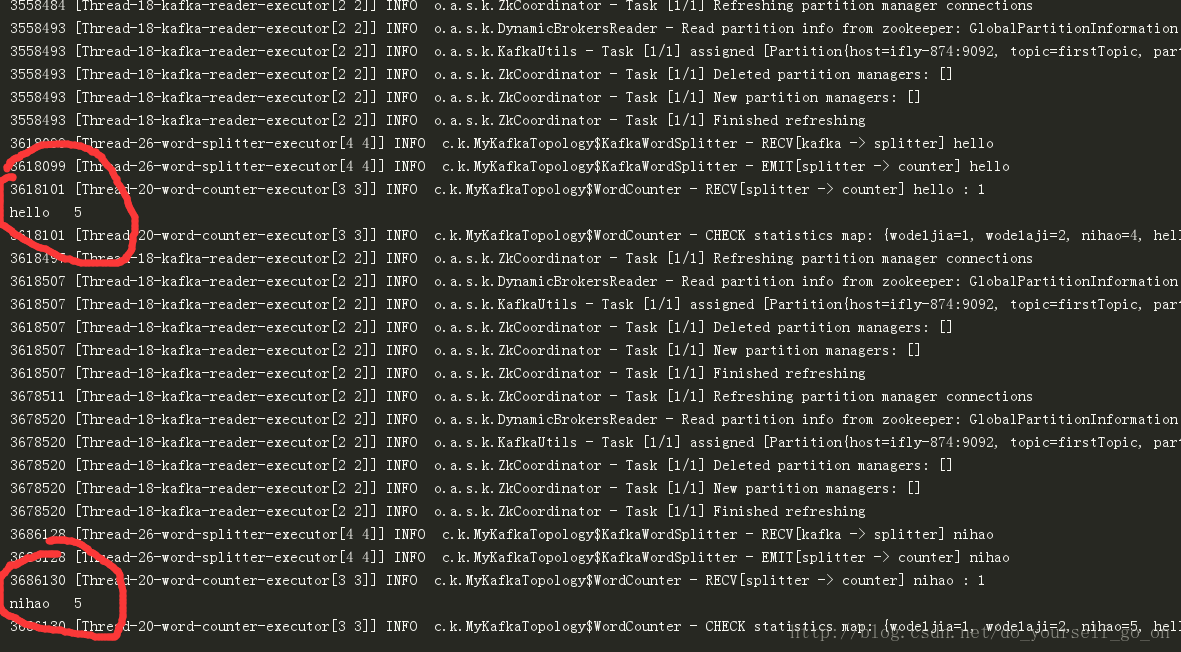
至此,测试环境搭建成功并通过测试。















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









