






设计并实现一个可靠传输协议并不容易,你得花大量精力应对链路上偶然发生的丢包,乱序的复杂性,因此你得设计复杂的丢包判定和重排序逻辑,也正因为这方面原因,大量协议照抄了 TCP 40 年。
设计一个多路径可靠传输协议更不容易,因为丢包判定和乱序重排逻辑更加复杂,这些新的复杂性进一步抵消了本不多得的带宽聚合的收益,这还没算上复杂的串行一对多数据包调度算法。当 MPTCP 出来时,人们认为有了一个现成的拿来就用的多路径传输协议。可 MPTCP 已经十年仍未流行,基本上也就宣判了。
这些复杂性其实都来自一种传统的串行流式传输协议的思维定势。这个思维定势天然阻碍着多路径传输。由于任何思维定势都源自历史的局限,当时代变幻,局限被扫除后,问题便迎刃而解。
就从流式传输相悖于多路径及其历史背景说起,提出我的传输与控制分离的想法(这想法源自早期优化数据中心协议的经验),并给出一个实例。
流式传输,报文只需要单路径串行各就位即可保序,设 RTT 为单位 1,n 个数据停等所需时间为 n,若多路径乱序传输,n 条路径传输时间为 1,每个报文都要经过一个 O ( n ) O(n) O(n) 时间插入,总共需要 n 2 n^2 n2 次操作,虽然一次插入操作在主机尺度的 ns 级时间,远小于传输的 us 级尺度,但相比流式传输的线性扩展,多路径传输的 O ( n 2 ) \text{O}(n^2) O(n2) 依旧是不可扩展的,特别是考虑到每次 O ( n ) O(n) O(n) 操作后如有 hole 都要涉及 HoL,就将时间尺度拉到了与传输等量级,结论是多路径传输有损性能。
但这只是早期单处理器,小内存时代的思维的产物,就像玩汉诺塔一样,你只有一个自由杆,且每次只能移动一个盘子,这种思维方式下的 TCP 影响了几乎所有后续传输协议的设计。
传统传输协议倾向于在接收端部署更大的 buffer 来对乱序进行容忍,这意味着对主机调度策略以及路由策略没有信心,流式串行思维引导下,如果调度策略总是正确的,报文到达序列就是顺序的,所以,调度策略要尽量斟酌正确,以确保数据的顺序到达,不管是 MPTCP 还是 ECMP。
依然是汉诺塔游戏,如果你有 n 个自由杆呢,你还会小心翼翼斟酌移动盘子的顺序吗?
举个例子,传统中我们认为大文件传输属于流传输,《TCP/IP 详解》就这么讲的,但如果用 n 杆汉诺塔游戏的思路重构文件传输,传文件应该用内存拷贝的方式,而不是流过程。内存拷贝并不约束时序,横着拷贝,竖着拷贝,斜着拷贝,大块拷贝,小块拷贝都非常随意,这就能有效利用好并行资源,比如多路径分别传输不同的文件块,每个文件块都映射到自己的地址,单独一个线程负责周期性查看 hole,随时 nack。
全局序列号的滑动窗口似乎只能串行处理,但将一个窗口看作一大片内存,将该片内存分为由于 base + len 构成的无 overlap 小块,小块间就解耦可并行处理了,而无关的内存块传输,多路径是天然的。子流间关联自动解除,直接索引地址空间,而不是基于全局序列号在滑动窗口中重排,
O
(
n
2
)
O(n^2)
O(n2) 降为
O
(
1
)
O(1)
O(1)。
不光如此,传输语义的强序性和可靠性也自然解耦。
在传输而非接口的视角,强序性可分为下面三种:
- 生成类严格保序。严格字节流,数据即时生成,如远程登录,ls 是列举文件,sl 是跑火车,乱序会带来歧义,不能容忍;
- 非生成类保序。最终保序,数据本来就存在,如文件传输,1GB 文件单路径传 1 小时,m 条路径 spray 传输能确保在 1/m + α 时间完成传输和重排,α 越小越好;
- 准序。大致保序,由于无法区别丢包和乱序,故由业务逻辑自行排序并判定是否需要重传,比如流媒体传输;
在内存观点下,内存只提供地址空间映射本身,其它控制逻辑均可从传输分离:
- 保序,可靠。线程扫描内存块并严格发送 ack,nack,大内存供大文件传输,小内存供流式传输;
- 保序,不可靠。线程不扫描内存块,不发送 ack,nack,接口只按照内存地址和配置时间间隔即时搜集数据;
- 单独索要(ack/nack)任意顺序的 base + len 序列即可实现任意顺序接收以及滑动窗口;
将控制从传输中分离极大减轻了传输协议的负担,传输过程仅仅完成多路径 spray 后其它控制逻辑不管,从而可以灵活应对从尽力而为网络到 IB 网络等所有网络传输。针对尽力而为网络,控制需要更大强度的工作保证保序和可靠性,形成类似 TCP/IP 协议族,对于 IB 网络,底层保证的逻辑就无需重复实现。
我本不想提 IB,我只是想说内存观点的 spary 传输可以轻松应对 UDP over TCP,TCP over TCP 等重复控制问题。且到此为止,我没提 RDMA,我说的也不是 RDMA,否则会面对一系列质疑性的限制:
- 内存碎片化:大规模并发传输时,连续内存分配困难,难以预先为所有可能的乱序包预留空间。
- 协议兼容性:RDMA 的内存注册机制要求提前声明内存区域大小,动态调整内存布局会增加复杂度。
- 硬件限制:网卡固件通常不具备动态内存管理能力,需依赖 CPU 干预,违背 RDMA “零拷贝” 初衷。
- 消息边界和部分写入:类似 TCP 的问题;
- …
包括 RDMA 在内,其实还是传统单处理,小内存的串行流式控制思维在作祟,处处小心着并发控制,内存管理问题。
时间空间本就一对矛盾,要实现 O ( 1 ) O(1) O(1) 的时间,必须以空间的一定浪费为代价,因为如果空间压缩紧凑了,必然有至少一个元素移动了位置,过程中时间发生了折叠,你得花时间移动这个位置并花时间将新位置找出来。
来看一个内存观点下的多路径传输的最简单实例。仍以大文件传输为例:
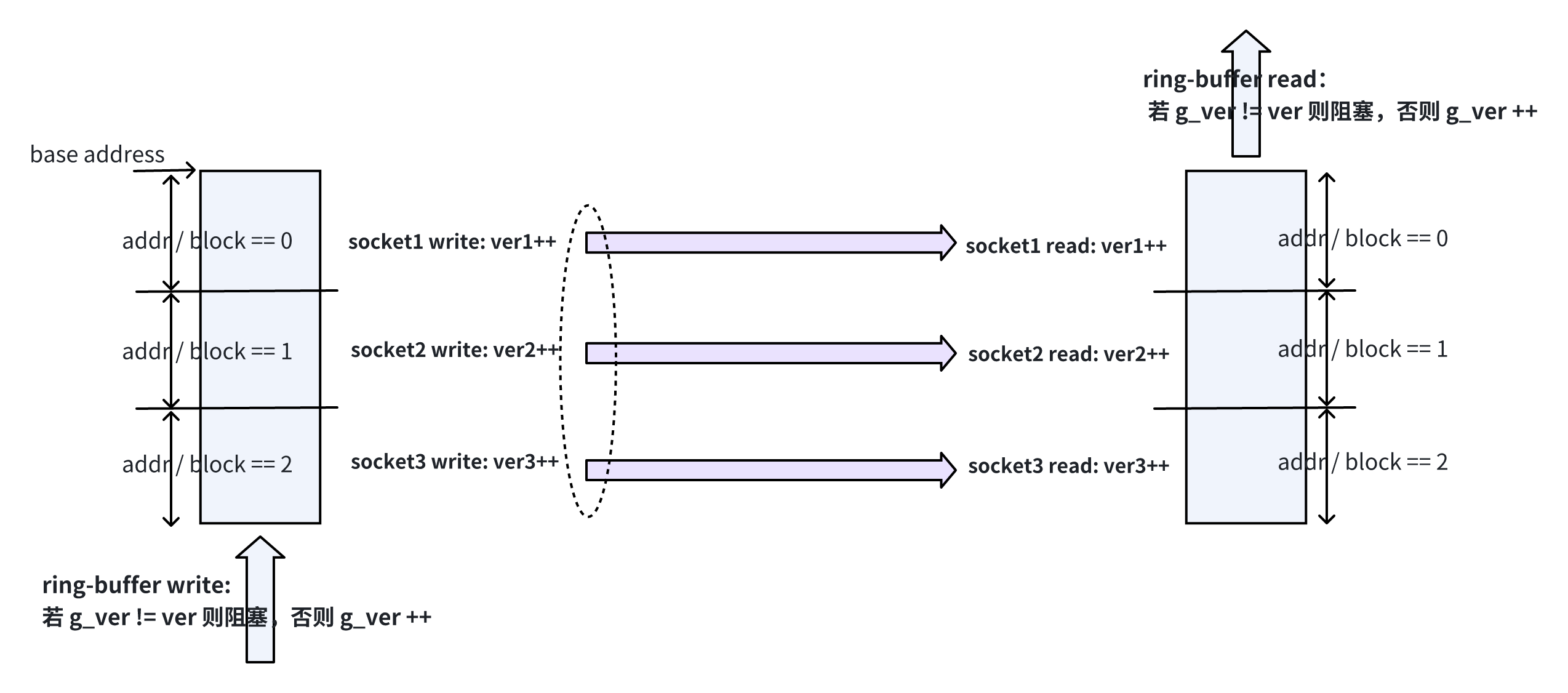
看起来没有任何不同,这就是一个多路径传输过程,但亮点在于,socket 如果是 TCP socket,额外什么都不需要做,如果 socket 是 UDP socket,内存观点让你实现可靠传输时不需要把太多精力花在乱序重组,传输和控制只认内存不认包,包是网络的事:
- 若内存块需要确认,receiver 确认就好了,协议格式自己定;
- 若迟迟没收到某个 hole,receiver 发 nack 好了,协议格式自己定;
- 若发送端需要重传某块内存,标记好 base + len,找个 socket 重传好了;
- 若只需要准序,receiver 直接将 hole 赋 padding 上送就好了;
- …
因此,你只需组织类似下面的数据结构:
struct multi_spray_header {
u8 my_id; // 本应对应的内存区块索引;
u8 curr_id; // 帮忙代劳的内存区块索引,比如嫌弃并帮其它 subflow 重新传输;
u32 offset; // 对应内存区块的偏移,直接放进去即可;
u32 len; //
u8 need_ack:1, // 是否需要应答,以便 sender 重传;
need_nack:1, // sender 是否请求 nack
ignore:1
unused:5;
u8 ignore_bits[MAP_SIZE]; // 可丢弃的 bitmap,receiver 可直接填 padding 通过,不再等待
...
};
对大文件传输,可以有效聚合所有路径的带宽,对低时延应用,很容易实现每条路径冗余发送,哪条最快到达用哪个,还可以灵活混合不同策略,实现流媒体的准序低延时传输,通过编码结合 FEC 优化传输控制逻辑,这些都是 MPTCP 不具备的能力。
传输和控制分离,传输只管 spray,而 spray 的额度和强度由内存如何分块决定,这就解决了路径异构问题。质量好的路径多发送,质量差的少发送,延时大的发后面的数据,延时小的发前面的数据,轻松实现笨鸟先飞。体现在上图上就是,我那 addr / block_size 只是最简单的 hash 分块例子。
就这个思想,它可以用来实现 TCP,也可以实现 RDMA,它可由硬件实现,也能用纯软件实现,它可能在小内存系统遭遇烦人的内存管理算法问题,也可以在大内存系统铺张浪费。
buffer 和时延的矛盾依旧在,但现在可以通过多路径缓和了,每多一条同构路径,就多一份减少时延的助力,若是异构路径,绝对 buffer 数量增加,对算法依赖也加强,这无法避免,因为异构时延与 buffer 等效,都是 BDP 的构成。
分离了传输和控制,这是一种真正的多路径传输协议。下面准备从内存操作向数据包操作回归。
不谈公平性,只说负载均衡,在多 queue 上调度保序包很难,因为包量 n 不可扩展,所以 O(1) PIFO 很昂贵,但在多路径上调度内存块就不难了,内存块保证包的相对顺序就够。
有了以上内存保证单流相对包序的理论,为了防止任意一条构成多路径的子流空闲(halt),为防止多路径操作任意一块内存(ring-buffer) HoL,大概就是 VOQ(这也是多亏了我早年高性能路由的经验) 的意思,多部署几个就是了:
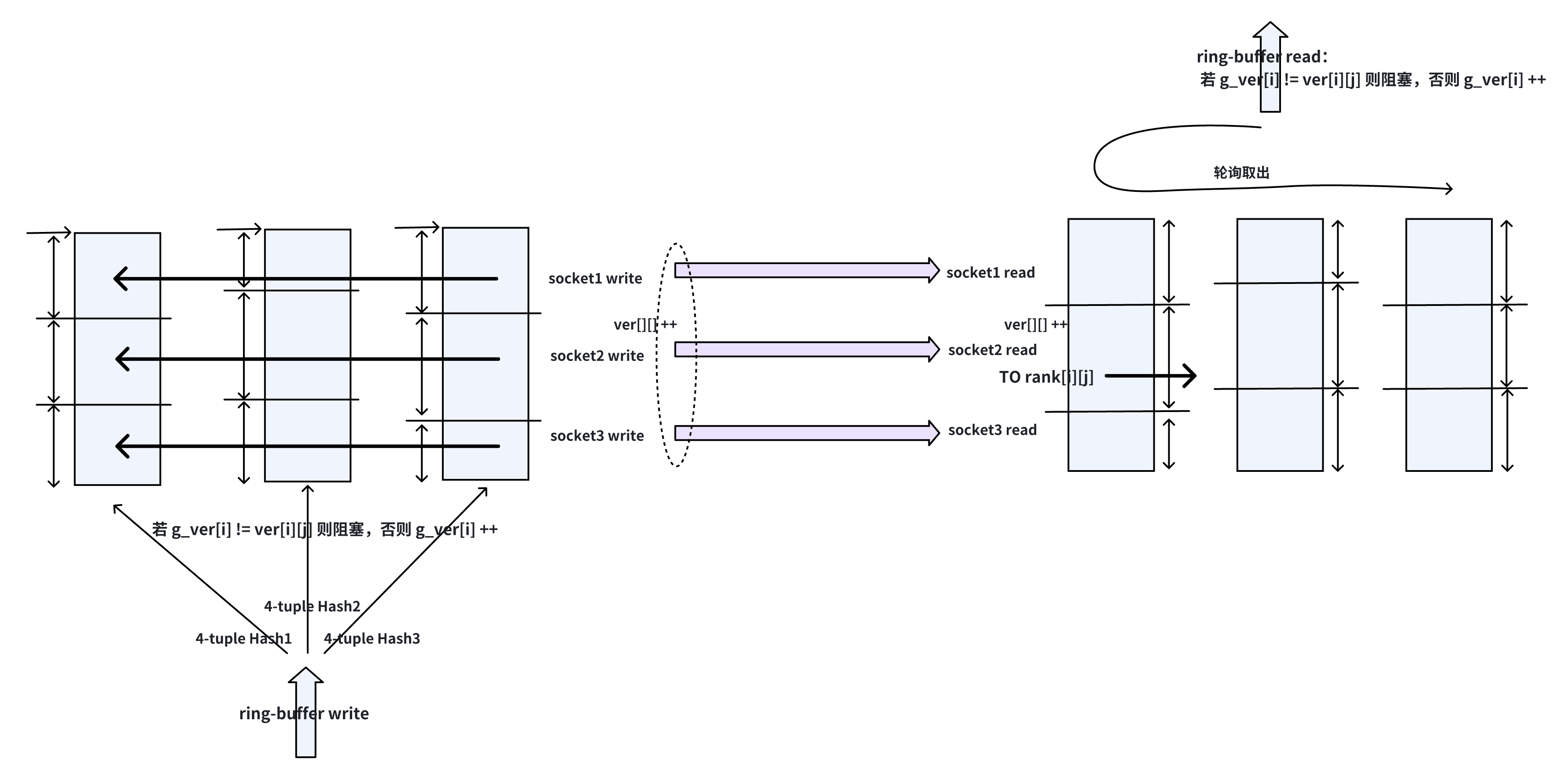
提到公平性,根源在源头准入机制,中间节点保证公平性要付出得不偿失的代价,已经不公平到达,偏要为历史买单,效率(或者说功耗)就一跳跳针对不公平的拨乱反正中消耗掉。
回到内存观点(而不是包的观点)下自然而然地多路径并行传输,总有人说内存拷贝太昂贵,若只为了为减轻乱序重排序 O ( n 2 ) O(n^2) O(n2),这其实是在问一个问题,“n 字节数据内存拷贝的开销和 n/1500 个节点以任意既定顺序串行插入排序的开销哪个更大” ,以标准 CPU 周期时间记一字节内存拷贝和一次指针操作简单计算,大致当 n > 20000 后,内存拷贝就显著优于乱序重组,这还没算上内存拷贝的各种优化以及节省掉的传输开销:
- 体系结构,硬件卸载相关的内存拷贝优化,映射,零拷贝;
- m 条路径并行节省的 ( n ⋅ W − n m ⋅ W + α ( jitter ) ) ⋅ RTT (n\cdot W-\dfrac{n}{m}\cdot W+\alpha(\text{jitter}))\cdot \text{RTT} (n⋅W−mn⋅W+α(jitter))⋅RTT 时间开销;
现在返璞归真,只保留内存的观点,回到传统的数据包处理,可构建下列多路径传输结构:
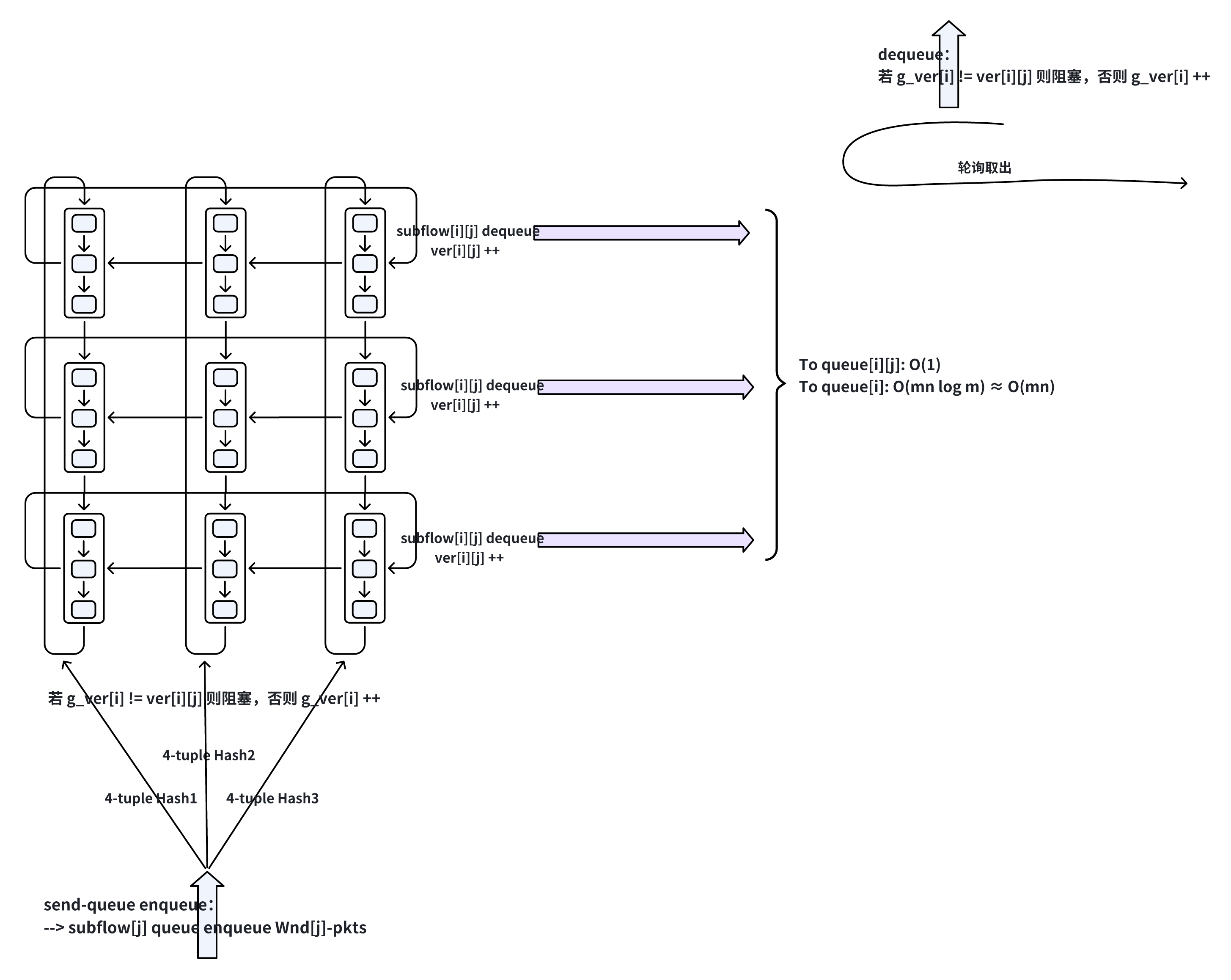
看起来只是绕了一大圈,和 MPTCP 相比,调度策略只是改成了 wnd-based,但事情没有那么简单。
第一眼看,根据式子,现在只要 RTT slowest ⋅ W slowest < RTT fastest ∑ i = 0 m W i \text{RTT}_{\text{slowest}}\cdot W_{\text{slowest}}<\text{RTT}_{\text{fastest}}\sum_{i=0}^m{W_i} RTTslowest⋅Wslowest<RTTfastest∑i=0mWi,似乎就能一定能保证聚合吞吐。但核心问题往往不太好一眼望见,不然早就有 wnd-based 调度策略了。
核心点在于,单条流很难在单位时间产生能聚合吞吐的数据量,这并不是带宽叠加那么简单,而还要考虑异构填充成本,特别在异构多路径场景下,很难满足,说白了,还是我前文强调的,数据量不足。可是假设用多路径搬运聚合流量,一旦数据量满足了聚合带宽的要求,wnd-based 调度策略的收益在乱序重组方面非常明显,receiver 只需要在子流接收 queue 内执行准序插入排序,子流接收 queue 之间执行归并排序即可,效率远小于 packet-based 调度策略的平方级插入排序: O ( m n ) < O ( n 2 m ) O(mn)<O(\dfrac{n^2}{m}) O(mn)<O(mn2)。
为了让本文形成一个闭环,来说说单流单位时间容量问题,为什么它那么低,低到大多数情况不足以满足聚合吞吐的下限。
以生成式保序流为例,单流容量低,其实还是历史原因,单处理器,小内存时代的产物:
- 程序在单个线程产生流的速度太慢;
- 即便产生很快也没足够 buffer 缓存;
- 远程登录,电子邮件受限于键盘输入;
- 文件很大,但不是生成式流,用流传文件是个错误;
这就决定了几乎所有串行流都是细水长流,而所谓大象流几乎都是本不该存在的文件流。所以我经常说,人们根本就不那么在乎单流最大吞吐,大部分人用不了那么大带宽,在很长一段时间,就算人们需要单流大吞吐,也用不起(在 2025 年,即便经理也不敢持续 500Mbps 跑流量),人们在乎的是很多流的总吞吐,这至少还涉及并发能力,可以几个用户,几条流一起跑。
这种状态一直持续到今天。所以直观点说,MPTCP 类似三辆卡车拉经理,比经理自己爬还费劲。将一个小串行流放入 MPTCP(或其它任何 MP-X) 在多路径上调度本身就是没事找事,只有聚合的多流数据用 MPTCP 搬运才有意义,这类多流单应用类型目前正越来越多。
随着多处理,大内存变得普遍,内存变得便宜,类似 FFmpeg + 线程池的多核视频编码,HDFS / 分布式存储,CUDA Streams 异步 AI 推理等现代(以区别 1970 年代的 TCP/IP 肇始)场景非常适应多路径并行处理。
传输与控制分离了,传输只做 spray,控制的焦点在更大的空间中从时间复杂度的斟酌中转移,还是汉诺塔那个游戏,空杆多了,每次就能移动多个盘子,玩法自然就不一样了。
浙江温州皮鞋湿,下雨进水不会胖。

















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









