






0.问题及描述
在测试产品的时候,莫名其妙发现了我们的主进程VPNd会出现以下的报错:2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
这种报错“但不经常,也不绝对”,上周末测试了两天,没有报错,可是周一就不行了,狂报错误!这种棘手的问题最可恶了。
我排查问题的时候,第一步绝对是google,如果没有结果再按照自己的风格深入进去,能多深入就多深入,一旦有了解决的办法,我会发表在我所有博客上,这样以后别人再google的时候就会多一个答案,互联网时代的知识其实就是如此方式积累的。
google了好久,没有什么创造性的结论,大量的关于这个错误的描述都是iptables DROP掉了数据包。其实我十分想找到一个和iptables无关的答案,直觉告诉我一旦找到了,错误原因基本就是那个(因为我的iptables规则根本就没有DROP掉任何东西),可是我没有找到!没法发,只能自己来了。惊魂72小时就这样开始了!三天内,我连续两天搞到深夜,白天也几乎不想搭理任何人,要不是因为昨晚喝酒后作业,估计要减少10小时吧,不管这么说,这72小时还是值得纪念的。
1.证明是别的原因而不是iptables
ftrace是一个好东西,这个我早就说过,它很简单,一般的发行版都支持,于是我做了下面的动作企图得到调试信息:mount -t debugfs debug /sys/kernel/debugecho skb:kfree_skb >/sys/kernel/debug/tracing/set_event<...>-14297 [002] 1286.492153: kfree_skb: skbaddr=ffff88007c1e0100 protocol=2048 location=$kfree_skb调用的地址
怎么办呢?由于无法tracestack,那就就只能将上述的“kfree_skb调用的地址”在/proc/kallsyms中找了,注意,/proc/kallsyms中不可能有哪个函数完全匹配上面“kfree_skb调用的地址”,因为kallsyms中是内核函数的地址,而kfree_skb仅仅是内核函数中的调用,因此需要在“kfree_skb调用的地址”下方找最接近的函数。
按照上面的过滤方式,一次次的发现正常的kfree_skb,然后将其echo到下面的文件中:
/sys/kernel/debug/tracing/event/skb/kfree_skb/filter
最终我得到了一个很长的过滤表达式:
echo "location!=0xffffffffa026d04a && location!=0xffffffffa026c82a &&location!=0xffffffff812d6a6f && location !=0xffffffff812a092c &&location!=0xffffffff812aa03e && location != 0xffffffff812f726f &&location!=0xffffffffa01ee3af &&location!=0xffffffff812aaf82 && location!=0xffffffff812965a3 &&location != 0xffffffff812f622c &&location!=0xffffffff812c8324 && location!=0xffffffff812aace1 && location!=0xffffffff81294ef7 && location!=0xffffffff812a12b8 &&location!=0xffffffffa026d04a" >/sys/kernel/debug/tracing/event/skb/kfree_skb/filter echo 1 >/sys/kernel/debug/tracing/event/skb/kfree_skb/enablewhile true; do echo $(date); cat trace|grep -v FUNCTION|grep -v "tracer: nop"|grep -v "# | | |"|grep -v "#";>trace;sleep 4;done然后就是漫长的等待,等待问题的重现。成小时成小时的等待...终于重现了,结果就是大量的:
<VPNd>-xx [002] 2876.582821: kfree_skb: skbaddr=ffff88007c1e0100 protocol=2048 location=ffffffff812b2887
查询kallsyms,发现它真的就是nf_hook_slow,而这个函数正是Netfilter的核心函数,难道真的是iptables导致的?我还是不相信!但是不能有更详细的信息了,要是能把stack打出来该多好啊!!
2.需要更加详细的信息
很显然,没有function trace支持的内核无法通过ftrace得到更加详细的信息了,其实我现在就是想得到问题重现时调用nf_hook_slow时的堆栈。重新编译内核肯定能解决,但是场面过于宏大,于是想办法自己hack一个,于是编写了下面的模块:#include <linux/types.h>
#include <linux/module.h>
#include <linux/smp_lock.h>
//#include <linux/netfilter.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("ZhaoYa <marywangran@126.com>");
MODULE_DESCRIPTION("Xtables: DNAT from ip-pool");
//准备替换掉nf_hook_slow
int (*orig_nf_hook_slow) (u_int8_t, unsigned int, struct sk_buff*, struct net_device*, struct net_device*, int (*okfn)
(struct sk_buff *), int) = 0xffffffff8126a910;
char code[200] = {0};
int (*_nf_hook_slow) (u_int8_t, unsigned int, struct sk_buff*, struct net_device*, struct net_device*, int (*okfn)(struct
sk_buff *), int);
int new_nf_hook_slow(u_int8_t pf, unsigned int hook, struct sk_buff *skb,
struct net_device *indev,
struct net_device *outdev,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
//先调用原来的nf_hook_slow
int ret = _nf_hook_slow(pf, hook, skb, indev, outdev, okfn, hook_thresh);
//如果被DROP了就打印堆栈
if (ret = 1) {
dump_stack();
}
return ret;
}
static int __init pool_target_init(void)
{
//0xffffffff8126a910是原始nf_hook_slow的地址,
//由于还要使用该处的代码,覆盖前先保存在别处
char *addr = 0xffffffff8126a910;
//由于需要重写0xffffffff8126a910,防止内核设置了只读,
//故需要修改PTE页表项
char *pte = 0xfffffffff126a161;
lock_kernel();
unsigned long value =*pte;
value = value|0x02;
*pte = value;
//先将原始函数保存在code里面,200这个长度是原始nf_hook_slow的地址
//和它下面一个函数地址的差值多一点,由于代码中肯定有return,因此多
//复制一些没关系,少了就不行。
memcpy(code, orig_nf_hook_slow, sizeof(code));
//用新的nf_hook_slow覆盖原来函数的地址
memcpy(addr, new_nf_hook_slow, 40);
//保存原始函数的新地址
_nf_hook_slow = code;
unlock_kernel();
return 0;
}
static void __exit pool_target_exit(void)
{
char *addr = 0xffffffff8126a910;
lock_kernel();
memcpy(addr, code, sizeof(code));
unlock_kernel();
}
module_init(pool_target_init);
module_exit(pool_target_exit);代码乱七八糟的,由于在原有的一个nat模块上更改(便于使用它的Makefile),因此命名也不合常理。加载之,报错,panic!!
...
直到现在仍然没有编译新内核的勇气
...
心中的气愤达到了要崩溃的地步,终于决定重新编译内核了!
3.重新配置并编译内核以及所有模块
下午2点开始,重新配置内核,新增的配置如下:< CONFIG_FRAME_POINTER=y
< CONFIG_HAVE_FTRACE_NMI_ENTER=y
< CONFIG_FTRACE_NMI_ENTER=y
< CONFIG_FUNCTION_TRACER=y
< CONFIG_FUNCTION_GRAPH_TRACER=y
< CONFIG_FTRACE_SYSCALLS=y
< CONFIG_STACK_TRACER=y
< CONFIG_WORKQUEUE_TRACER=y
< CONFIG_DYNAMIC_FTRACE=y
< CONFIG_FUNCTION_PROFILER=y
< CONFIG_FTRACE_MCOUNT_RECORD=y
这样就可以支持function trace了!然后make-kpkg编译之。漫长3小时后,还没有编译完,我的虚拟机真的不行了。要下班了,匆匆回家,以前从来没有这么早过,在路上可以换换心情。发现我的心理素质还不错,路上结掉了《罗马人的故事:最后一搏》,超级崇拜君士坦丁!
回家吃完晚饭,又开始了惊魂之旅,通过VPN接入公司的机器,发现终于编译完成,于是赶紧先提交到SVN上,大概九点多,准备用新内核调试,由于兴奋喝了半瓶酒,酒后作业不管干什么都很危险,不仅仅是开车。在升级内核时,一下子把grub也给换掉了,reboot没有成功,公司机器又不支持IPMI远程开机,这下悲催了...只能早早睡了!
4.新的ftrace以及stack trace
今天早上赶紧到公司,配置好了新的环境,升级了新的内核,终于可以一窥究竟了,等待问题重现后,打印了以下信息:<...>-27369 [002] 2876.582821: kfree_skb: skbaddr=ffff88007c1e0100 protocol=2048 location=ffffffff812ad914
<...>-27369 [002] 2876.582825: <stack trace>
=> kfree_skb
=> nf_hook_slow
=> T.889
=> ip_output
=> ip_local_out
=> ip_push_pending_frames
=> udp_push_pending_frames
=> udp_sendmsg
<...>-27369 [002] 2876.583069: kfree_skb: skbaddr=ffff88007c1e0c00 protocol=2048 location=ffffffff812ad914
<...>-27369 [002] 2876.583074: <stack trace>
=> kfree_skb
=> nf_hook_slow
=> T.889
=> ip_output
=> ip_local_out
=> ip_push_pending_frames
=> udp_push_pending_frames
=> udp_sendmsg
<idle>-0 [002] 11979.770335: kfree_skb: skbaddr=ffff88002f3f5200 protocol=2048 location=ffffffff812ad914
<idle>-0 [002] 11979.770338: <stack trace>
=> kfree_skb
=> nf_hook_slow
=> ip_local_deliver
=> ip_rcv_finish
=> ip_rcv
=> netif_receive_skb
=> br_handle_frame_finish
=> br_nf_pre_routing_finish
.....大量的br_nf_pre_routing_finish起始的stack到达ip_local_deliver后被Netfilter丢弃
起初,我以为都是VPNd发出的数据包被DROP,现在看来bridge接收的数据包也会被DROP(此时的进程是内核本身即0号idle进程,其实它并不idle,新内核的所有内核线程都在idle的工作队列里),从以上堆栈看,ip_local_deliver以及ip_output对应的HOOK点分别应该是INPUT以及POSTROUGING,由于我并没有在这两个Chain上添加任何iptables的DROP策略,鉴于对Netfilter的理解比较深入,因此我觉得是内核本身隐含的一些HOOK函数导致的,为了找到是哪个隐含的HOOK函数,就有必要跟一下代码,由于使用ftrace输出大量的信息会遇到薛定谔猫的问题,因此决定静态浏览代码。
这里有一个疑点,那就是起初我以为丢包都是VPNd进程造成的,可是从ftrace的结果看来,大量的丢包是ilde进程的softirq中造成的,很明显是数据包的接收进程造成了丢包;还有一个疑点,那就是通过查看/proc/net/snmp文件,发现其OutDiscards字段在问题重现即Operation not permitted的时候有所增加,而OutDiscards的增加仅仅在确定的地方被调用。在没有全面分析问题之前,这两个疑点说明了两个问题,一是ip_local_out函数确实有丢包,二是可能是一个全局问题导致了这个丢包,因为并不是仅仅在发送数据的时候丢包。
注解:如果看上述堆栈,会发现br_nf_pre_routing_finish-br_handle_frame_finish-netif_receive_skb跟实际不一样,这是因为我修改了nf_bridge的缘故,我的目标是先让bridge去call iptables的PREROUTING,然后再基于mark绝对是否进行bridge的redirect。
5.遍历Netfilter的OUTPUT以及POSTROUTING
遍历代码的过程是痛苦的,无非就是找到内核隐含的HOOK函数中,在什么情况下会DROP掉数据包,并且还要在INPUT以及POSTROUTING这两个点上。最后__nf_conntrack_confirm引起了我的注意,因为数据包在离开协议栈的时候,会调用confirm,这个是为了将NEW状态的conntrack添加到conntrack哈希中,恰恰这个confirm也正是在INPUT以及POSTROUTING这两个点上,这两个点正是数据包离开协议栈的点!更加幸运的是,竟然在该函数中找到了DROP:int
__nf_conntrack_confirm(struct sk_buff *skb)
{
...
//如果标示为NEW的conn在双向的哈希表中找到了相同的,则DROP
hlist_nulls_for_each_entry(h, n, &net->ct.hash[hash], hnnode)
if (nf_ct_tuple_equal(&ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple,
&h->tuple))
goto out;
hlist_nulls_for_each_entry(h, n, &net->ct.hash[repl_hash], hnnode)
if (nf_ct_tuple_equal(&ct->tuplehash[IP_CT_DIR_REPLY].tuple,
&h->tuple))
goto out;
...
out:
NF_CT_STAT_INC(net, insert_failed);
spin_unlock_bh(&nf_conntrack_lock);
return NF_DROP;
}NF_CT_STAT_INC(net, insert_failed);
这是一个内核计数器,名称是insert_failed,于是借助于procfs的net/stat目录观测。
6.定位到insert_failed计数器
通过查看/proc/net/stat/nf_conntrack,发现了下面的事实:XXXX-SSL-GATEWAY:/proc/net# cat stat/nf_conntrack
entries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete
00002236 00692e45 024a9466 001e1713 00008ab5 00008007 001cad74 001c9b8d 001e087b 00000e7f 00000000 00000000 000004a1 00000000 00000000 00000000
00002236 0067bfee 0241465c 001db7e0 00008853 00007756 001f1fe9 001f1265 001daab2 00000d19 00000000 00000000 0000049b 00000000 00000000 00000000
00002236 00656b68 02332e99 001d3312 00008026 00007795 001d9498 001d8a18 001d2575 00000d8f 00000000 00000000 00000482 00000000 00000000 00000000
00002236 0062d343 02261842 001cccef 00007ca2 0000792a 001c4ac9 001c3e58 001cbff6 00000ceb 00000000 00000000 000004a5 00000000 00000000 00000000
# 此处的时间内,问题重现了
XXXX-SSL-GATEWAY:/proc/net# cat stat/nf_conntrack
entries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete
000021c9 006b559d 0259312e 001ecf50 00008e14 00008023 001d83fa 001d7298 001ec0b8 00000e7f 00000000 00000000 000004a3 00000000 00000000 00000000
000021c9 0069b52e 024fdc33 001e6eb1 00008be5 00007760 001fb89d 001faa7c 001e6181 00000dab 00000000 00000000 000004a1 00000000 00000000 00000000
000021c9 006765ca 02416a16 001de7ab 0000835f 000077a8 001e49e8 001e3f81 001dda05 00000d98 00000000 00000000 00000485 00000000 00000000 00000000
000021c9 0064d066 0233c2d7 001d7e55 00007f83 0000792c 001cfbb9 001cef3c 001d715c 00000ceb 00000000 00000000 000004a5 00000000 00000000 00000000
注意上面的insert_failed计数器的递增,说明什么?说明正是那个__nf_conntrack_confirm函数将数据包DROP了。
问题定位了,下面就是解决它了!出去抽根烟,理一下思路。
7.丢弃ftrace,开始用conntrack工具
至此,不再需要ftrace了,暂时不需要了,因为下面的工作我很自信,也会用比较YD的方式去解决,关掉ftrace以防薛定谔猫的惊现!echo 0 >/sys/kernel/debug/tracing/event/skb/kfree_skb/enable
umount /sys/kernel/debugconntrack -E -e DESTROYWARNING: We have hit ENOBUFS! We are losing events.
This message means that the current netlink socket buffer size is too small.
Please, check --buffer-size in conntrack(8) manpage.
conntrack v1.0.0 (conntrack-tools): Operation failed: No buffer space available
这下没辙了,于是又写了一个命令:
while true;do echo $(date);cat ip_conntrack|grep 192.168.200.220|grep udp;echo ;echo;sleep 2;done2013年 07月 18日 星期四 13:02:15 CST
udp 17 179 src=192.168.200.220 dst=192.168.101.242 sport=16796 dport=61194 packets=161510 bytes=27474312 src=192.168.101.242 dst=192.168.200.220 sport=61194 dport=16796 packets=140004 bytes=36911621 [ASSURED] mark=100 secmark=0 use=2
2013年 07月 18日 星期四 13:02:18 CST
2013年 07月 18日 星期四 13:02:22 CST
conntrack突然消失了,这就不对了,还剩下179秒才到期,怎么会被删除呢?下一步其实又要看代码了,看一下都在哪里调用删除conntrack的动作,但是我觉得已经没有必要了,因为我已经知道了答案,在我们的产品中,前期为了解决一个问题,调用了conntrack -F命令...
实际上,即使我不知道调用conntrack -F,也还是能定位了确实有人调用了conntrack -F的。通过观察上面的ftrace输出就会发现,每次只要udp_sendmsg造成的DROP的同时,都会有大量的br_nf_pre_routing_finish造成的DROP,反过来也一样,导致我曾经想过二者是不是一方的发生导致了另一方的发生,后来我发现它们没有什么关系,那么这能证明什么呢?--------------- 证明一定有大量的conntrack同时被删除的情况------------ 如果内核中有自动的大量信息被同时删除,那一定是缺陷,设计者不会做如此不平滑的事情的。一般而言都是丢弃当前的。这就说明一定是用户态有人通过系统提供的接口手工调用了删除操作,罪魁祸首,当然是conntrack -F了!
8.没办法了,只靠想了
现在问题还没有解决,需要想一下就是conntrack被删除,如何能导致数据包在__nf_conntrack_confirm被DROP呢?这样反过来确认一下,可以尽可能排除其它的因素。这个也没办法再调试了,只能靠想了,但是前提是你需要对Netfilter对conntrack的处理极其精通,我给出一张时序图来说明问题吧:注意__nf_conntrack_confirm的注释“如果标示为NEW的conn在双向的哈希表中找到了相同的,则DROP”
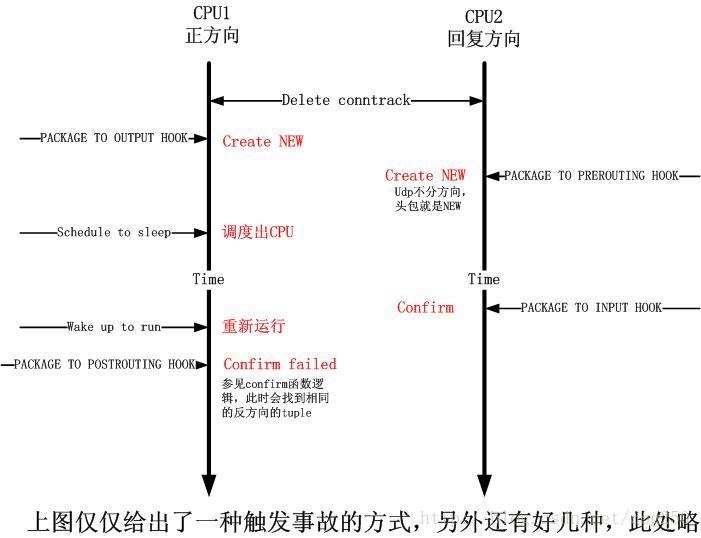
连接是双向的,而conntrack却只有一个是问题的关键,由此看来,还是TCP的有状态conntrack比较完美。
这个问题真的很不好重现,我试着手工调用了几次conntrack -F,并不是每次都能重现,甚至连续好几次执行才能重现。必须卡在上图的那些时间点,问题才能重现,因此这是个“但不经常,也不绝对”的问题!!
通过上图,我们可以发现,在多处理器环境下更容易发生这个问题,因为在多处理器情况下,问题的重现不仅仅取决于udp发送进程的
schedule,还取决于其它处理器上网络数据包接收进程的执行。
9.尴尬的解决方式
为何尴尬?问题不是解决了吗?是的,问题解决了,但是解决方式确实很尴尬,就是去掉了conntrack -F而已,太TMD没有技术含量了。然而对于技术痴迷者而言,这惊魂72小时确实让我学到了很多东西,也让我明白以后应该试着不把简单问题复杂化,到底哪里出了问题的另一个问法其实就是“我到底添加了哪些功能”,在没有问题发生到有问题出现的时间段内的任何更改都可能导致各种奇异的问题。作为一个bug的定位和解决,确实很尴尬,但是对于一个技术痴迷者而言,重要的是知其所以然,是为所以然。
10.经验
没有什么经验,唯一的经验就是在加入一个功能的时候,一定要彻底了解该功能所用到的所有的技术细节,否则就很有可能引入新的问题!对待技术问题决不能模棱两可,要么不用,要用就要彻底摸清!11.关于标题
本文之所以取这么一个名字,是因为希望别人比较容易搜到这篇文章,因为我在起初解决问题google的时候,花了大量的时间没有结果,不管国内国外的高手,都没有切入重点。因此我希望我这篇惊魂72小时可以对大家有所帮助,毕竟我起初也是希望能直接在网上找到答案,怀着这么一种侥幸心理,不想自己努力,只是没有找到结果以后,不得已才自己摸索的。这样的人我相信是大多数,因此我希望大家都能继续尝试这种方式,毕竟是懒人创造了世界,懒人并不懒惰,懒人不重新造轮子,但是在迫不得已不得不重新造轮子的时候,他的目的是不希望别人-别的懒人重新造轮子!12.72小时内的生活
我感觉自己就是双核,我可以在72小时内保持紧张去排查这个问题,然而另一方面,我又有自己其它方面的收获:1.结掉了第9本《罗马人的故事》,是为最后的一搏,为戴克里先感到悲哀。
2.查阅了君士坦丁的相关资料,理解了他为何结束了罗马帝国,创建了中世纪。
3.靠地利优势可以胜过天时和人和。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









