










1. 在centos7先安装好python第三方包Numpy,Pandas,Scipy,StatsModels,Scikit-learn,matplotlib,TensorFlow;
2. 编写python文件test.py,代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# -*- author: dongguangming -*-
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
# #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# #############################################################################
# Compute DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print('Estimated number of clusters: %d' % n_clusters_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.savefig('test.png')
3. 执行python test.py 报错图
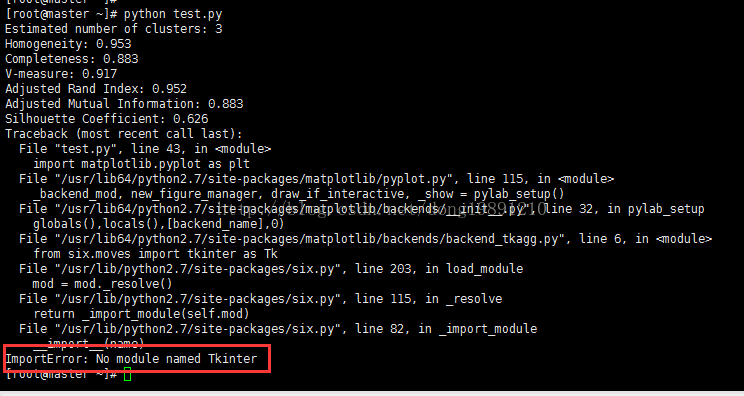
4. 解决方式: yum install -y tkinter
5. 再次执行python test.py 报错图
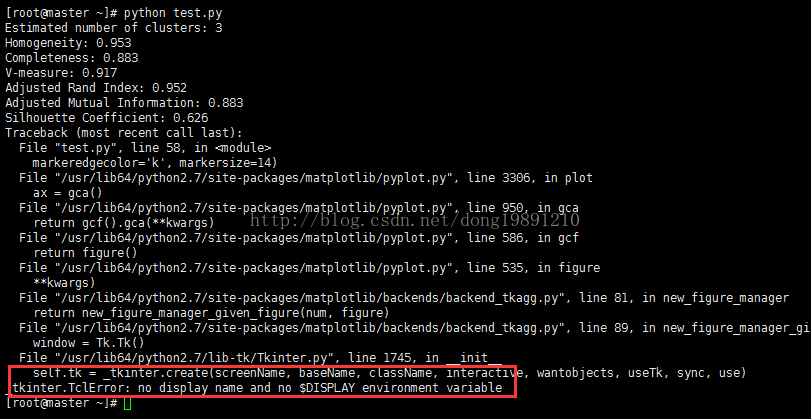
6. 修改python文件test.py,代码如下:
#!/usr/bin/env python # -*- coding: utf-8 -*- # -*- author: dongguangming -*- import numpy as np from sklearn.cluster import DBSCAN from sklearn import metrics from sklearn.datasets.samples_generator import make_blobs from sklearn.preprocessing import StandardScaler # ############################################################################# # Generate sample data centers = [[1, 1], [-1, -1], [1, -1]] X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4, random_state=0) X = StandardScaler().fit_transform(X) # ############################################################################# # Compute DBSCAN db = DBSCAN(eps=0.3, min_samples=10).fit(X) core_samples_mask = np.zeros_like(db.labels_, dtype=bool) core_samples_mask[db.core_sample_indices_] = True labels = db.labels_ # Number of clusters in labels, ignoring noise if present. n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) print('Estimated number of clusters: %d' % n_clusters_) print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels)) print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels)) print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels)) print("Adjusted Rand Index: %0.3f" % metrics.adjusted_rand_score(labels_true, labels)) print("Adjusted Mutual Information: %0.3f" % metrics.adjusted_mutual_info_score(labels_true, labels)) print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels)) # ############################################################################# # Plot resultimport matplotlib.pyplot as plt# Black removed and is used for noise instead.unique_labels = set(labels)colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]for k, col in zip(unique_labels, colors): if k == -1: # Black used for noise. col = [0, 0, 0, 1] class_member_mask = (labels == k) xy = X[class_member_mask & core_samples_mask] plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col), markeredgecolor='k', markersize=14) xy = X[class_member_mask & ~core_samples_mask] plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col), markeredgecolor='k', markersize=6)plt.title('Estimated number of clusters: %d' % n_clusters_)plt.savefig('test.png') 7. 再再次执行python test.py,结果如图:import matplotlib # Force matplotlib to not use any Xwindows backend. matplotlib.use('Agg')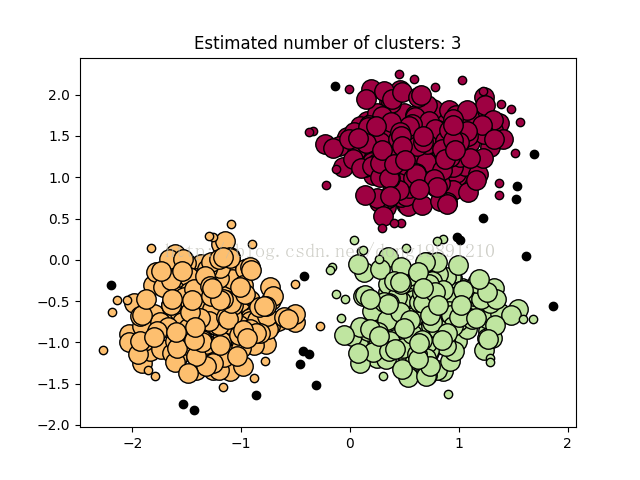
![]()
![]()














 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









