









Kafka服务端设计介绍
协议设计
Kafka自定义了一组基于TCP的二进制协议,只要遵守这组协议的格式,就可以向Kafka发送消息,也可以从Kafka中拉取消息,或者做一些其他的事情,比如提交消费位移等。
协议格式设计:
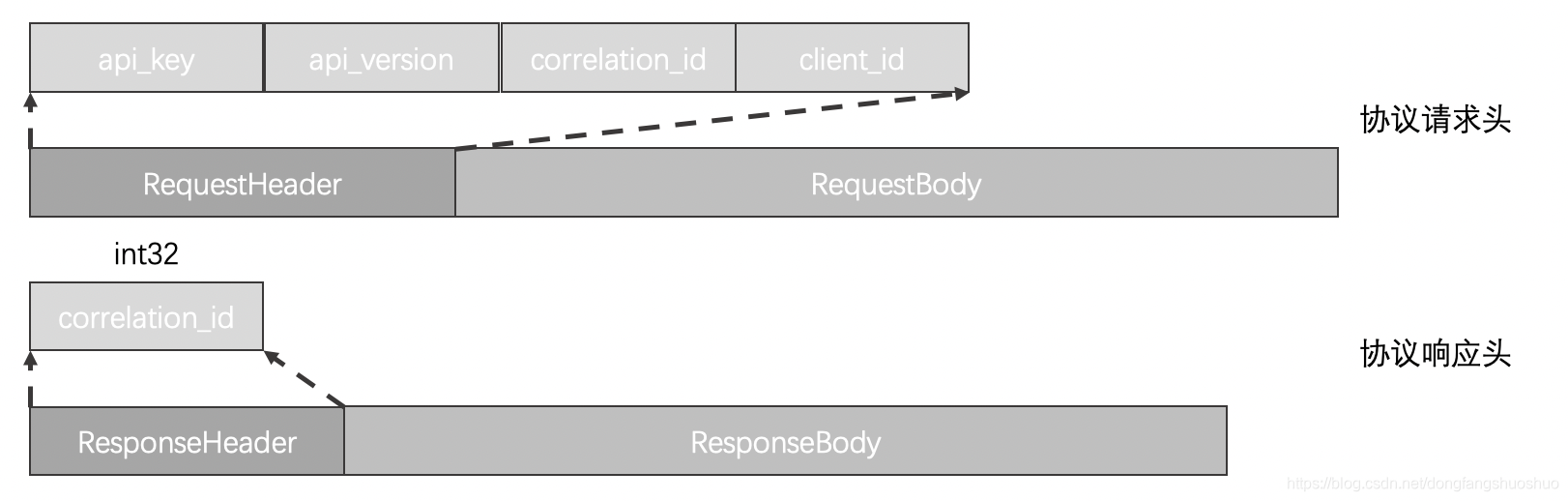
协议请求头格式如下图所示:

- api_key: API标识,比如PRODUCE、FETCH等分别表示发送消息和拉取消息的请求;
- api_version: API版本号码;
- correlation_id: 由客户端指定的一个数字来唯一地标识这次请求的id,服务端在处理完请求后也会把同样的corelation_id写到Response中,这样客户端就能把某个请求和响应对应起来了;
- client_id: 客户端id
两种请求协议格式设计:
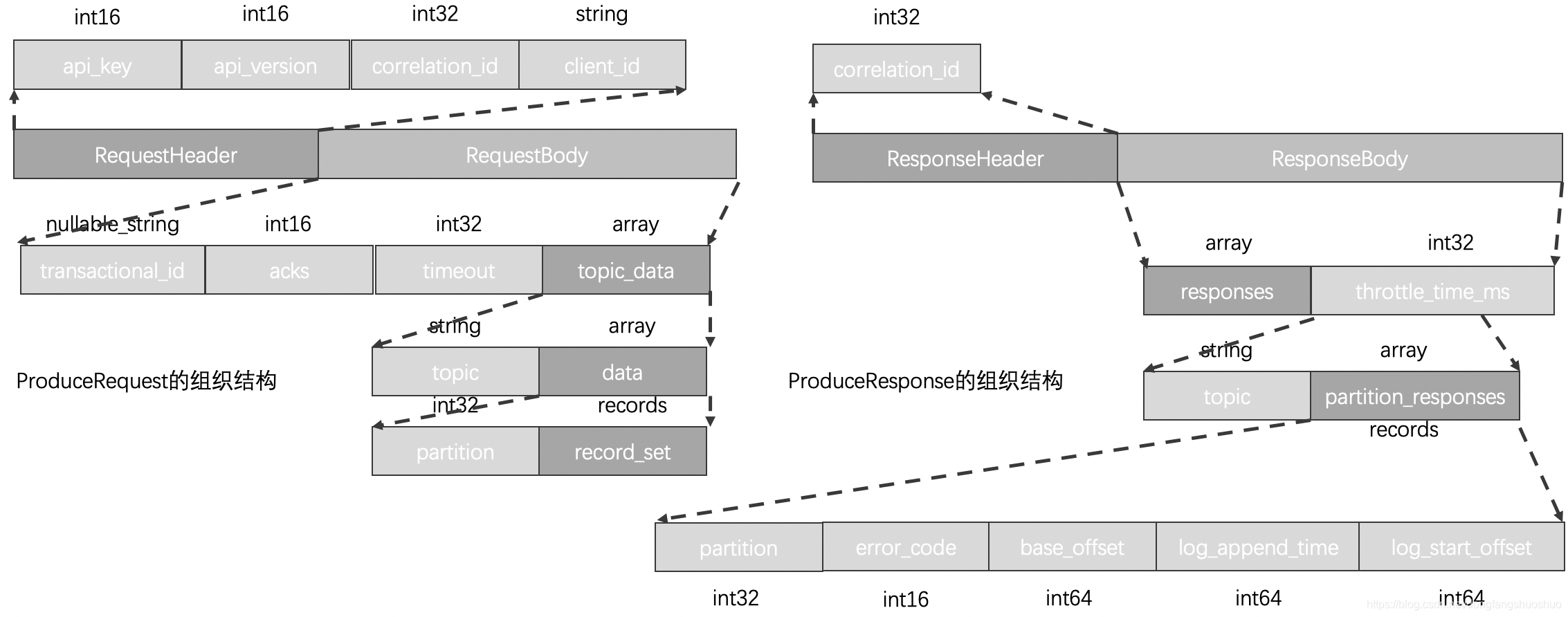
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pwqWsh66-1615297820147)(quiver-image-url/998D565FECB8A486F5E16933915AE505.jpg =861x432)]](https://i-blog.csdnimg.cn/blog_migrate/a2b845a31e6939b85598c362f55ce90c.png)
时间轮
Kafka中存在大量的延时操作,比如延时生产、延时拉取和延时删除等。Kafka并没有使用JDK自带的Timer或DelayQueue来实现延时的功能,而是基于时间轮的概念自定义实现了一个用于延时功能的定时器(SystemTimer)。JDK中Timer和DelayQueue的插入和删除操作的平均时间复杂度为(nlogn)并不能满足Kafka的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度都降为O(1)。时间轮的应用并非Kafka独有,其应用场景还有很多,例如:Netty、Akka、Quartz、ZooKeeper等组件
Kafka时间轮中的两个重要元素
-
TimingWheel
TimingWheel专门用来执行插入和删除TimerTaskEntry的操作
TimingWheel每个tickMs维护一个TimerTaskList,负责插入和删除TimerTaskEntry -
DelayQueue
DelayQueue专门用来负责时间推进
DelayQueue中保存待处理的TimerTaskList,每次取出DelayQueue非哨兵的头节点就是将要过期的待处理TimerTaskList,针对取出的TimerTaskList代表的时间点,对TimingWheel做精准推进,而不用一个一个tickMs的推进。
针对上面两个元素的叙述示例:
DelayQueue中第一个超时任务列表的expiration为200ms,第二个超时任务为840ms,此处获取DelayQueue的队头只需要O(1)的时间复杂度(获取之后DelayQueue内部才会再次切换出新的队头)。若采用每秒定时推进,则获取第一个超时任务列表时执行的200次推进中有199次属于"空推进",而获取第二个超时任务时又需要执行639次"空推进",这样会无故空耗机器的性能资源,这里采用DelayQueue来辅助以少量空间换时间,从而做到了"精准推进"。
延时操作
控制器
controller负责管理整个集群中所有分区和副本的状态。当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。当使用kafka-topics.sh脚本为某个topic增加分区数量,同样还是由控制器负责分区的重新分配
控制器的选举及异常恢复
任意时刻,集群中有且仅有一个控制器。每个broker启动时回去尝试读取/controller节点的brokerid的值,若读取到brokerid值不为-1,则表示已经有其他broker节点成功竞选为控制器,所以当前broker就会放弃竞选;若zk中不存在/controller节点,或节点数据异常,则会尝试去创建/controller节点,只有创建成功的broker才会成为控制器,每个broker都会在内存中保存当前控制器的brokerid值,此值可以标识/activeControllerId。
ZooKeeper中的/controller_epoch节点,该节点是持久(PERSISTENT)节点,节点中存放的是一个整型的controller_epoch值。用于记录控制器发生变更的次数。
具备控制器身份的broker需要比其他普通broker多一份职责,具体细节如下:
- 监听分区相关的变化。为ZooKeeper中的/admin/reassign_partition节点注册PartitionReassignmentHandler,用来处理分区重分配的动作;为ZooKeeper中的/isr_change_notification节点注册IsrChangeNotificationHandler,用来处理ISR集合变更的动作;为ZooKeeper中的/admin/preferred-replica-election节点添加PreferredReplicaElectionHandler,用来处理优先副本的选举动作。
- 监听主题相关的变化。为ZooKeeper中的/broker/topics节点添加TopicChangeHandler,用来处理主题增减的变化;为ZooKeeper中的/admin/delete_topics节点添加TopicDeletionHandler,用来处理删除主题的动作。
- 监听broker相关的变化。为ZooKeeper中的/brokers/ids节点添加BrokerChangeHandler,用来处理broker增减的变化。
- 从ZooKeeper中读取获取当前所有与主题、分区及broker相关的信息并进行相应的管理。对所有主题对应的ZooKeeper中的/brokers/topics/节点添加PartitionModificationsHandler,用来监听主题中的分区分配变化。
- 启动并管理分区状态机和副本状态机;
- 更新集群的元数据信息;
- 若参数auto.leader.rebalance.enable设置为true,则还会开启一个名为"auto-leader-rebalance-task"的定时任务来负责维护分区的优先副本的均衡。
附录
- 参考文章
- 《深入理解Kafka核心设计与实践原理》

















 1898
1898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









