







java对象的比较
等号(==):
对比对象实例的内存地址(也即对象实例的ID),来判断是否是同一对象实例;又可以说是判断对象实例是否物理相等;
equals():
对比两个对象实例是否相等。
当对象所属的类没有重写根类Object的equals()方法时,equals()判断的是对象实例的ID(内存地址),是否是同一对象实例;该方法就是使用的等号(==)的判断结果,如Object类的源代码所示:
public boolean equals(Object obj) {
return (this == obj);
} 当对象所属的类重写equals()方法(可能因为需要自己特有的“逻辑相等”概念)时,equals()判断的根据就因具体实现而异,有些类是需要比较对象的某些值或内容,如String类重写equals()来判断字符串的值是否相等。判断逻辑相等。
hashCode():
计算出对象实例的哈希码,并返回哈希码,又称为散列函数。根类Object的hashCode()方法的计算依赖于对象实例的ID(内存地址),故每个Object对象的hashCode都是唯一的;当然,当对象所对应的类重写了hashCode()方法时,结果就截然不同了。
二、Java的类为什么需要hashCode?---hashCode的作用,从Java中的集合的角度看。
总的来说,Java中的集合(Collection)有两类,一类是List,再有一类是Set。你知道它们的区别吗?前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。那么这里就有一个比较严重的问题了:要想保证元素不重复,可两个元素是否重复应该依据什么来判断呢?这就是 Object.equals方法了。但是,如果每增加一个元素就检查一次,那么当元素很多时,后添加到集合中的元素比较的次数就非常多了。也就是说,如果集合中现在已经有1000个元素,那么第1001个元素加入集合时,它就要调用1000次equals方法。这显然会大大降低效率。
于是,Java采用了哈希表的原理。哈希算法也称为散列算法,当集合要添加新的元素时,将对象通过哈希算法计算得到哈希值(正整数),然后将哈希值和集合(数组)长度进行&运算,得到该对象在该数组存放的位置索引。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就表示发生冲突了,散列表对于冲突有具体的解决办法,但最终还会将新元素保存在适当的位置。
这样一来,实际调用equals方法比较的次数就大大降低了,几乎只需要一两次。
简而言之,在集合查找时,hashcode能大大降低对象比较次数,提高查找效率!
三、Java 对象的equal方法和hashCode方法的关系
首先,Java对象相同指的是两个对象通过eqauls方法判断的结果为true
Java对象的eqauls方法和hashCode方法是这样规定的:
1、相等(相同)的对象必须具有相等的哈希码(或者散列码)。
2、如果两个对象的hashCode相同,它们并不一定相同。
关于第一点,
想象一下,假如两个Java对象A和B,A和B相等(eqauls结果为true),但A和B的哈希码不同,则A和B存入HashMap时的哈希码计算得到的HashMap内部数组位置索引可能不同,那么A和B很有可能允许同时存入HashMap,显然相等/相同的元素是不允许同时存入HashMap,HashMap不允许存放重复元素。
关于第二点,
也就是说,不同对象的hashCode可能相同;假如两个Java对象A和B,A和B不相等(eqauls结果为false),但A和B的哈希码相等,将A和B都存入HashMap时会发生哈希冲突,也就是A和B存放在HashMap内部数组的位置索引相同这时HashMap会在该位置建立一个链接表,将A和B串起来放在该位置,显然,该情况不违反HashMap的使用原则,是允许的。当然,哈希冲突越少越好,尽量采用好的哈希算法以避免哈希冲突。
四、深入解析HashMap类的底层数据结构
Map接口
Map没有继承Collection接口,Map提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个 value。Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射。
Hashtable类
Hashtable继承Map接口,实现一个key-value映射的哈希表。任何非空(non-null)的对象都可作为key或者value。添加数据使用put(key, value),取出数据使用get(key),这两个基本操作的时间开销为常数。
Hashtable通过initial capacity和load factor两个参数调整性能。通常缺省的load factor 0.75较好地实现了时间和空间的均衡。增大load factor可以节省空间但相应的查找时间将增大,这会影响像get和put这样的操作。
使用Hashtable的简单示例如下,将1,2,3放到Hashtable中,他们的key分别是”one”,”two”,”three”:
Hashtable numbers = new Hashtable();
numbers.put(“one”, new Integer(1));
numbers.put(“two”, new Integer(2));
numbers.put(“three”, new Integer(3));
要取出一个数,比如2,用相应的key:
Integer n = (Integer)numbers.get(“two”);
System.out.println(“two = ” + n);
HashMap
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap的数据结构:
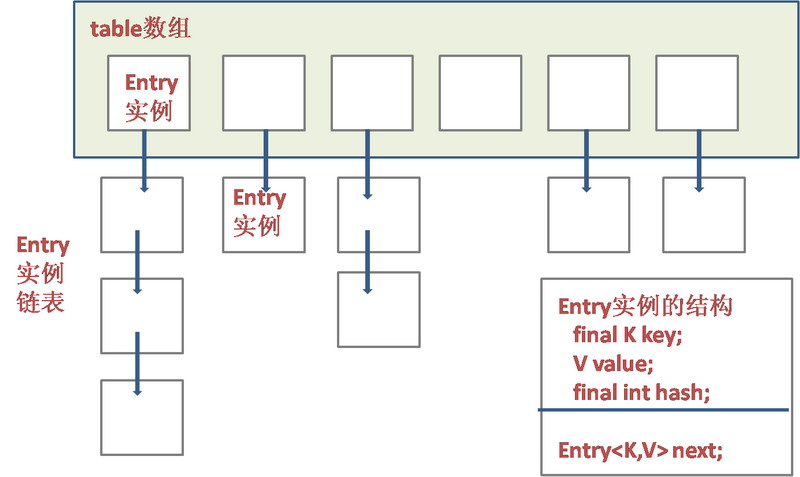
HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。首先,HashMap类的属性中定义了Entry类型的数组。Entry类实现java.ultil.Map.Entry接口,同时每一对key和value是作为Entry类的属性被包装在Entry的类中。
如图所示,HashMap的数据结构:
HashMap的部分源码如下:
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
……
}可以看出,HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组。table数组的元素是Entry类型的。每个 Entry元素其实就是一个key-value对,并且它持有一个指向下一个 Entry元素的引用,这就说明table数组的每个Entry元素同时也作为某个Entry链表的首节点,指向了该链表的下一个Entry元素,这就是所谓的“链表散列”数据结构,即数组和链表的结合体。
HashMap的存取实现:
1) 添加元素:
当我们往HashMap中put元素的时候,先根据key的重新计算元素的hashCode,根据hashCode得到这个元素在table数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
HashMap的部分源码如下:
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 如果发现 i 索引处的链表的某个Entry的hash和新Entry的hash相等且两者的key相同,则新Entry覆盖旧Entry,返回。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;2) 读取元素:
有了上面存储时的hash算法作为基础,理解起来这段代码就很容易了。从上面的源代码中可以看出:从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
HashMap的部分源码如下:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}3) 归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
五、实现相等的对象必须具有相等的哈希码
如果相同的对象有不同的hashCode,对哈希表的操作会出现意想不到的结果(期待的get方法返回null),要避免这种问题,只需要牢记一条:要同时复写equals方法和hashCode方法,而不要只写其中一个。
同时复写equals方法和hashCode方法,必须保证“相等的对象必须具有相等的哈希码”,也就是当两个对象通过equals()比较的结果为true时,这两个对象调用hashCode()方法生成的哈希码必须相等。
如何保证相等,可以参考下面的方法:
复写equals方法和hashCode方法时,equals方法的判断根据和计算hashCode的依据相同。如String的equals方法是比较字符串每个字符,String的hashCode也是通过对该字符串每个字符的ASC码简单的算术运算所得,这样就可以保证相同的字符串的hashCode相同且equals()为真。
String类的equals方法的源代码:
/**
* Compares this string to the specified object. The result is {@code
* true} if and only if the argument is not {@code null} and is a {@code
* String} object that represents the same sequence of characters as this
* object.
*
* @param anObject
* The object to compare this {@code String} against
*
* @return {@code true} if the given object represents a {@code String}
* equivalent to this string, {@code false} otherwise
*
* @see #compareTo(String)
* @see #equalsIgnoreCase(String)
*/
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = count;
if (n == anotherString.count) {
char v1[] = value;
char v2[] = anotherString.value;
int i = offset;
int j = anotherString.offset;
while (n-- != 0) {
if (v1[i++] != v2[j++])
return false;
}
return true;
}
}
return false;
}String类的hashCode方法计算hashCode的源代码:
/**
* Returns a hash code for this string. The hash code for a
* <code>String</code> object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using <code>int</code> arithmetic, where <code>s[i]</code> is the
* <i>i</i>th character of the string, <code>n</code> is the length of
* the string, and <code>^</code> indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
int len = count;
if (h == 0 && len > 0) {
int off = offset;
char val[] = value;
for (int i = 0; i < len; i++) {
h = 31*h + val[off++];
}
hash = h;
}
return h;
}















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









