







声明
HTML的解析过程是非常复杂的,下载、解析、脚本执行、显示是交错进行的。而且,HTML的解析器具有非常强的容错能力。
对于初次接触webkit源码的童鞋来说,是无法全面理解的。而且,本文立意也不是介绍HTMl的解析算法一类的东西。即便是我自己,对于很多东西都理解不了。
所以,本文重在解释HTML的解析过程,解说各个组成部分及功能。以后有机会,我将详细分析解析的算法。
解析过程中的重要类和功能
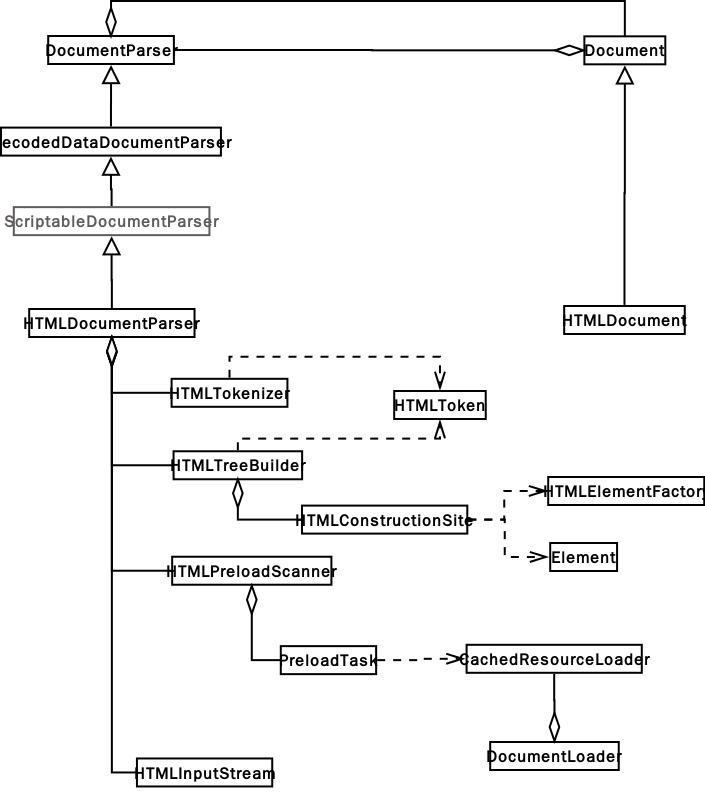
- Document和DocumentParser是相互引用的关系
- HTMLDocumentParser继承自ScriptableDocumentParser,在继承自DecodedDataDocumentParser。本文不讨论脚本相关问题,因此,可以忽略ScriptableDocumentParser。DecodedDataDocumentParser类主要功能就是实现字符解码功能。
- HTMLInputStream:保存解码后的字符流,可以看作一个缓冲区。和标准输入流的作用是一样的;
- HTMLTokenizer : 解析字符流解析,将字符流分解成节点(包括节点名和属性列表),注释、Doc声明、结束节点、文本(节点包含的文字),这些信息都保存在HTMLToken类中。其作用是词法解析器; 实现这个功能的主要函数是nextToken;
- HTMLTreeBuilder:它主要作用是生成DOM树,并对其语义进行检查(参阅processStartTag函数的代码)。如,如果在head标签中包含一个body标签,它就会检查出来,并报告错误。主要函数是constructTreeFromToken;
- HTMLToken:这是一个中间类,由HTMLTokenizer生成,交给HTMLTreeBuilder使用;
- HTMLConstructionSite : 这个类是负责创建HTML元素,并最终完成DOM树组装的函数。例如,它将标签 <img> 生成一个HTMLImageElement对象。 除了一些关键的标签外(如html, body, head等),其他标签的创建,通过HTMLElementFactory来实现; 对于属性的解析,直接调用生成的Element的parserSetAttributes函数,来实现。参阅HTMLConstructionSite::createHTMLElement函数的实现;
- HTMLPreloadScanner : 这是一个负责查找和加载子资源的对象。它通过扫描节点中的 "src" , "link"等属性,找到外部连接资源后,通过CachedResourceLoader进行预加载。CachedResourceLoader是从DocumentLoader中得到的。这一点可以参考前一章。
注意:HTMLElementFactory是通过脚本生成的,在源码中没有定义。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2098
2098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









