







 本文讲述了作者尝试编写一个Python爬虫,目标是抓取学校就业信息网上的公司名称、介绍链接和宣讲会信息。使用了BeautifulSoup库来解析网页,已成功提取公司名称和链接,计划进一步完善功能,包括提取剩余信息并实现短信通知。
本文讲述了作者尝试编写一个Python爬虫,目标是抓取学校就业信息网上的公司名称、介绍链接和宣讲会信息。使用了BeautifulSoup库来解析网页,已成功提取公司名称和链接,计划进一步完善功能,包括提取剩余信息并实现短信通知。
今天星期六OJ的蛋疼,于是就找点其他的事情干,忽然在知乎上看到一个帖子说自己找工作各种受挫的,找工作?于是就看到回答的人的签名是招聘员工的,觉得这个是不错的主意。是的,有点想写那么个能爬知乎签名的爬虫,并把招聘类的刷选出来的工具的冲动。后来觉得这个相当于把整个知乎遍历了一边,知乎能同意吗?那就爬自己学校的就业信息网吧。
上学校的就业信息网站 点击打开链接看看了,打开与源码瞄了一下,我是本科生在南校区,相关的代码是这样的:
<!--南校区招聘会安排-->
<div id="con_two_2" style="display:none;">
<table border="1" cellpadding="0" bordercolor="#333333">
<tr>
<td colspan="3"><font color="#ff0000">最新南校区招聘会安排(点公司名字查看详情)</font></td>
</tr>
<tr>
<td width="50%">公司</td>
<td width="20%">地点</td>
<td width="30%">时间</td>
</tr>
<tr>
<td><a href="/html/zpxx/nxqzph/2014/0924/25610.html" title="晶能光电(江西)有限公司" target="_blank">晶能光电(江西)有限公司</a> </td>
<td>就业中心116</td>
<td>14/10/25 9:00-12:00</td>
</tr></tr>
<tr>
<td><a href="/html/zpxx/nxqzph/2014/1015/26296.html" title="吉林华微电子股份有限公司" target="_blank">吉林华微电子股份有限公司</a> </td>
<td>D206</td>
<td>14/10/25 10:00-12:00</td>
</tr></tr>
我们的目标是把其中的公司名称,介绍链接,宣讲会时间和地点给爬出来。最后的目标是实现给定制的手机号码发送通知短信,截止到目前为止已经把公司名称,介绍链接提取出来来,后面会把其余的更新。
这里为了减少使用正则(其实爬虫的关键就是正则)使用了BeautifulSoup,相关的帮助文档可以看这里链接
下面上源码,由于中文容易出错,就用了英文注释,Python爬虫的入门教程可以看看这个博客链接,其实如果有Python和html等基础的话,写个爬虫就真的简单的不的了。
#!/usr/bin/python
# coding:utf-8
# FileName:Spider
# author:doodlesomething@163.com
# version:1.1
# date:10-24-2014
import urllib2
import sys
import re
import os
import urllib
import bs4
def Get_Page(GetUrl):
# set header to hidden
MyHeaders = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6',
'Referer':GetUrl,
'X-Forwarded-For':'127.0.0.1'
}
req = urllib2.Request(url = GetUrl,headers = MyHeaders)
# the following just to show what we have send
#httpHandler = urllib2.HTTPHandler(debuglevel = 1)
#httpsHandler = urllib2.HTTPSHandler(debuglevel = 1)
#opener = urllib2.build_opener(httpHandler,httpsHandler)
#urllib2.install_opener(opener)
# handle the error
try:
response = urllib2.urlopen(req)
except urllib2.URLError,e:
return e
content = response.read()
content = bs4.BeautifulSoup(content,from_encoding = 'GB18030')
return content
desUrl = 'http://job.xidian.edu.cn/index.html'
page_content = Get_Page(desUrl)
div =str(page_content.findAll('div',id='con_two_2')[0])
# Get more info link
reg = r'href="(.+?\.html)"'
urlreg = re.compile(reg)
urllist = re.findall(urlreg,div)
# Get company
reg_1 = r'title="(.+?)"'
treg = re.compile(reg_1)
tlist = re.findall(treg,div)
# output
i = 0
while i < len(tlist):
print 'company:%s' % tlist[i] + ' url:http://job.xidian.edu.cn%s'%urllist[i]
i += 1上张效果图:
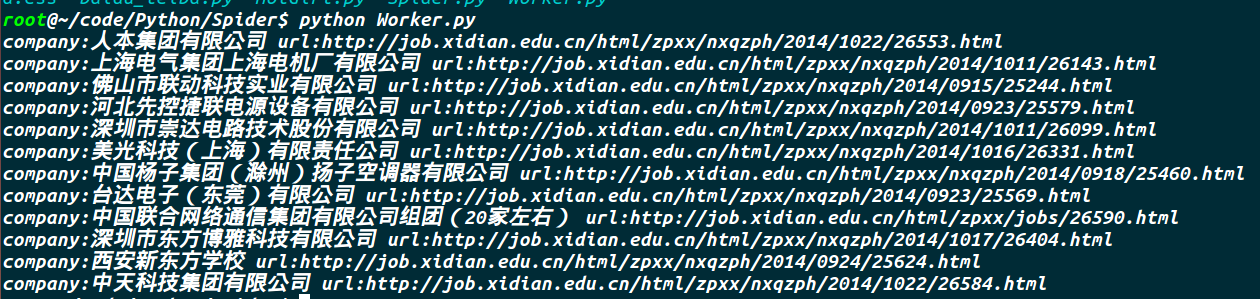
其实上面的代码就已经是简单爬虫的框架了,把相应的url和正则一改就可以用到其他地方了。之后有时间在相继的功能完善,其实还是我正则不过关,没把它写完整。















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









