







加载BeanDefinition
当然我们不可能为每一个类手动编写与之对应的BeanDefinition,元数据还是要从xml或注解或配置类中获取,spring也为我们提供了对应的工具。
1、读取xml配置文件
该类通过解析xml完成BeanDefinition的读取,并且将它解析的BeanDefinition注册到一个注册器中:
@Test
public void testRegistryByXml(){
// 定义一个注册器,用来注册和管理BeanDefinition
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
// 通过xml文件加载
XmlBeanDefinitionReader xmlReader = new XmlBeanDefinitionReader(registry);
xmlReader.loadBeanDefinitions("classpath:spring.xml");
logger.info(Arrays.toString(registry.getBeanDefinitionNames()));
}
原理后边介绍。
2、加载带注解的bean
@Test
public void testRegistryByAnnotation(){
// 定义一个注册器,用来注册和管理BeanDefinition
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
// 通过配置文件加载
AnnotatedBeanDefinitionReader annoReader = new AnnotatedBeanDefinitionReader(registry);
annoReader.register(User.class);
logger.info(Arrays.toString(registry.getBeanDefinitionNames()));
}
3、读取配置类
ConfigurationClassBeanDefinitionReader可以读取配置类,只是这个类不让我们使用,该类提供了如下方法:
private void loadBeanDefinitionsForConfigurationClass
private void registerBeanDefinitionForImportedConfigurationClass
private void loadBeanDefinitionsForBeanMethod(BeanMethod beanMethod)
他会将读取的元数据封装成为:ConfigurationClassBeanDefinition。
4、类路径扫描
@Test
public void testRegistryByScanner(){
// 定义一个注册器,用来注册和管理BeanDefinition
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
// 通过扫描包的方式
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(registry);
scanner.scan("com.ydlclass");
logger.info(Arrays.toString(registry.getBeanDefinitionNames()));
}
5、包扫描的过程
无论是扫包还是其他方式,我们我们解析一个类无非有几种方式:
- 加载一个类到内存,获取Class对象,通过反射获取元数据
- 直接操纵字节码文件(.class),读取字节码内的元数据
毫无疑问spring选择了第二种,
- 首先:第二种性能要优于第一种
- 其次:第一种会将扫描的类全部加载到堆内存,无疑会浪费空间,增加gc次数,第二种可以根据元数据按需加载
我们以包扫描的doScan方法为例(ClassPathBeanDefinitionScanner类):
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
// BeanDefinitionHolder持有 BeanDefinition实例和名字以及别名
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 这里是具体的扫描过程,找出全部符合过滤器要求的BeanDefinition
// 返回的BeanDefinition的实际类型为ScannedGenericBeanDefinition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 根据不同的bean类型做统一处理,如附默认值等
// 因为有些数据我们并没有配置,需要这里做默认处理
for (BeanDefinition candidate : candidates) {
// 如果存在,则解析@Scope注解,为候选bean设置代理的方式ScopedProxyMode,XML属性也能配置:scope-resolver、scoped-proxy,可以指定代理方式jdk或者cglib
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 首先从注解中获取bean的名字,如果没有
// 使用beanName生成器beanNameGenerator来生成beanName
// 在注解中的bean的默认名称和xml中是不一致的
// 注解中如果没有指定名字本质是通过ClassUtil 的 getShortName 方法获取的
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 将进一步设置应用于给定的BeanDefinition,使用AbstractBeanDefinition的一些默认属性值
//设置autowireCandidate属性,即XML的autowire-candidate属性,IoC学习的时候就见过该属性,默认为true,表示该bean支持成为自动注入候选bean
if (candidate instanceof AbstractBeanDefinition) { postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 如果bean定义是AnnotatedBeanDefinition类型,ScannedGenericBeanDefinition同样属于AnnotatedBeanDefinition类型
if (candidate instanceof AnnotatedBeanDefinition) {
// 4 处理类上的其他通用注解:@Lazy, @Primary, @DependsOn, @Role, @Description
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 检查给定的 beanName,确定相应的bean 定义是否需要注册或与现有bean定义兼容
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
// 根据proxyMode属性的值,判断是否需要创建scope代理,一般都是不需要的
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
我们可以紧接着看看其中很重要的一个方法:
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
// Spring5的新特性,直接从"META-INF/spring.components"组件索引文件中加载符合条件的bean,避免了包扫描,用于提升启动速度
// Spring5升级的其中一个重点就提升了注解驱动的启动性能,"META-INF/spring.components"这个文件类似于一个“组件索引”文件,我们将需要加载的组件(beean定义)预先的以键值对的样式配置到该文件中,当项目中存在"META-INF/spring.components"文件并且文件中配置了属性时,Spring不会进行包扫描,而是直接读取"META-INF/spring.components"中组件的定义并直接加载,从而达到提升性能的目的。
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
当然我们更加关注的是scanCandidateComponents方法:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 生成完整的资源解析路径! 就是一个字符串的拼接。。。。
// com.ydlclass -> classpath*:com/ydlclass/**/*.class
// 关于资源解析的内容会在后边的课程单独讲
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 加载所有路径下的资源,我们看到前缀是"classpath*",因此项目依赖的jar包中的相同路径下资源都会被加载进来
// Spring会将每一个定义的字节码文件加载成为一个Resource资源(包括内部类都是一个Resource资源)
// 此处是以资源(流)的方式加载(普通文件),而不是将一个类使用类加载器加载到jvm中。
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
// 遍历所有的资源文件
for (Resource resource : resources) {
String filename = resource.getFilename();
// 此处忽略CGLIB生成的代理类文件,这个应该不陌生
if (filename != null && filename.contains(ClassUtils.CGLIB_CLASS_SEPARATOR)) {
continue;
}
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
try {
// getMetadataReader方法会生成一个元数据读取器
// 我们的例子中是SimpleMetadataReader
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 检查读取到的类是否可以作为候选组件,即是否符合TypeFilter类型过滤器的要求
// 使用IncludeFilter。就算目标类上没有@Component注解,它也会被扫描成为一个Bean
// 使用ExcludeFilter,就算目标类上面有@Component注解也不会成为Bean
if (isCandidateComponent(metadataReader)) {
// 构建一个ScannedGenericBeanDefinition
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
}
}
}
}
return candidates;
}
上边的源码中我们看到读取类文件的真实的实例是simpleMetadataReader,spring选用了**【read+visitor】的方式来读取字节码**,read负责暴露接口,visitor负责真正的读取工作:
final class SimpleMetadataReader implements MetadataReader {
SimpleMetadataReader(Resource resource, @Nullable ClassLoader classLoader) throws IOException {
SimpleAnnotationMetadataReadingVisitor visitor = new SimpleAnnotationMetadataReadingVisitor(classLoader);
// 这里是核心,一个reader需要结合一个visitor
getClassReader(resource).accept(visitor, PARSING_OPTIONS);
this.resource = resource;
// 元数据都是visitor的能力,典型的访问者设计模式
this.annotationMetadata = visitor.getMetadata();
}
// 通过资源获取一个ClassReader
private static ClassReader getClassReader(Resource resource) throws IOException {
try (InputStream is = resource.getInputStream()) {
try {
return new ClassReader(is);
}
}
}
// 提供了通用能力
@Override
public ClassMetadata getClassMetadata() {
return this.annotationMetadata;
}
@Override
public AnnotationMetadata getAnnotationMetadata() {
return this.annotationMetadata;
}
}
SimpleAnnotationMetadataReadingVisitor类使用了大量asm的内容,由此可见spring在读取元数据的时候,是直接读取class文件的内容,而非加载后通过反射获取,我们列举其中的个别属性和方法,大致能窥探一二:
import org.springframework.asm.AnnotationVisitor;
import org.springframework.asm.ClassVisitor;
import org.springframework.asm.MethodVisitor;
import org.springframework.asm.Opcodes;
import org.springframework.asm.SpringAsmInfo;
final class SimpleAnnotationMetadataReadingVisitor extends ClassVisitor {
// 访问一个内部类的方法
@Override
public void visitInnerClass(String name, @Nullable String outerName, String innerName, int access) {
// ...省略
}
// 访问注解的方法
@Override
@Nullable
public AnnotationVisitor visitAnnotation(String descriptor, boolean visible) {
// ...省略
}
// 访问方法的方法
@Override
@Nullable
public MethodVisitor visitMethod(
// ...省略
}
// ...省略
}
例子:
@Test
public void testAsm() throws IOException {
Resource resource = new ClassPathResource("com/ydlclass/User.class");
ClassReader classReader = new ClassReader(resource.getInputStream());
logger.info(classReader.getClassName());
// 缺少visitor的reader能力优先,我们只做几个简单的实现
// visitor实现相对复杂,我们没有必要去学习
// classReader.accept(xxxVisitor);
// 返回的对应的常量池的偏移量+1
// 0-3 cafebaba 4-7 主次版本号 8-9 第一个是10+1
// 二进制可以使用bined插件查看
logger.info("The first item is {}.",classReader.getItem(1));
logger.info("The first item is {}.",classReader.getItem(2));
// 00 3A 这是字节码文件看到的,
// 常量池的计数是 1-57 0表示不引用任何一个常量池项目
logger.info("The first item is {}.",classReader.getItemCount());
// 通过javap -v .\User.class class文件访问标志
// flags: (0x0021) ACC_PUBLIC, ACC_SUPER 十进制就是33
// ACC_SUPER 0x00 20 是否允许使用invokespecial字节码指令的新语义.
// ACC_PUBLIC 0x00 01 是否为Public类型
logger.info("classReader.getAccess() is {}",classReader.getAccess());
}
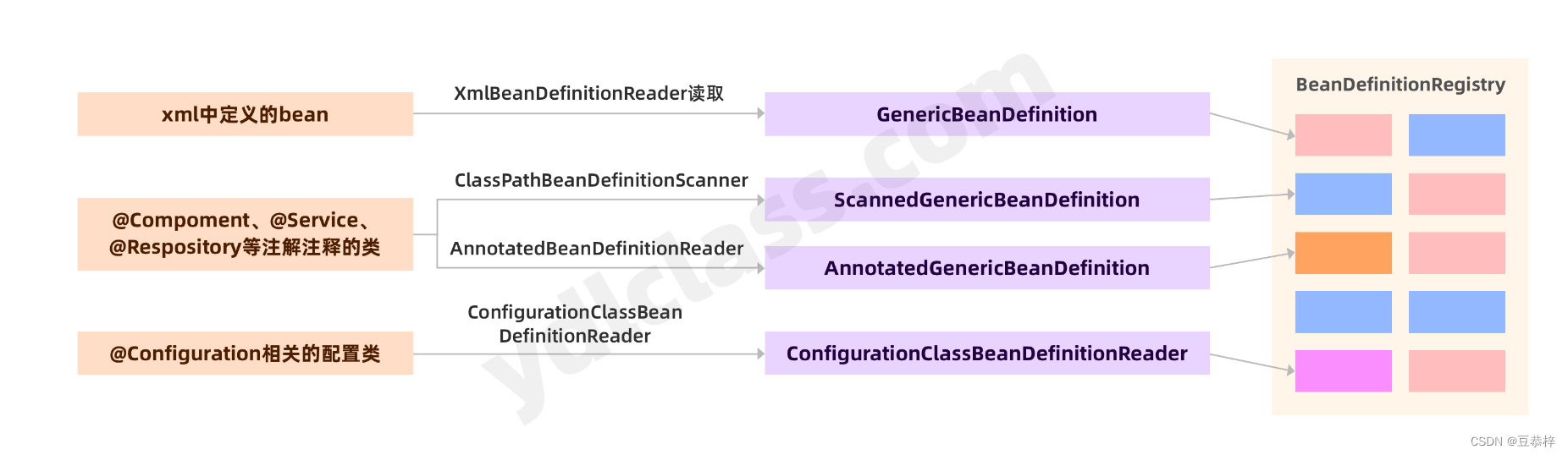
注:不同的扫描方式形成了不同的Definition子类如下:














 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









