






引言
在人工智能与多媒体技术蓬勃发展的当下,定制化 AI 数字人正逐渐走进人们的视野,广泛应用于娱乐、教育、客服等多个领域。通过源码搭建定制化 AI 数字人系统,能够满足特定场景下的个性化需求,为用户带来独特的交互体验。本文将深入探讨定制化 AI 数字人源码搭建的技术开发要点,助力开发者构建独具特色的数字人系统。
技术架构概述
整体架构设计
定制化 AI 数字人系统通常包含多个层次。底层是硬件基础设施,涵盖高性能计算机、图形加速卡(如 NVIDIA GPU)以支持复杂的计算任务,以及大容量存储设备用于存储数字人模型、训练数据等。中间层为核心技术层,集成了 3D 建模、动作捕捉、语音合成、自然语言处理以及深度学习等关键技术。最上层则是面向用户的应用层,提供直观的交互界面,实现数字人的展示、控制与应用场景集成。各层之间通过精心设计的接口和数据传输机制协同工作,确保系统的高效稳定运行。
技术栈选型
- 编程语言:Python 凭借其丰富的库和简洁的语法,成为开发定制化 AI 数字人的首选语言。在处理深度学习模型训练、数据处理以及与各类工具的集成方面,Python 具有显著优势。例如,使用 PyTorch 或 TensorFlow 框架进行神经网络模型开发时,Python 的便利性使得代码编写和调试更加高效。
- 深度学习框架:PyTorch 和 TensorFlow 是构建 AI 数字人深度学习模型的主流框架。PyTorch 以其动态计算图和易于调试的特性,在模型研究和开发阶段表现出色;TensorFlow 则在大规模生产环境中展现出良好的稳定性和分布式训练能力。开发者可根据项目需求和个人偏好选择合适的框架。
- 3D 建模与动画软件:Blender、Maya 等专业 3D 建模与动画软件用于创建数字人的 3D 模型、骨骼动画以及材质纹理。这些软件功能强大,能够实现高度逼真的数字人形象设计。同时,它们支持与其他工具和库的交互,方便将创建好的模型和动画集成到系统中。
- 语音与自然语言处理库:在语音合成方面,可使用 Tacotron、WaveNet 等深度学习模型,通过相应的 Python 库进行实现。对于自然语言处理,NLTK(Natural Language Toolkit)和 SpaCy 等库提供了丰富的工具和算法,用于文本预处理、词性标注、语义分析等任务。
关键技术模块实现
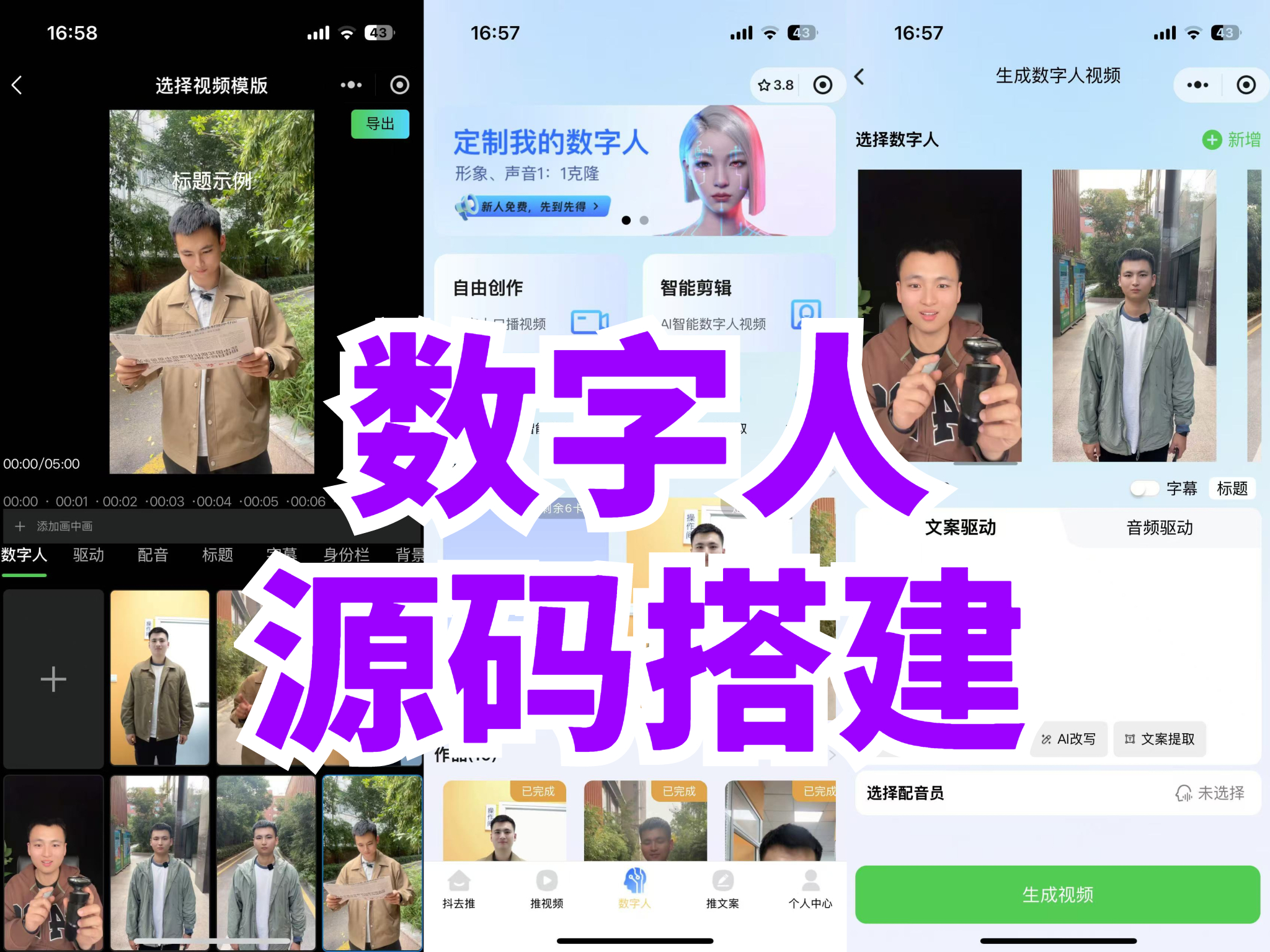
数字人形象创建
- 3D 模型构建:利用 3D 建模软件从基础几何体开始搭建数字人模型。通过细分曲面、雕刻工具等技术手段,逐步细化模型的面部特征、身体结构以及服饰细节。例如,在 Blender 中,使用雕刻模式可以精细地塑造数字人的面部五官,使其具有独特的个性和逼真的质感。在建模过程中,要注重模型的拓扑结构,确保在后续的动画制作和渲染过程中能够流畅运行。
- 材质与纹理映射:为数字人模型赋予材质,模拟真实的皮肤、头发、衣物等材质效果。借助纹理映射技术,将高质量的纹理图像(如皮肤纹理、衣服图案)映射到模型表面,增强模型的真实感。可以使用 Substance Painter 等软件创建和编辑纹理,然后将其应用到 3D 模型中。例如,对于数字人的皮肤材质,通过在 Substance Painter 中调整纹理参数,可以实现皮肤的光泽度、粗糙度以及细微的瑕疵效果,使数字人看起来更加真实可信。
- 骨骼绑定与动画制作:在 3D 模型中添加骨骼系统,并将骨骼与模型网格进行绑定,实现对模型动作的控制。运用关键帧动画、路径动画等技术,制作数字人的各种动作,如行走、奔跑、挥手、说话等。以 Maya 软件为例,通过设置关键帧,精确调整骨骼关节的角度和位置,从而生成流畅自然的动画序列。同时,为了提高动画的效率和可复用性,可以创建动画库,将常用的动画片段保存下来,方便在不同的场景中使用。
语音交互功能实现
- 语音识别:采用深度学习语音识别模型,如基于卷积神经网络(CNN)和循环神经网络(RNN)的模型,将用户的语音转换为文本。在 Python 中,可以使用 Kaldi、DeepSpeech 等语音识别框架。这些框架通过对大量语音数据的学习,能够准确识别不同口音、语速的语音。例如,DeepSpeech 基于百度的 DeepSpeech 模型,通过训练大规模的语音数据集,实现了较高的语音识别准确率。
- 自然语言处理:对识别出的文本进行自然语言处理,理解用户的意图。使用 NLTK 或 SpaCy 库进行文本预处理,包括分词、词性标注、命名实体识别等。然后,利用深度学习模型,如循环神经网络(RNN)的变体长短时记忆网络(LSTM)或门控循环单元(GRU),进行语义理解和意图分类。例如,构建一个基于 LSTM 的文本分类模型,对用户的问题进行分类,判断其是咨询产品信息、寻求帮助还是进行其他操作。
- 语音合成:将自然语言处理生成的回复文本转换为语音。使用 Tacotron、WaveNet 等语音合成模型,通过对大量语音数据的学习,生成自然流畅的语音。在 Python 中,可以使用相关的库实现这些模型。例如,Tacotron 模型通过将文本转换为梅尔频谱,再利用声码器将梅尔频谱转换为语音波形,实现高质量的语音合成。
表情与动作生成
- 表情生成:利用计算机视觉技术,从真实人物的面部表情图像或视频中提取表情特征,如面部关键点的位移、肌肉的运动等。将这些表情特征作为输入,训练神经网络模型,生成数字人的面部表情动画。例如,使用 OpenCV 检测面部关键点,然后结合生成对抗网络(GAN)生成逼真的数字人表情。在生成表情时,要考虑表情的自然过渡和合理性,避免出现生硬或不自然的表情效果。
- 动作生成:通过动作捕捉设备获取真实人物的动作数据,或者从视频中提取人物动作并进行分析。使用循环神经网络(RNN)或其变体,如长短时记忆网络(LSTM),对动作数据进行建模,生成数字人的动作序列。输入特定的动作描述或文本指令,模型能够生成符合要求的动作,使数字人做出相应的行为。例如,输入 “向前走三步然后转身” 的指令,模型能够根据训练学习到的动作模式,生成对应的数字人动作动画。
系统集成与优化
- 模型集成:将数字人形象创建、语音交互、表情与动作生成等各个模块的模型进行集成,确保它们能够协同工作。在集成过程中,要注意模型之间的数据传输和接口兼容性。例如,将语音识别模型输出的文本数据作为自然语言处理模型的输入,将自然语言处理模型生成的回复文本作为语音合成模型的输入,同时将表情与动作生成模型与语音合成模型进行同步,实现数字人的语音与表情、动作的协调一致。
- 性能优化:对整个系统进行性能优化,提高数字人的响应速度和运行效率。在模型训练阶段,采用优化算法,如随机梯度下降(SGD)及其变体 Adagrad、Adadelta、Adam 等,加快模型的收敛速度。对模型进行压缩和量化,减少模型的参数数量和存储占用,提高模型的推理速度。在系统运行阶段,优化代码实现,减少不必要的计算和资源开销,采用缓存机制,提高数据访问效率。
开发流程详解
数据收集与预处理
- 数据收集:收集用于训练模型和创建数字人形象的各类数据。包括高质量的人物面部图像和视频数据,用于表情生成和唇形同步模型的训练;动作捕捉数据或人物动作视频,用于动作生成模型的训练;大量的语音文本对,用于语音合成和语音识别模型的训练。同时,收集不同风格和场景的数字人应用案例,作为定制化开发的参考。
- 数据预处理:对收集到的数据进行预处理,以提高数据的质量和可用性。对于图像和视频数据,进行裁剪、缩放、归一化等操作;对于语音数据,进行降噪、分帧、特征提取等处理。在数据预处理过程中,要注意保持数据的一致性和准确性,避免引入错误或偏差。例如,对于面部图像数据,统一将图像大小调整为相同的分辨率,并对图像进行标准化处理,以便于后续的模型训练。
模型训练与评估
- 模型选择与搭建:根据不同的功能需求,选择合适的深度学习模型,并进行搭建和配置。例如,对于语音合成任务,选择 Tacotron 模型,并根据数据集的特点调整模型的参数,如网络层数、隐藏单元数量等。在搭建模型时,要遵循深度学习的最佳实践,确保模型的结构合理、易于训练和优化。
- 训练过程:使用预处理好的数据对模型进行训练。在训练过程中,选择合适的损失函数和优化算法,如交叉熵损失函数和 Adam 优化算法。设置合理的训练参数,如学习率、批量大小、训练轮数等,并实时监控模型的训练进度和性能指标。例如,在训练表情生成模型时,使用均方误差(MSE)作为损失函数,通过不断调整模型参数,使生成的表情与真实表情之间的误差最小化。
- 模型评估:定期对训练好的模型进行评估,使用验证集和测试集来评估模型的性能。评估指标包括准确率、召回率、F1 值等。根据评估结果,对模型进行调整和优化,如调整模型结构、增加训练数据、调整训练参数等,以提高模型的泛化能力和性能表现。
系统测试与部署
- 功能测试:对定制化 AI 数字人系统的各项功能进行全面测试,包括数字人形象的展示、语音交互的准确性、表情与动作生成的合理性等。检查系统是否能够按照预期工作,是否存在功能缺陷或异常情况。例如,测试语音识别的准确率,检查数字人的表情和动作是否与语音内容同步。
- 性能测试:对系统的性能进行测试,包括模型的推理速度、系统的响应时间、资源占用情况等。通过性能测试,评估系统是否能够满足实际应用的需求。例如,测试在不同硬件配置下,数字人系统生成一个回复所需的时间,以及系统在高并发情况下的稳定性。
- 部署上线:将经过测试和优化的定制化 AI 数字人系统部署到实际应用环境中。根据应用场景的需求,选择合适的部署方式,如云端部署、本地部署或混合部署。在部署过程中,要确保系统的安全性和稳定性,进行必要的安全配置和监控设置。
技术挑战与解决方案
计算资源需求
- 挑战:定制化 AI 数字人系统涉及大量的计算任务,如深度学习模型的训练和推理、3D 模型的渲染、视频的处理等,对计算资源的需求极高。在实际应用中,可能面临计算资源不足导致系统运行缓慢甚至无法正常工作的问题。
- 解决方案:采用高性能的硬件设备,如配备多核 CPU、高性能 GPU 的工作站或服务器。利用云计算平台,如阿里云、腾讯云等,按需租用计算资源,降低硬件成本。同时,对模型进行优化,采用模型压缩、量化等技术,减少模型的参数数量和计算量;对代码进行优化,提高代码的执行效率,如使用并行计算技术加速视频处理任务。
数据质量与数量
- 挑战:高质量的数据是训练出优秀模型的基础,但数据的收集和标注成本高昂。同时,数据的数量和多样性不足,可能导致模型的泛化能力差,无法适应复杂多变的应用场景。
- 解决方案:采用数据增强技术,对现有数据进行变换,如对图像进行旋转、缩放、裁剪,对语音进行变速、变调等操作,扩充数据量。利用众包平台或自动化标注工具,提高数据标注的效率和准确性。此外,与专业的数据供应商合作,获取高质量、大规模的数据,丰富数据的多样性。
模型的可解释性与稳定性
- 挑战:深度学习模型通常是复杂的黑盒模型,其决策过程难以解释。同时,模型在不同的数据集和环境下可能表现不稳定,影响系统的可靠性和用户体验。
- 解决方案:研究可解释性的深度学习技术,如可视化技术、注意力机制等,帮助理解模型的决策过程。在模型训练过程中,采用正则化技术、模型融合等方法,提高模型的稳定性和泛化能力。同时,建立模型监控机制,实时监测模型的性能指标,及时发现和解决模型漂移等问题。
总结
定制化 AI 数字人源码搭建是一个综合性强、技术难度高的工程,涉及多个领域的前沿技术。通过合理的技术架构设计、精心的关键技术模块实现、严谨的开发流程以及有效的技术挑战应对,能够构建出功能强大、性能优良的定制化 AI 数字人系统。随着技术的不断发展和创新,定制化 AI 数字人将在更多的领域得到广泛应用,为用户带来全新的交互体验。希望本文能够为广大开发者提供有价值的技术参考,助力他们在定制化 AI 数字人开发领域取得成功。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









