







即插入排序、冒泡排序、选择排序、shell排序、基数排序、归并排序、快速排序、堆排序
一、(直接)插入法(交换排序)
1、原理方法
从第二个数开始与前面的一个一个比较,小于则交换、大于等于则下一个数的循环。
2、特点
1)、稳定性:稳定
2)、时间代价:O(n*n)
最好——正序——时间代价Θ(n)
最差——倒序——时间代价Θ(n*n)
平均——乱序——时间代价Θ(n*n)
3)、辅助存储空间:O(1)
4)、比较
①较为复杂、速度较慢
②n较小时(如<=50) 、局部或整体有序时适用
插入排序的最佳时间代价特性——基本有序。
③循环交换
循环不同:f(n)<=1/2*n*(n-1)<=1/2*n*n
交换不同(赋值操作)
3、代码
#include <iostream>
using namespace std;
void InsertSort(int* , int );
int main()
{
int data[]={1,-30,12,7,-1,5,4};
InsertSort(data,7);
for(int i=0;i<7;i++)
cout<<dec<<data[i]<<" ";
cout<<"\n";
//system ( "pause" );//getchar();
return 0;
}
void InsertSort(int* pData,int Count)
{
int iTemp;
int iPos;
for(int i=1;i<Count;i++)
{
iPos=i-1;
iTemp=pData[i];
while((iPos>=0)&&(iTemp<pData[iPos]))
{
pData[iPos+1]=pData[iPos];
iPos--;
}
pData[iPos+1]=iTemp;
}
}二、 冒泡法( 交换排序 )
1、原理方法
1)、把小的元素往前调或者把大的元素往后调, 一趟得到一个最大值或最小值。
若循环外设一个bool变量、最差(倒序)循环n-1趟、最好(正序)循环一趟
2)、有递归和非递归实现
2、特点
1)、稳定性:稳定
2)、时间代价:
最好——正序、无交换(O(0))——时间代价Θ(n)(只循环一趟)
最差——倒序、循环次数=交换次数(O(n*n))——时间代价Θ(n*n)
平均——乱序、中间状态 ——时间代价Θ(n*n)
3)、辅助存储空间:O(1)
4)、比较
①速度较慢、交换次数相对比较多
②n较小时(如<=50) ,局部或整体有序时、较快
③循环交换
循环相同(若循环外不设判断条件):
1+2+...+n-1=1/2*(n-1)*n<=1/2*n*n=K*g(n)
f(n)=O(g(n))=O(n*n)(循环复杂度)
交换不同
3、代码
1)、非递归循环实现
#include <iostream>
using namespace std;
void BubbleSort(int* , int );
int main()
{
int data[]={10,9,13,7,32,5,2};
BubbleSort(data,7);
for(int i=0;i<7;i++)
cout<<dec<<data[i]<<" ";
cout<<"\n";
return 0;
}
void BubbleSort(int* pData,int n)
{
int iTemp;
bool bFilish=fale;
for(int i=0;i<n-1;i++)
{
if(bFlish=true)
break;
bFilish=true;
for(int j=n-1;j>i;j--)
{
if(pData[j]<pData[j-1])
{
iTemp=pData[j-1];
pData[j-1]=pData[j];
pData[j]=iTemp;
bFilish=false;
}
}
}
}
#include <iostream>
using namespace std;
void BilateralBubbleSort(int* , int,int );
int main()
{
int data[]={10,9,13,7,32,5,2};
BilateralBubbleSort(data,0,6);
for(int i=0;i<7;i++)
cout<<dec<<data[i]<<" ";
cout<<"\n";
return 0;
}
void BilateralBubbleSort(int *a, int first, int last)
{
if (first >= last) //退出条件
{
return;
}
int i = first;
int j = last;
int temp = a[first];
while (i != j)
{
while (i<j && a[j]>=temp)
{
j--;
}
a[i] = a[j];
while (i<j && a[i]<=temp)
{
i++;
}
a[j] = a[i];
}
a[i] = temp;
//递归,有点像快速排序,就是中间值放在临时变量而不是数组尾部
BilateralBubbleSort(a, first, i-1);
BilateralBubbleSort(a, i+1, last);
}
三、(简单或直接)选择法( 交换排序 )
1、原理方法
1)、第一个元素开始,同其后的元素比较并记录最小值(放在当前位置)。
每次得到一个最小值
2)、(改进)选择中间变量、减少交换次数
2、特点
1)、稳定性:不稳定
2)、时间代价:O(n*n)
最好——正序、无交换(O(0))
最差——倒序、循环次数=交换次数
平均—— 乱序、中间状态
3)、辅助存储空间:O(1)
4)、比较
①速度较慢
②与冒泡法某些情况下稍好,在某些情况下稍差
这3种中是很有效的, n较小时(如<=50) 适用
③循环交换
循环相同:
1/2*(n-1)*n
交换不同
3、代码
#include <iostream>
using namespace std;
void SelectSort(int* , int );
int main()
{
int data[]={1,9,12,7,26,5,4};
SelectSort(data,7);
for(int i=0;i<7;i++)
cout<<dec<<data[i]<<" ";
cout<<"\n";
return 0;
}
void SelectSort(int* pData,int Count)
{
int iTemp;
for(int i=0;i<Count-1;i++)
{
for(int j=i+1;j<Count;j++)
{
if(pData[i]<pData[j])
{
iTemp=pData[i];
pData[i]=pData[j];
pData[j]=iTemp;
}
}
}
}四、快速排序
1、原理方法
1)、分治法
2)、二叉查找树
像一个二叉树、递归实现
①(分割)首先选择一个轴值,如放在数组最后
②把比它小的放在左边,大的放在右边(两端移动下标,找到一对后交换)。
③直到相遇、返回下标k(右半部起始、即轴值下标)
④然后对两边分别使用这个过程
3)、轴值的选取
①第一个记录的关键码(正、逆序时有问题)
②随机抽取轴值(开销大)
③数组中间点(一般)
4)、最理想的情况
①数组的大小是2的幂,这样分下去始终可以被2整除
假设为2的k次方,即k=log2(n)。
②每次我们选择的值刚好是中间值、数组可以被等分。
第一层递归,循环n次,第二层循环2*(n/2)......
所以共有n+2(n/2)+4(n/4)+...+n*(n/n) = n+n+n+...+n=k*n=log2(n)*n
所以算法复杂度为O(n*log2(n))
其他的情况只会比这种情况差,最差的情况是每次选择到的middle都是最小值或最大值,那么他将变成交换法(由于使用了递归,情况更糟)。
2、特点
1)、稳定性:不稳定
2)、时间代价:O(n*logn)
最差——O(n*n)
平均——O(n*logn),介于最佳和最差之间
最好——O(n*logn)
3)、辅助存储空间:O(logn)
4)、比较
①局部或整体有序时慢
②(大多数情况)平均最快
n(≥9)较大时、关键字元素比较随机(杂乱无序)适用
③分割数组,多交换、少比较
3、代码
1)、一般的方法
#include<iostream>
using namespace std;
typedef int* IntArrayPtr;
int Divide(int a[],int left,int right)
{
int k=a[left]; //轴值
do
{
while(left<right&&a[right]>=k) --right;
if(left<right)
{
a[left]=a[right];
++left;
}
while(left<right&&a[left]<=k)++left;
if(left<right)
{
a[right]=a[left];
--right;
}
}while(left!=right);
//排序后轴值位置,分为两个子序列
a[left]=k;
return left;
}
void QuickSort(int a[],int left,int right)
{
int mid;
if(left>=right)return;
mid=Divide(a,left,right);
cout<<a[mid]<<'\n';
for(int j=left;j<=right;j++)
cout<<a[j]<<" ";
cout<<'\n';
//轴值左半部分
QuickSort(a,left,mid-1);
//轴值右半部分
QuickSort(a,mid+1,right);
}
void FillArray(int a[],int size)//输入数据
{
cout<<"请输入"<<size<<"个整数,数字之间用空格隔开:"<<endl;
for(int index=0;index<size;index++)
cin>>a[index];
}
void main()
{
int array_size;
cout<<"请输入需要排序的元素个数:";
cin>>array_size;
IntArrayPtr a;
a=new int[array_size];//动态数组
FillArray(a,array_size);
cout<<'\n'<<"快速排序开始:"<<endl;
QuickSort(a, 0, array_size-1);
cout<<"end"<<'\n';
for(int k=0;k<array_size;k++)
{
cout<<a[k]<<" ";
}
cout<<'\n';
system("pause");//getchar();
}
2)、剑指offer上一个比较好的方法,保存了数组的两个位置index向前遍历数组,small用于保存交换的小于轴值的数,找到一个前移一步。
#include "stdafx.h"
#include <stdlib.h>
#include <exception>
int RandomInRange(int min, int max) //随机轴值
{
int random = rand() % (max - min + 1) + min;
return random;
}
void Swap(int* num1, int* num2)
{
int temp = *num1;
*num1 = *num2;
*num2 = temp;
}
int Partition(int data[], int length, int start, int end)
{
if(data == NULL || length <= 0 || start < 0 || end >= length)
throw new std::exception("Invalid Parameters");
int index = RandomInRange(start, end);
Swap(&data[index], &data[end]);
int small = start - 1;
for(index = start; index < end; ++ index)
{
if(data[index] < data[end])
{
++ small;
if(small != index)
Swap(&data[index], &data[small]);
}
}
++ small;
Swap(&data[small], &data[end]);
return small;
}
//递归快速排序
void QuickSort(int data[], int length, int start, int end)
{
if(start=end)
reurn;
int index=Partition(data, length, start, end);
if(index>start)
QuickSort(data, length, start, index-1);
if(index<end)
QuickSort(data, length, index+1.end);
}
五、Shell排序(缩小增量排序)(局部用的插入排序)
1、原理方法
由于复杂的数学原因避免使用2的幂次步长,它能降低算法效率
子序列——每轮等数量(大到小)、等增量、等长度——插入排序——合并再重复
实现:
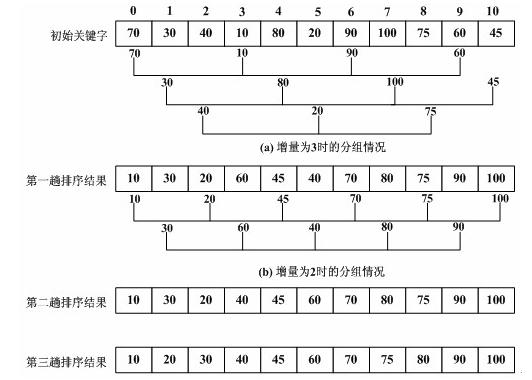
(1)初始增量为3,该数组分为三组分别进行排序。(初始增量值原则上可以任意设置
(0<gap<n),没有限制)
(2)将增量改为2,该数组分为2组分别进行排序。
(3)将增量改为1,该数组整体进行排序。
2、特点
1)、稳定性:不稳定
2)、时间代价——依赖于增量序列
最好 最差

平均——(约)增量除3时是O(n1.5)、O(n*logn}~O(n2)
3)、辅助存储空间:O(1)
4)、比较
①规模非常大的数据排序不是最优选择
②n为中等规模时是不错的选择
3、代码
#include <iostream>
using namespace std;
int a[] = {70,30,40,10,80,20,90,100,75,60,45};
void shell_sort(int a[],int n);
int main()
{
cout<<"Before Sort: ";
for(int i=0; i<11; i++)
cout<<a[i]<<" ";
cout<<endl;
shell_sort(a, 11);
cout<<"After Sort: ";
for(int i=0; i<11; i++)
cout<<a[i]<<" ";
cout<<endl;
system("pause"); //getchar();//gcc中没有system("pause");命令
}
void shell_sort(int a[], int n)
{
for(int gap = 3; gap >0; gap--)
{
for(int i=0; i<gap; i++)
{
for(int j = i+gap; j<n; j=j+gap)
{
if(a[j]<a[j-gap])
{
int temp = a[j];
int k = j-gap;
while(k>=0&&a[k]>temp)
{
a[k+gap] = a[k];
k = k-gap;
}
a[k+gap] = temp;
}
}
}
}
}六、归并排序
1、原理方法
分治法、归并操作(算法)、稳定有效的排序方法(直接插入)、等长子序列
1)、归并操作。
设有数列{6,202,100,301,38,8,1}
初始状态:6,202,100,301,38,8,1
第一次归并后:{6,202},{100,301},{8,38},{1},比较次数:3;
第二次归并后:{6,100,202,301},{1,8,38},比较次数:4;
第三次归并后:{1,6,8,38,100,202,301},比较次数:4;
总的比较次数为:3+4+4=11,;
逆序数为14;
2)、将已有序的子序列合并,得到完全有序的序列。若将两个有序表合并成一个有序表,称为二路归并。
3)、非递归算法实现
假设序列共有n个元素。
①将序列每相邻两个数字进行归并操作(merge),形成floor(n/2)个序列,排序后每个序列包含两个元素
②将上述序列再次归并,形成floor(n/4)个序列,每个序列包含四个元素
③重复上面步骤,直到所有元素排序完毕
2、特点
1)、稳定性:稳定
2)、时间代价:O(n*logn)
3)、辅助存储空间:O(N)
4)、比较
①空间允许的情况下O(n)
②速度仅次于快速排序、n较大、有序时适用
排序:一般用于对总体无序,但是各子项相对有序的数列
求逆序对数:具体思路是,在归并的过程中计算每个小区间的逆序对数,进而计算出大区间的逆序对数
3、代码
#include <iostream>
#include <ctime>
#include <cstring>
using namespace std;
void Merge(int* data, int a, int b, int length, int n)
{
int right;
if(b+length-1 >= n-1)
right = n-b;
else
right = length;
int* temp = new int[length+right];
int i = 0, j = 0;
while(i<=length-1&&j<=right-1)
{
if(data[a+i] <= data[b+j])
{
temp[i+j] = data[a+i];
i++;
}
else
{
temp[i+j] = data[b+j];
j++;
}
}
if(j == right)
{
memcpy(data+a+i+j, data+a+i,(length-i)*sizeof(int));
}
memcpy(data+a, temp, (i+j)*sizeof(int) );
delete temp;
}
void MergeSort(int* data, int n)
{
int step = 1;
while(step < n)
{
for(int i = 0; i <= n-1-step; i += 2*step)
Merge(data, i, i+step, step, n);
step *= 2;
}
}
int main()
{
int n;
cin >> n;
int *data = new int[n];
if(!data)
exit(1);
int k = n;
while(k --)
{
cin >> data[n-k-1];
}
clock_t s = clock();
MergeSort(data, n);
clock_t e = clock();
k = n;
while(k --)
{
cout << data[n-k-1] << ' ';
}
cout << endl;
cout << "the algrothem used " << e-s << " miliseconds."<< endl;
delete data;
return 0;
}七、堆排序
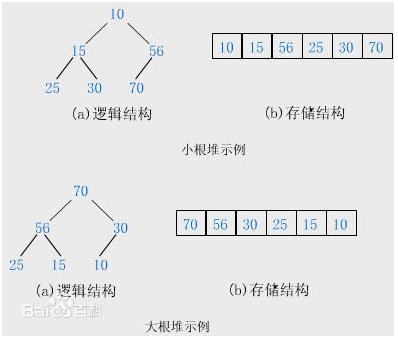
1、原理方法
BST、堆数据结构、利用数组快速定位、无序有序区
2、特点
1)、稳定性:不稳定
2)、时间代价:O(n*logn)
3)、辅助存储空间:O(1)
4)、比较
①常情况下速度要慢于快速排序(因为要重组堆)
②既能快速查找、又能快速移动元素。
n较大时、关键字元素可能出现本身是有序时适用
3、代码
#include<iostream>
#include <ctime>
#include <cstring>
using namespace std;
void HeapAdjust(int array[], int i, int nLength)
{
int nChild;
int nTemp;
for (nTemp = array[i]; 2 * i + 1 < nLength; i = nChild)
{
nChild = 2 * i + 1;
if ( nChild < nLength-1 && array[nChild + 1] > array[nChild])
++nChild;
if (nTemp < array[nChild])
{
array[i] = array[nChild];
array[nChild]= nTemp;
}
else
break;
}
}
// 堆排序算法
void HeapSort(int array[],int length)
{
int tmp;
for (int i = length / 2 - 1; i >= 0; --i)
HeapAdjust(array, i, length);
for (int i = length - 1; i > 0; --i)
{
tmp = array[i];
array[i] = array[0];
array[0] = tmp;
HeapAdjust(array, 0, i);
}
}
int main()
{
int n;
cin >> n;
int *data = new int[n];
if(!data)
exit(1);
int k = n;
while(k --)
{
cin >> data[n-k-1];
}
clock_t s = clock();
HeapSort(data, n);
clock_t e = clock();
k = n;
while(k --)
{
cout << data[n-k-1] << ' ';
}
cout << endl;
cout << "the algrothem used " << e-s << " miliseconds."<< endl;
delete data;
system("pause");
}
八、 基数排序(桶排序)(属于分配排序)
1、原理方法
基数排序(radix sort)属于分配式排序(distribution sort)、又称桶子法(bucket sort或bin sort)。通过键值的查询,将要排序的元素分配至某些“桶”中,以达到排序的作用。
1)、分配排序(hash)
①关键码确定记录在数组中的位置,但只能对0~n-1进行排序
②(扩展)允许关键码重复、数组元素可变长、每个元素成为链表的头节点
③(扩展)允许关键码范围大于n、关键码值(盒子数)比记录数大很多时效率很差(检查是否有元素)、同时存储的数组变大
④(扩展)桶式排序、每一个盒子与一组关键码相关、桶中(较少)记录用其它方法(收尾排序)排序
⑤堆排序
2)、LSD的基数排序
适用于位数小的数列
73, 22, 93, 43, 55, 14, 28, 65, 39, 81
①首先根据个位数的数值,在走访数值时将它们分配至编号0到9的桶子中。
0
1 81
2 22
3 73 93 43
4 14
5 55 65
6
7
8 28
9 39
②接下来将这些桶子中的数值重新串接起来,成为以下的数列。
81, 22, 73, 93, 43, 14, 55, 65, 28, 39
接着再进行一次分配,这次是根据十位数来分配:
0
1 14
2 22 28
3 39
4 43
5 55
6 65
7 73
8 81
9 93
③接下来将这些桶子中的数值重新串接起来,成为以下的数列:
14, 22, 28, 39, 43, 55, 65, 73, 81, 93
这时候整个数列已经排序完毕;如果排序的对象有三位数以上,则持续进行以上的动作直至最高位数为止。
3)、MSD
①位数多、由高位数为基底开始进行分配
②分配之后并不马上合并回一个数组中,而是在每个“桶子”中建立“子桶”,将每个桶子中的数值按照下一数位的值分配到“子桶”中。在进行完最低位数的分配后再合并回单一的数组中。
2、特点
1)、稳定性:稳定
2)、时间代价
①n个记录、关键码长度为d(趟数)、基数r(盒子数如10)、不同关键码值m(堆数<=n)
②链式基数排序的时间复杂度为O(d(n+r))
一趟分配时间复杂度为O(n)、一趟收集时间复杂度为O(radix)、共进行d趟分配和收集
③下面是一个近似值,可自己推导
O(nlog(r)m)、O(nlogn)(关键码全不同)
m<=n、d>=log(r)m
3)、辅助存储空间
2*r个指向队列的辅助空间、用于静态链表的n个指针
4)、比较
①空间允许情况下
②适用于:
关键字在一个有限范围内
有些情况下效率高于其它比较性排序法
记录数目比关键码长度大很多
调节r得到较好性能
3、代码
int MaxBit(int data[],int n)
{
int maxBit = 1;
int temp =10;
for(int i = 0;i < n; ++i)
{
while(data[i] >= temp)
{
temp *= 10;
++maxBit;
}
}
return maxBit;
}
//基数排序
void RadixSort(int data[],int n)
{
int maxBit = MaxBit(data,n);
int* tmpData = new int[n];
int* cnt = new int[10];
int radix = 1;
int i,j,binNum;
for(i = 1; i<= maxBit;++i)
{
for(j = 0;j < 10;++j)
cnt[j] = 0;
for(j = 0;j < n; ++j)
{
binNum = (data[j]/radix)%10;
cnt[binNum]++;
}
for(binNum=1;binNum< 10;++binNum)
cnt[binNum] = cnt[binNum-1] + cnt[binNum];
for(j = n-1;j >= 0;--j)
{
binNum= (data[j]/radix)%10;
tmpData[cnt[binNum]-1] = data[j];
cnt[binNum]--;
}
for(j = 0;j < n;++j)
data[j] = tmpData[j];
radix = radix*10;
}
delete [] tmp;
delete [] cnt;
}















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









