










 本文提出了一种基于BERT的passage re-ranking方法,通过计算每个候选文档与问题的相关概率来改进答案检索流程。该方法将问题和文档输入BERT模型,并利用[CLS]标记进行二分类任务,从而实现更精确的答案定位。
本文提出了一种基于BERT的passage re-ranking方法,通过计算每个候选文档与问题的相关概率来改进答案检索流程。该方法将问题和文档输入BERT模型,并利用[CLS]标记进行二分类任务,从而实现更精确的答案定位。
task
有一个给定的问题,要给出答案分三个阶段
1、通过一个标准的机制从语料库中见多大量可能与给定相关的文档
2、passage re-ranking:对这些文档打分并重排序
3、分数前几的(前10、或前15等)的文档将会是这个问题答案的来源,用答案生成模型产出答案
这篇论文主要是研究第二个阶段
方法
要做的工作即是:对于一个询问 q q q,一个候选文章 d i d_i di,给出一个分数 s i s_i si
- 询问为句子A,限制在64个token内
- 文章为句子B,有文章截取,其长度与分隔符、询问的和最大不超过512个token
使用BERT_LARGE来做一个二分类网络,取最顶层的[CLS]作为句子的表示:来计算每个文章和询问的相关的概率,最后通关对这个概率排序来进入第三阶段
loss:
L = − ∑ j ∈ J p o s log ( s j ) − ∑ j ∈ J n e g log ( 1 − s j ) L=-\sum_{j\in J_{pos}}\log (s_j)-\sum_{j\in J_{neg}}\log (1-s_j) L=−j∈Jpos∑log(sj)−j∈Jneg∑log(1−sj)
- J p o s J_{pos} Jpos :相关的文章
- J n e g J_{neg} Jneg :不相关的文章
实验
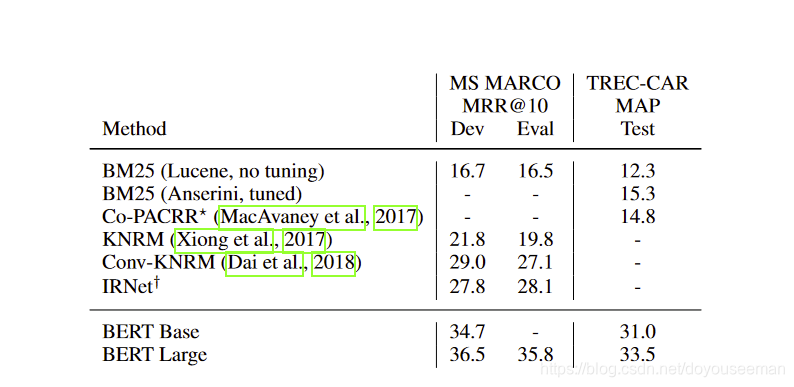 效果比之前的好很多
效果比之前的好很多


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









