







引言
上一篇文章中,我们简单介绍了各种导入模块的方法,并通过代码演示了模块被导入之前的模块查找的路径解析过程,但是,只是局限在了加载模块之前。
今天这篇文章,打算把整个模块导入的全流程进行梳理,从而更清晰地理解模块导入的过程中,Python解释器做了哪些动作,到底发生了什么。
本文的主要内容有:
1、Python中的两大模型
2、命名空间
3、模块导入的全过程及底层细节
Python中的两大模型
在前面的文章中,我们已经多次提到,程序 = 数据结构 + 算法,或者表述为:程序 = 数据的表达 + 数据的处理。而对应到Python中,就是两大模型:数据模型(Data Model)和执行模型(Execution Model)。
数据模型,我们前面已经反复提及,概括来说,就是“一切皆对象”。每个对象都有其id(粗略理解为地址)、内容(对象相关的属性、方法)、类型(type)。
由“一切皆对象”,进而得出函数、类、模块、包也都是对象,自然在Python中也都是一等公民。
执行模型,其实就是通过代码,对数据模型进行读与写,也就是对对象的读与写。要对对象进行读写,我们一般是通过变量名进行的,所以,执行模型的一个核心概念,就是“名称绑定”,也就是将每一个变量名与一个对象进行绑定。在Python中变量名是“标签”而非“盒子”的观点,在前面的文章中已经有所提及,不太理解的,可以翻一下之前的文章。
由于变量是贴在对象上的“标签”,变量名与对象的绑定关系,可以是“多对一”的关系。
执行模型中,一个代码块能够读写的对象,是能够访问到的名称绑定的对象。这些名称和对象的绑定被放到了一个称为“命名空间”的结构中,命名空间可以理解为是一个字典。
所以,执行模型,也可以这样表述为“代码块在命名空间上的执行,对命名空间中的名称所绑定的对象进行读写操作”。
执行模型中,代码块能够执行,名称绑定是前提,但是,能够执行,还需要能够进行名称解析,以及特殊情况下名称绑定的解绑操作。
其中,名称的解析,就涉及到了“作用域”的概念,之前已经介绍过LEGB的规则,这里就不展开了。
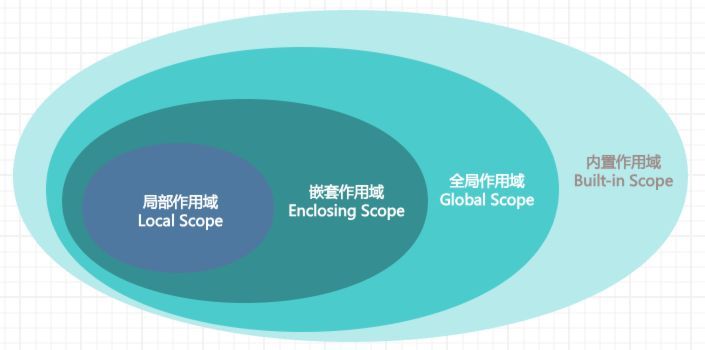
之所以介绍执行模型,主要是由于当导入模块时,会对命名空间产生影响。
命名空间
命名空间(namespace)是编程语言中一个很核心的概念,用于组织代码、避免命名冲突。在Python中,命名空间本质上是一个从名称(变量名)到对象的映射关系的绑定,也就是命名空间中记录了变量名、函数名、类名等与实际对象的关联关系。
在Python中,命名空间可以分为四类,分别是:局部命名空间(Local Namespace)、闭包命名空间(Enclosing Namespace)、全局命名空间(Global Namespace)和内置命名空间(Built-in Namespace)。
1、局部命名空间:包含函数和方法内定义的变量和参数,每次函数调用都会创建一个新的局部命名空间。
2、闭包命名空间:包含在嵌套函数中的外层函数中的局部命名空间。
3、全局命名空间:包含当前模块中定义的所有全局变量、函数、类等,当模块被导入时,Python解释器会创建一个全局命名空间。
4、内置命名空间:包含Python解释器启动时加载的内置函数、异常等。比如,print()、len()、int等都在内置命名空间中。
每种命名空间都有自己的生命周期:
1、局部命名空间:从函数调用开始到函数返回结束。
2、闭包命名空间:从外层函数被调用到内层函数执行结束。
3、全局命名空间:从模块被导入或者脚本开始执行到脚本结束。
4、内置命名空间:从Python解释器启动到解释器进程结束。
在Python中,有3个内置函数,可以查看命名空间中的内容:
1、globals():查看当前全局命名空间的字典
2、locals():查看当前局部命名空间的字典
3、dir():返回当前代码所在范围的所有名字列表
模块导入的全过程及底层细节
有了前面关于“执行模型”和“命名空间”的概念,可以帮助我们更好地理解Python中的模块导入。
首先来看下模块导入的全过程:
1、查找模块
当执行import 模块名等类似的操作时,Python解释器首先会在sys.modules字典中查找,如果已经存在,直接使用缓存的模块,避免重复加载。
如果sys.modules模块中不存在,则会检查是否是内置模块,这些模块是C语言编写的,并被编译到了Python解释器中。
如果不是内置模块,Python解释器会在sys.path列表中按顺序进行模块的查找。关于路径的查找顺序,上一篇文章中已经提及,可以自行查阅。
2、编译模块
如果是首次导入,找到的是一个.py文件,Python解释器会将其“编译”为字节码(.pyc)文件,以提高后续执行的加载速度。如果已经存在编译后的字节码文件且没有过期(可以理解为比较.py文件的修改时间与.pyc文件的生成时间),则会直接加载字节码文件。
3、执行模块代码
一旦模块的字节码被加载,Python解释器会创建一个新的模块对象,并执行模块的顶级代码(即未包裹在函数定义或者类定义中的代码)。在执行模块代码时,Python解释器首先会为该模块创建一个独立的全局命名空间,模块中的顶级代码是在该独立的全局命名空间中执行的。
4、更新命名空间
执行完模块的顶级代码后,模块对象会被添加到sys.modules字典中,以便将来可以复用,并且导入的模块名会绑定到当前作用域中的模块对象(根据导入方式的不同,除了模块名与模块对象的绑定之外,还可能涉及到模块中变量、函数等的绑定)
总结
为了更好地理解Python中模块导入的过程及细节,本文首先回顾了Python中的数据模型,然后引入了执行模型的概念。之后,简单介绍了Python中的命名空间,4种命名空间的含义及其生命周期。基于执行模型及命名空间的概念,对Python中的模块导入全过程做了一个系统性的梳理。
在下一篇文章中,将通过实际的代码执行,验证一下Python模块导入、加载的过程。
感谢您的拨冗阅读,如果对您学习Python有所帮助,欢迎点赞、关注。

















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











