






数据类型以及长度
C语言只提供了下列几种基本的数据类型:
| 类型 | 描述 |
|---|---|
| char | 字符型,占用一个字节,可以存放本地字符集中的一个字符 |
| int | 整形,整形的大小由系统决定,如Turto C 2.0为每一个整形分配 2 个字节;而Visual C++为每一个整形数据分配 4 个字节; |
| float | 单精度浮点型 |
| double | 双精度浮点型 |
注意,各种类型的存储大小与系统位数有关,但目前通用的以64位系统为主。
以下列出了32位系统与64位系统的存储大小的差别(windows 相同):
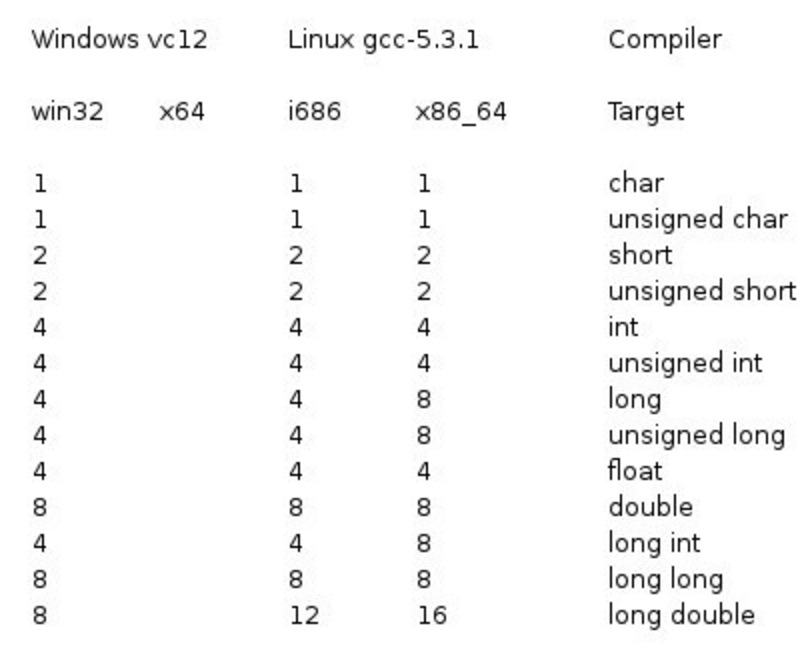
类型转换
当一个运算符的几个操作数类型不同时,就需要通过一些规则把它们转换为某种共同的类型。一般来说,自动转换是指把“比较窄的”操作数转换为“比较宽的”操作数,并且不丢失信息的转换。
例如,在计算表达式f+i时,将整型变量的值自动转换为浮点型(这里的变量E为浮点型)。不允许使用无意义的表达式,例如,不允许把float类型的表达式作为下标。针对可能导致信息丢失的表达式,编译器可能会给出警告信息,比如把较长的整型值赋给较短的整型变量,把浮点型值赋值给整型变量,等等,但这些表达式并不非法。
以下是一道经典的面试题
在C语言中,如下程序输出结果为
char c = 250;
unsigned char d;
char f;
d = c + 249;
f = c + 249;
printf("d = %d\n", d);
printf("d = %u\n", d);
printf("f = %d\n", f);
printf("f = %u\n", f);
对于如果你不熟悉正负数如何在计算机存储的朋友来说,这是一道非常好的训练题
在正式解释之前,我们在Linux环境下跑跑代码,来看看结果如何
PS D:\share> cd "d:\share\Code\; if ($?) { gcc test.c -o test } ; if ($?) { .\test }
d = 243
d = 243
f = -13
f = 4294967283
此时,你会说,我靠,用%d何%u输出字符d的结果怎么都是一样的?下面这个更奇怪了居然出现了负数,而且怎么还出现了4294967283这么大的数字,我掰手指也数不过来啊。
其实,即将有符号字符转换为整数类型时,会由由C编译器的实现字符拓展,符号扩展是指将一个数值类型转换为另一种更长的数值类型时,如果原始类型是有符号的,那么在转换时会保留符号位并进行填充,以保持数值大小不变。然而,在使用 %u 格式控制符打印 char 类型变量时,不会发生符号扩展,因为输出时会将其视为无符号整数进行处理。
那么我们再分析一下之前的代码,就会轻松很多了:
声明变量并赋值:
-
首先,我们看到了三个变量的声明和初始化:
char c = 250; unsigned char d; char f;在 C 语言中,char 类型默认被视为有符号字符类型,其范围为 -128 到 127。因此,当将 250 赋给 c 时,会发生溢出,导致 c 的值实际上是 -6
[250] = [1111 1010]原
但是由于第一位是符号位,显然这是一个负数,
[1111 1010]补 = [1000 0110]原 = [-6]
计算并赋值:
-
接下来,我们进行了计算并赋值操作:
d = c + 249; f = c + 249;这里,对于 d = c + 249,由于 c 的值已经变为了 -6,所以 -6 + 249 的结果是 243。因为 d 是无符号字符类型,所以它的值是 243。同理对于字符f也是如此,但是!此时,我们不应该过早的关心d或者f等于多少,我们更应该关心此时char是怎么存储数据的。char有8个位,所以次数char d 与char f存储的数据都应该是1111 0011
打印输出:
-
最后,我们使用 printf 函数进行输出:
printf("d = %d\n", d); printf("d = %u\n", d); printf("f = %d\n", f); printf("f = %u\n", f);对于无符号的字符d,用有符号的整数格式输出,不会发生符号拓展,即1111 0011,输出243
对于无符号的字符d,用无符号的整数格式输出,不会发生符号拓展,即1111 0011,输出243
对于有符号的字符f,用有符号的整数格式输出,会发生符号拓展,即11111111 11111111 11111111 11110011,输出-13
对于有符号的字符f,用无符号的整数格式输出,会发生符号拓展,即11111111 11111111 11111111 11110011,输出4294967283
将字符类型转换为整型时,我们需要注意一点。C语言没有指定char类型的变量是无符号变量(signed)还是带符号变量 (unsigned)。当把一个char类型的值转换为int类型的值时,其结果有没有可能为负整数?对于不同的机器,其结果也不同,这反映了不同机器结构之间的区别。在某些机器中,如果char类型值的最左一位为1,则转换为负整数(进行“符号扩展”)。而在另一些机器中,把char类型值转换为int类型时,在char类型值的左边添加0,这样导致的转换结果值总是正值。
C语言的定义保证了机器的标准打印字符集中的字符不会是负值,因此,在表达式中这些字符总是正值。但是,存储在字符变量中的位模式在某些机器中可能是负的,而在另一些机器上可能是正的。为了保证程序的可移植性,如果要在char类型的变量中存储非字符数据最好指定signed或者unsigned 限定符。
总结来说就是,因此,在实际情况中,字符拓展可能是补全0,也可能是补全1,这取决于所使用的具体编译器和平台。在char类型的变量中存储非字符数据最好指定signed或者unsigned 限定符。
在 C 语言中,经常会涉及到不同类型之间的算术运算。当进行这些运算时,如果操作数具有不同的类型,就会发生隐式的算术类型转换。一般来说,在二元运算符中,会将“较低”的类型提升为“较高”的类型,然后进行运算,最终结果的类型也是“较高”的类型。但是,如果没有 unsigned 类型的操作数,就只需要遵循一些非正式的规则。
隐式算术类型转换规则
C 语言中的隐式算术类型转换规则对于理解数据类型之间的相互作用非常重要。以下是一些常见的转换规则:
-
整型提升:
-
如果参与运算的两个操作数中,一个是有符号整型,另一个是无符号整型,那么有符号整型会被提升为无符号整型。如果有符号整型和无符号整型具有相同的 rank(如 int 和 unsigned int),那么有符号整型会被提升为无符号整型
#include <stdio.h> int main() { int int1 = -1; unsigned int uint_1 = 1; if(int1>uint_1) printf("int1>uint_1\n"); else printf("int1<uint_1\n"); return 0; }int1>uint_1
-
-
默认的整型提升:
- 当参与运算的两个操作数具有不同的整型类型时,会将较低的类型提升为较高的类型,然后再进行运算。例如,char 类型会被提升为 int 类型。
-
无符号类型的特殊规则:
- 如果没有 unsigned 类型的操作数参与运算,其他类型会被提升为带符号类型。
#include <stdio.h> #include <stdio.h> int main() { int int1 = -1; unsigned int uint_1 = 1; printf("int1 + uint_1 = %d",int1+uint_1); }int1 + uint_1 = 0
结论
C 语言中的隐式算术类型转换规则帮助我们理解在不同类型之间进行运算时会发生的类型转换。通过遵循这些规则,我们可以确保运算的正确性,并且避免意外的类型错误。对于程序员来说,了解这些规则有助于写出更加健壮和可靠的代码。















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









