







什么是MapReduce
简单认识MapReduce
1、MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
2、MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式 计算。
3、这两个函数的形参是key、value对,表示函数的输入信息。
MapReduce中的名词解释
split:
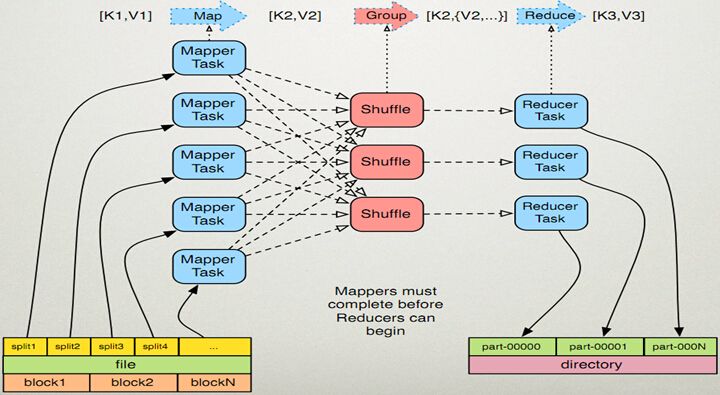
分片是指MapReduce框架将数据源根据一定的规则将源数据分成若干个小数据的过程;其中,一个小数据集,也被称为一个分片。
Map:
其一、是指MapReduce框架中的Map过程,即将一个分片根据用户定义的Map逻辑处理后,经由MapReduce框架处理,形成输出结果,供后续Reduce过程使用;
其二,是指用户定义Java程序实现Mapper类的map接口的用户自定义逻辑,此时通常被称为mapper。
Reduce:
其一,是指MapReduce框架中的Reduce过程,即将Map的结果作为输入,根据用户定义的Reduce逻辑,将结果处理并汇总,输出最后的结果;
其二,是指用户定义Java程序实现Reducer类的reduce接口的用户自定义逻辑,此时通常被称为reducer。
Combiner:
Combiner是一个可由用户自定的过程,类似于Map和Reduce,MapReduce框架会在Map和Reduce过程中间调用Combiner逻辑(会在下面章节中仔细讲解),通常Combine和reduce的用户代码是一样的(也可被称为本地的reduce过程),但并不是所有用MapReduce框架实现的算法都适合增加Combiner过程(比如求平均值)。
Partition:
在MapReduce框架中一个split对应一个map,一个partiton对应一个reduce(无partition指定时,由用户配置项指定,默认为1个)。 reduce的个数决定了输出文件的个数。比如,在需求中,数据是从对每个省汇总而成,要求计算结果按照省来存放,则需要根据源数据中的表明省的字段分区,用户自定义partition类,进行分区。
MapReduce结构流程图
MapReduce简单示例(WordCount)
package com.itcast.hadoop.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
/**
* map方法:继承Mapper类,重写map方法,四个参数(输入的key,value和输出的key,value)
*/
public static class WordMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接受数据
String v1 = value.toString();
// 切分数据
String[] words = v1.split(" ");
for (String v : words) {
context.write(new Text(v), new LongWritable(1));
}
}
}
/**
* redece方法:继承Reduce类,重写reduce方法,四个参数(输入的key,value和输出的key,value)
*/
public static class WordReduce extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text k2,Iterable<LongWritable> v2s,Context context) throws IOException, InterruptedException {
Text k3 = k2;
long count = 0;
for (LongWritable i : v2s) {
count += i.get();
}
context.write(k3, new LongWritable(count));
}
}
public static void main(String[] args) throws Exception {
// 创建job对象
Job job = Job.getInstance(new Configuration());
// 注意:main方法所在的类
job.setJarByClass(WordCount.class);
// 设置map相关属性
job.setMapperClass(WordMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("/words.text"));
//设置reduce相关属性
job.setReducerClass(WordReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileOutputFormat.setOutputPath(job, new Path("/wcount1"));
//执行任务
job.waitForCompletion(true);
}
}















 2249
2249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









