







(一)推荐系统简介
1. 推荐系统应用前提:(1)信息过载;(2)用户没有明确需求;
2. 推荐系统的组成:前台的展示页面,后台的日志系统,推荐算法;
(二)推荐系统的评测
1. 实验方法
(1) 离线实验
优点:1)不需要有对实际系统的控制权;
2)不需要用户参与体验;
3)速度快,可以测试大量算法;
缺点:1)无法计算商业上关心的指标;
2)离线实验的指标和商业指标存在差距;
(2) 用户调查
优点:1)获得很多体现用户主观感受的指标;
2)实验风险很低,出现错误后很容易弥补;
缺点:1)招募测试用户代价较大;
2)设计双盲实验困难,在测试环境下收集的测试指标可能在真实环境下无法重现;
(3) 在线实验(AB测试)
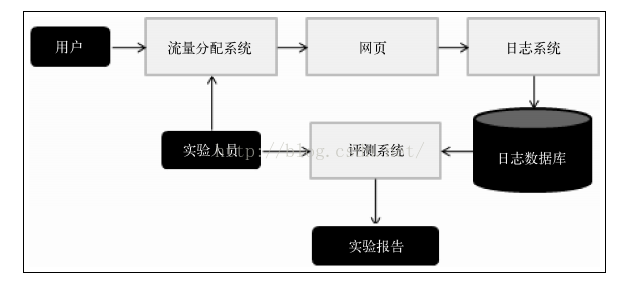
(4) 一般一个新的推荐算法最终上线都需要经历以上3个实验:
1) 通过离线实验证明它在很多离线指标上优于现有的算法;
2) 通过用户调查确定它的用户满意度不低于现有的算法;
3) 通过在线的AB测试确定它在我们关心的指标上优于现有的算法;
2. 评测指标
(1) 用户满意度:点击率,用户停留时间,转化率等;
(2) 预测准确度:
1) 评分预测:RMSE(均方根误差),MAE(平均绝对误差);
2) Top N问题:recall(召回率),precision(准确率);
(3) 覆盖率:推荐出来的物品占总物品集合的比例;
(4) 多样性:推荐列表中物品两两之间的差异性;
(5) 新颖性,惊喜度,实时性,商业目标等;

(三)常见的推荐算法
1.基于协同过滤的推荐算法
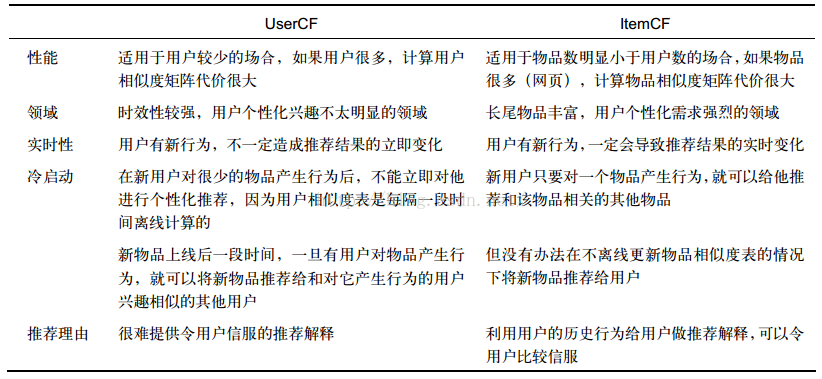
(1)基于用户的协同过滤(UserCF)
a.算法步骤:1)找到和目标用户兴趣相似的用户集合;
2)找到这个集合中用户喜欢的且目标用户没有听说过的商品推荐给目标用户;
b.用户相似度计算:u,v表示用户,N表示有正反馈的商品集合;
1) Jaccard相似度:
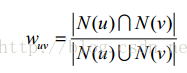
2) 余弦相似度:
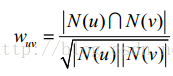
(2)基于商品的协同过滤(ItemCF)
a.算法步骤:1)计算商品之间的相似度;
2)根据商品的相似度和用户的历史行为给用户生成推荐列表;
b.商品相似度计算:i,j表示商品,N表示对商品有正反馈的用户集合;
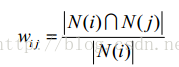
PS:对比:
UserCF给用户推荐那些和他有共同兴趣爱好的用户喜欢的商品,而ItemCF给用户推荐那些和他之前喜欢的商品类似的商品;
(3)基于slope-one的推荐算法
a.原理:
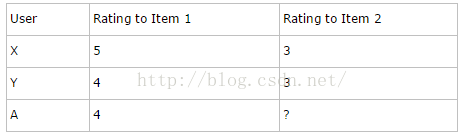
已知用户X,Y都对item1跟item2打过分,用户A对item1打过分,那么对item2打分可能为:4-((5-3)+(4-3))/2=2.5;
b.算法步骤:
1)计算物品之间评分差的平均值,记为物品间的评分偏差;
2)根据物品间的评分偏差和用户的历史评分,给用户生成预测评分高的推荐物品列表;
2.基于属性的推荐算法
(1)基于用户标签的推荐算法
a.算法步骤:
1)统计每个用户最常用的标签;
2)对于每个标签,统计被打过这个标签次数最多的物品;
3)找到用户常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户;
(2)基于商品内容的推荐算法
a.利用商品的内容属性计算商品之间的相似度,是物推物的算法;
b.优点:
1) 不依赖于用户行为,只要获取到item的内容信息就可以计算语义级别上的相似性;
2)不存在item冷启动问题;
c.缺点:
1)要求内容容易抽取成有意义的特征,特征内容具有良好的结构性;
2)不能很好的处理一词多义和一义多词带来的语义问题;
3.基于矩阵分解的推荐算法
(1)原理:根据已有的评分矩阵(非常稀疏),分解为低维的用户特征矩阵(评分者对各个因子的喜好程度)以及商品特征矩阵(商品包含各个因子的程度),最后再反过来分析数据(用户特征矩阵与商品特征矩阵相乘得到新的评分矩阵)得出预测结果;
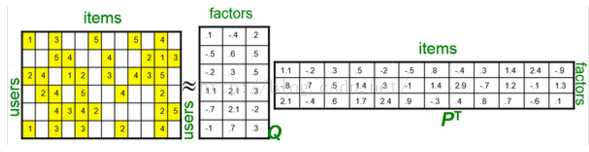
(2)SVD:
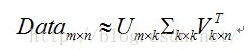
1)其中:Data表示m个用户,n个商品的评分矩阵;U表示m个用户的特征矩阵;V表示n个商品的特征矩阵(k个因子);
2)上述svd分解中,Data经常是稀疏且有空缺值的,简单的做法是将空缺值补上随机值,那么就可以svd分解了,但是推荐效果一般,因此一般将该问题转化为优化问题;
3)目标函数:
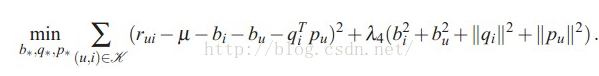
其中r表示用户对商品的真实打分,u表示所有打分的平均,bi表示用户打分时的偏差,bi表示商品被打分时的偏差,qi表示商品的特征向量,pu表示用户的特征向量;
(3)SVD++:在svd基础上,加入用户的历史打分记录信息等;
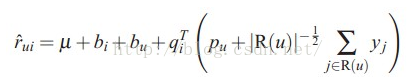
其中R表示用户之前打分过的电影;
4.基于热门内容的推荐(流行度算法)
(1)对用户推荐那些流行度高的物品,或者说是新热物品;
(2)算法步骤:
1)确定物品的流行周期;
2)计算物品在流行周期内的流行度,流行度高的物品作为被推荐物品;
(3)流行度算法很好的解决冷启动问题,但推荐的物品有限,不能很好的命中用户的兴趣点;其推荐列表通常会作为候补列表推荐给用户;在微博、新闻等产品推荐时是常用的方法;
5.混合推荐
(1)加权的混合: 用线性公式将几种不同的推荐按照一定权重组合起来,具体权重的值需要在测试数据集上反复实验,从而达到最好的推荐效果;
(2)切换的混合:对于不同的情况(数据量,系统运行状况,用户和物品的数目等),推荐策略可能有很大的不同,那么切换的混合方式,就是允许在不同的情况下,选择最为合适的推荐机制计算推荐;
(3)分区的混合:采用多种推荐机制,并将不同的推荐结果分不同的区显示给用户;其实,Amazon,当当网等很多电子商务网站都是采用这样的方式,用户可以得到很全面的推荐,也更容易找到他们想要的东西;
(4)分层的混合:采用多种推荐机制,并将一个推荐机制的结果作为另一个的输入,从而综合各个推荐机制的优缺点,得到更加准确的推荐;
(四)常见的排序模型
1.基于规则的排序模型
(1)相关度排序模型:根据查询和文档之间的相似度来对文档进行排序;
(2)重要性排序模型:不考虑查询,而仅仅根据网页(亦即文档)之间的图结构来判断文档的权威程度;
2.基于机器学习的排序模型(learningto rank,LTR)
(1)PointWise:将训练集里每一个文档当做一个训练实例,将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果;
(2)PairWise:将同一个査询的搜索结果里任意两个文档对作为一个训练实例,将每个文档对的文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档对进行判别,判别结果即是文档对的先后排序;(gbrank,svmrank,lambdamart)
(3)ListWise:将每一个查询对应的所有搜索结果列表整体作为一个训练实例,根据K个训练实例训练得到最优评分函数F;对于一个新的用户査询,函数F 对每一个文档打分,之后按照得分顺序由高到低排序,就是对应的搜索结果;
(五)冷启动解决
1. 引导用户把自己的一些属性表达出来 ;
2. 利用现有的开放数据平台 ;
3. 曲线救国 :做一款让用户更愿意或者更容易表现个人偏好的产品, 先让用户玩一段时间. 再引导用户进入其他产品;
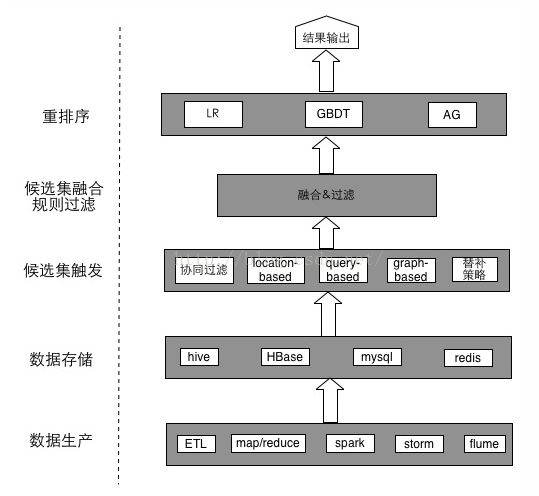
(六)美团推荐系统


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









