










AC自动机算法
1、简要概述
什么是AC自动机算法?
AC自动机算法是一种多模式字符串匹配算法,什么是多模式?从单模式说起,举个kmp算法的例子,单模式就是利用kmp算法验证某个敏感词在一个字符串内是否存在;多模式是说验证多个敏感词在一个字符串内是否存在。如果使用kmp来做的话,依次遍历多个敏感词,每个敏感词使用kmp验证,当敏感词数量很多的时候效率很低,这时候就用到AC自动机算法了。
为什么AC自动机算法效率高?
结论:其能在约为O(n) 的时间复杂度内完成对多个敏感词的查找,而且其时间复杂度只跟搜索串的长度(n)有关,跟敏感词的数量并无关联,原理和kmp算法的next数组类似,只不过这里用的是fail指针。
2、算法概述
主要分为三步:
- 创建字典树
- 构建fail指针
- 查找匹配
构建字典树
-
根据输入的敏感词,构建字典树。在构建字典树的过程中,如果从根节点到某个节点的路径完全匹配上某个敏感词,则将这个敏感词的长度加入节点的存储信息中(用于后续搜索匹配时能还原出匹配到的敏感词)。
-
节点信息
class AcNode { //孩子节点用HashMap存储,能够在O(1)的时间内查找到,效率高 Map<Character,AcNode> children=new HashMap<>(); AcNode failNode; //使用set集合存储字符长度,防止敏感字符重复导致集合内数据重复 Set<Integer> wordLengthList = new HashSet<>(); }- 构建字典树代码
public static void insert(AcNode root,String s){ AcNode temp=root; char[] chars=s.toCharArray(); for (int i = 0; i < s.length(); i++) { if (!temp.children.containsKey(chars[i])){ //如果不包含这个字符就创建孩子节点 temp.children.put(chars[i],new AcNode()); } temp=temp.children.get(chars[i]);//temp指向孩子节点 } temp.wordLengthList.add(s.length());//一个字符串遍历完了后,将其长度保存到最后一个孩子节点信息中 }
创建fail指针–基于树的层次遍历
-
由于fail指针的加入,在节点匹配失败时,不用重新从根节点出发进行查找,可以直接跳到失败指针指向的节点进行下一步查找,从而减少搜索路径,大大提高搜索效率
-
abcabcd abcd
-
假设有模式串
he、she、hers、his、shy,则其字典树构建结果如下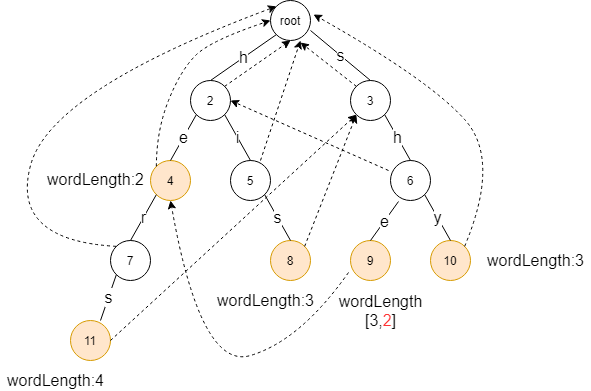
对于fail指针,其定义是在发生匹配失败时进行的 跳转路径节点。假设节点
9的失败指针指向的节点为 4,从根节点到 4节点的路径组成的字符串he,从根节点到 9 节点的路径组成的字符串 she ,he是she 的最长后缀(如果字符串只有一个字符,则最长后缀为空)。此处要理解为什么通过fail指针就能找到最长的后缀?
- fail指针就代表:如果 9 的fail指针是4,则代表 word[9 的最长后缀是word[4]
关于节点的失败指针的构建,其算法如下:
- 根节点的的失败指针为null
- 对于非根节点
current,获取父亲节点的失败指针指向的节点temp- 如果
temp为空,则将current节点的失败指针指向根节点。(图中4号节点) - 如果
temp节点和current节点的父节点有相同的转移路径(即能够匹配某个相同的字符),则将current的失败指针指向temp对应的孩子节点上。(图中的9号节点的失败指针指向4号节点) - 如果
temp节点没有与current节点父节点具有相同的转移路径,则继续获取temp节点的失败指针指向的节点,将其赋值给temp,重复上述匹配过程。(比如10号节点)
- 如果
- 在构建节点的失败指针时,如果失败指针指向的节点存在匹配模式串的记录信息(记录了模式串的长度),则将这个信息加入到当前节点中。这个做法是为了方便后续根据搜索串查找相应的匹配串。(例如图中的9号节点)
- 构建fail代码:
public static void buildFailPath(AcNode root,int n,String[] s){
//第一层的fail指针指向root,并且让第一层的节点入队,方便BFS
Queue<AcNode> queue=new LinkedList<>();
Map<Character,AcNode> childrens=root.children;
Iterator iterator=childrens.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry<Character, AcNode> next = (Map.Entry<Character, AcNode>) iterator.next();
queue.offer(next.getValue());
next.getValue().failNode=root;
}
//构建剩余层数节点的fail指针,利用层次遍历
while(!queue.isEmpty()){
AcNode x=queue.poll();
childrens=x.children; //取出当前节点的所有孩子
iterator=childrens.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry<Character, AcNode> next = (Map.Entry<Character, AcNode>) iterator.next();
AcNode y=next.getValue(); //得到当前某个孩子节点
AcNode fafail=x.failNode; //得到孩子节点的父节点的fail节点
//如果 fafail节点没有与 当前节点父节点具有相同的转移路径,则继续获取 fafail 节点的失败指针指向的节点,将其赋值给 fafail
while(fafail!=null&&(!fafail.children.containsKey(next.getKey()))){
fafail=fafail.failNode;
}
//回溯到了root节点,只有root节点的fail才为null
if (fafail==null){
y.failNode=root;
}
else {
//fafail节点有与当前节点父节点具有相同的转移路径,则把当前孩子节点的fail指向fafail节点的孩子节点
y.failNode=fafail.children.get(next.getKey());
}
//如果当前节点的fail节点有保存字符串的长度信息,则把信息存储合并到当前节点
if (y.failNode.wordLengthList!=null){
y.wordLengthList.addAll(y.failNode.wordLengthList);
}
queue.offer(y);//最后别忘了把当前孩子节点入队
}
}
}
查找
搜索过程,先按字典树的查找过程进行匹配,如果在某个节点匹配失败,则运用失败指针跳转到下一个节点继续进行匹配。当搜索到某个节点时,如果该节点存储了模式串的信息(模式串的长度),对进行处理(输出),否则不额外处理。由于搜索过程中是遍历搜索串的每个字符,能获取到下标信息,根据当前下标和存储的长度就能截取出模式串,所以在预处理的过程中不是存储的模式串,而是存储长度。这样也能节省空间。
public static void query(AcNode root,int n,String s){
AcNode temp=root;
char[] c=s.toCharArray();
for (int i = 0; i < s.length(); i++) {
//如果这个字符在当前节点的孩子里面没有或者当前节点的fail指针不为空,就有可能通过fail指针找到这个字符
//所以就一直向上更换temp节点
while(temp.children.get(c[i])==null&&temp.failNode!=null){
temp=temp.failNode;
}
//如果因为当前节点的孩子节点有这个字符,则将temp替换为下面的孩子节点
if (temp.children.get(c[i])!=null){
temp=temp.children.get(c[i]);
}
//如果temp的failnode为空,代表temp为root节点,没有在树中找到符合的敏感字,故跳出循环,检索下个字符
else{
continue;
}
//如果检索到当前节点的长度信息存在,则代表搜索到了敏感词,打印输出即可
if (temp.wordLengthList.size()!=0){
handleMatchWords(temp,s,i);
}
}
}
//利用节点存储的字符长度信息,打印输出敏感词及其在搜索串内的坐标
public static void handleMatchWords(AcNode node, String word, int currentPos)
{
for (Integer wordLen : node.wordLengthList)
{
int startIndex = currentPos - wordLen + 1;
String matchWord = word.substring(startIndex, currentPos + 1);
System.out.println("匹配到的敏感词为:"+matchWord+",其在搜索串中下标为:"+startIndex+","+currentPos);
}
}
3、测试
测试(因为敏感词不易放出,故用xx和***代替)
敏感词:约4075条数据
测试
搜索串:
你是xx吗?两会期间代理模式是常用的java设计模式,他的特征是代理类与委托类有**同样的接口**,代理类主要负责为委托类预处理消息、过滤消息、把消息转发给委托类,以及事后处理消息等。代理类与委托类之间通常会存在关联关系,一个代理类的对象与一个委托类的对象关联,代理类的对象本身并不真正实现服务,而是通过调用委托类的对象的相关方法,来提供特定的服务。简单的说就是,我们在访问实际对象时,是通过代理对象来访问的,代理模式就是在访问实际对象时引入一定程度的间接性,因为这种间接性,可以附加多种xx在没学ac自动机之前,觉得ac自动机是个很神奇,很高深,很难的算法,学完之后发现,ac自动机确实很神奇,很高深,但是却并不难。我说ac自动机很神奇,在于这个算法中失配指针的妙处(好比kmp算法中的next数组),说它高深,是因为这个不是一般的算法,而是建立在两个普通算法的基础之上,而这两个算法就是kmp与字典树。所以,如果在看这篇博客之前,你还不会字典树或者kmp算法,那么请先学习字典树或者kmp算法之后再来看这篇博客。好了,闲话扯完了,下面进入正题。在学习一个新东西之前,一定要知道这个东西是什么,有什么用,我们学它的目的是什么,如果对这些东西没有一个清楚的把握,我不认为你能学好这个新知识。那么首先我们来说一下ac自动机是什么。下面是我从百度上找的。Aho-Corasick automaton,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法。从上面我们可以知道,ac自动机其实就是一种多模匹配算法,那么你可能会问什么叫做多模匹配算法。下面是我对多模匹配的理解,与多模与之对于的是单模,单模就是给你一个单词,然后给你一个字符串,问你这个单词是否在这个字符串中出现过(匹配),这个问题可以用kmp算法在比较高效的效率上完成这个任务。那么现在我们换个问题,给你很多个单词,然后给你一段字符串,问你有多少个单词在这个字符串中出现过,当然我们暴力做,用每一个单词对字符串做kmp,这样虽然理论上可行,但是时间复杂度非常之高,当单词的个数比较多并且字符串很长的情况下不能有效的解决这个问题,所以这时候就要用到我们的ac自动机算法了。对于上面的文字,我已经回答了什么是多模匹配和我们为什么要学习ac自动机那就是ac自动机的作用是什么等一系列问题。下面是ac自动机的具体实现步骤以及模板代码。把所有的单词建立一个字典树。在建立字典树之前,我们先定义每个字典树上节点的结构体变量***(2000)
输出:
建树时间为:0.05秒左右
匹配到的敏感词为:xx,其在搜索串中下标为:2,3
匹配到的敏感词为:xx,其在搜索串中下标为:244,245
匹配到的敏感词为:***,其在搜索串中下标为:1037,1039
查找时间为:0.002秒左右
4、匹配效率
-
Trie 树构建的复杂度是
O(m*len),其中m为模式串(敏感词)数量,len为模式串(敏感词)平均长度。 -
构建失败指针时,最耗时的是 while 循环中逐层往上查找失败指针,每次循环至少往上一层,而树的高度不超过
len,因此时间复杂度为O(K*len),K 为 Trie 树中的节点个数。 -
以上两步操作只需执行一次完成构建,不影响与主串匹配的效率,在匹配时,最耗时的同样是 while 循环中往下一个失败指针的代码,因此时间复杂度为
O(len),若主串长度为n,那么总匹配时间复杂度为O(n*len)
构建失败指针时*,最耗时的是 while 循环中逐层往上查找失败指针,每次循环至少往上一层,而树的高度不超过len,因此时间复杂度为O(K*len),K 为 Trie 树中的节点个数。 -
以上两步操作只需执行一次完成构建,不影响与主串匹配的效率,在匹配时,最耗时的同样是 while 循环中往下一个失败指针的代码,因此时间复杂度为
O(len),若主串长度为n,那么总匹配时间复杂度为O(n*len) -
实际在匹配敏感词时,敏感词的平均长度不会很长,所以字典树大约是一个扁长状的树,因此,AC 自动机的匹配效率很接近
O(n)。















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









