







spark+eclipse环境搭建同时使用kmeans聚类
- spark本地环境搭建
网址:http://spark.apache.org/downloads.html
网址:http://hadoop.apache.org/releases.html
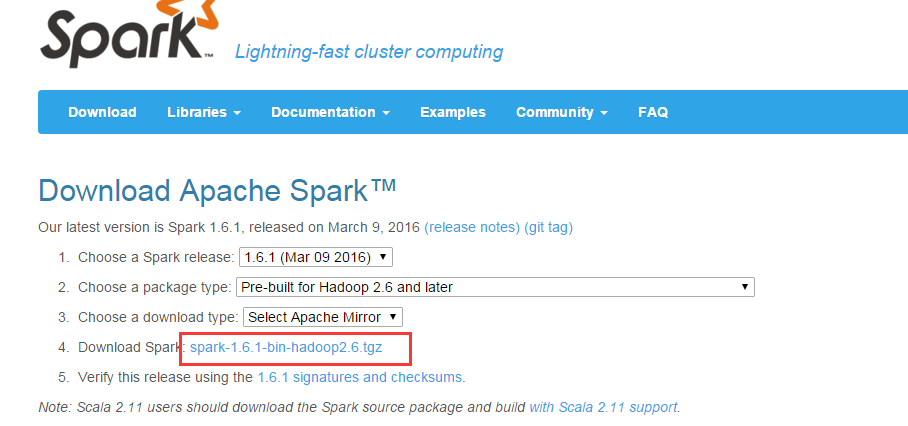
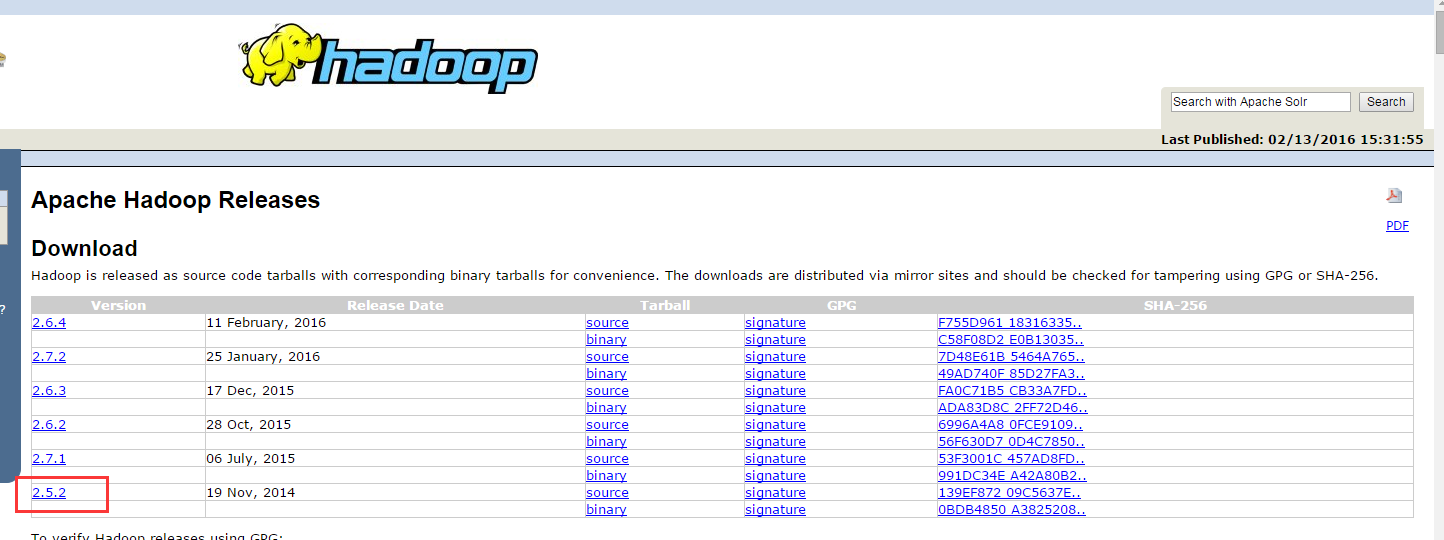
配置SPARK_HOME和HADOOP_HOME,同时环境变量path中加入相应的bin路径
启动:
cmd命令dos下使用spark-shell 启动spark单机环境
eclipse添加scala插件
安装适当版本的eclipse:http://scala-ide.org/download/sdk.html
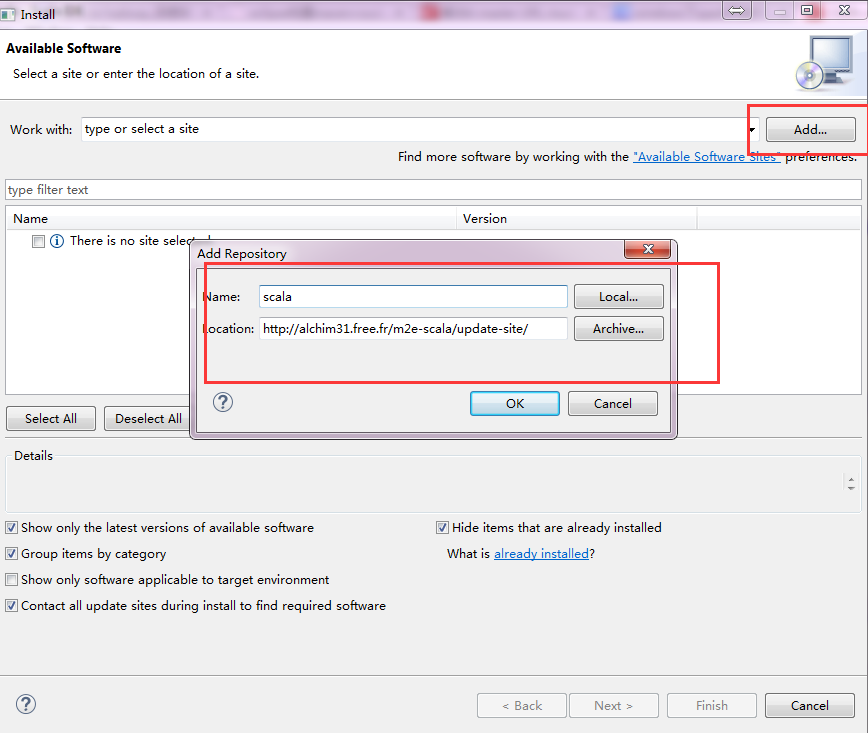
m2e-scala的地址:http://alchim31.free.fr/m2e-scala/update-site/,也可以下载好了再用。
使用scala模板
如果没有合适的scala模板,可以安装
安装方法是添加原型或模板目录,选择【Window】-【Preferences…】- 【Maven】-【archetypes】,选择【Add Remote Catalog…】按钮,在打开的窗口中输入:Catalog File:http://repo1.maven.org/maven2/archetype-catalog.xml
单击【Verify…】检验该文件是否可行,可以添加很多模板。
单击【OK】退出窗口。- *重启后创建新的maven工程
pom文件内容
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jd</groupId>
<artifactId>plist-sku-cluster</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>${project.artifactId}</name>
<description>My wonderfull scala app</description>
<inceptionYear>2010</inceptionYear>
<licenses>
<license>
<name>My License</name>
<url>http://....</url>
<distribution>repo</distribution>
</license>
</licenses>
<properties>
<maven.compiler.source>1.5</maven.compiler.source>
<maven.compiler.target>1.5</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<!-- change to "2.11" once Scala 2.11.0 final is out -->
<scalaBinaryVersion>2.11</scalaBinaryVersion>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-xml_${scalaBinaryVersion}</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-parser-combinators_${scalaBinaryVersion}</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-swing_${scalaBinaryVersion}</artifactId>
<version>1.0.1</version>
</dependency>
<!-- spark support begin -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<!-- spark support end -->
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.6</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<!-- If you have classpath issue like NoDefClassError,... -->
<!-- useManifestOnlyJar>false</useManifestOnlyJar -->
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
</plugins>
</build>
</project>
kmeans算法代码(转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice4/)
import org.apache.spark.{ SparkContext, SparkConf }
import org.apache.spark.mllib.clustering.{ KMeans, KMeansModel }
import org.apache.spark.mllib.linalg.Vectors
object KMeansClustering {
def main(args: Array[String]) {
if (args.length < 5) {
println("Usage:KMeansClustering trainingDataFilePath testDataFilePath numClusters numIterations runTimes")
sys.exit(1)
}
val conf = new SparkConf().setAppName("Spark MLlib Exercise:K-Means Clustering")
val sc = new SparkContext(conf)
/**
* Channel Region Fresh Milk Grocery Frozen Detergents_Paper Delicassen
* 2 3 12669 9656 7561 214 2674 1338
* 2 3 7057 9810 9568 1762 3293 1776
* 2 3 6353 8808 7684 2405 3516 7844
*/
//训练数据
val rawTrainingData = sc.textFile(args(0))
val parsedTrainingData =
rawTrainingData.filter(!isColumnNameLine(_)).map(line => {
Vectors.dense(line.split("\t").map(_.trim).filter(!"".equals(_)).map(_.toDouble))
}).cache()
// Cluster the data into two classes using KMeans
val numClusters = args(2).toInt
val numIterations = args(3).toInt
val runTimes = args(4).toInt
var clusterIndex: Int = 0
val clusters: KMeansModel = KMeans.train(parsedTrainingData, numClusters, numIterations, runTimes)
println("Cluster Number:" + clusters.clusterCenters.length)
println("Cluster Centers Information Overview:")
clusters.clusterCenters.foreach(
x => {
println("Center Point of Cluster " + clusterIndex + ":")
println(x)
clusterIndex += 1
})
//begin to check which cluster each test data belongs to based on the clustering result
val rawTestData = sc.textFile(args(1))
val parsedTestData = rawTestData.map(line =>
{
Vectors.dense(line.split("\t").map(_.trim).filter(!"".equals(_)).map(_.toDouble))
})
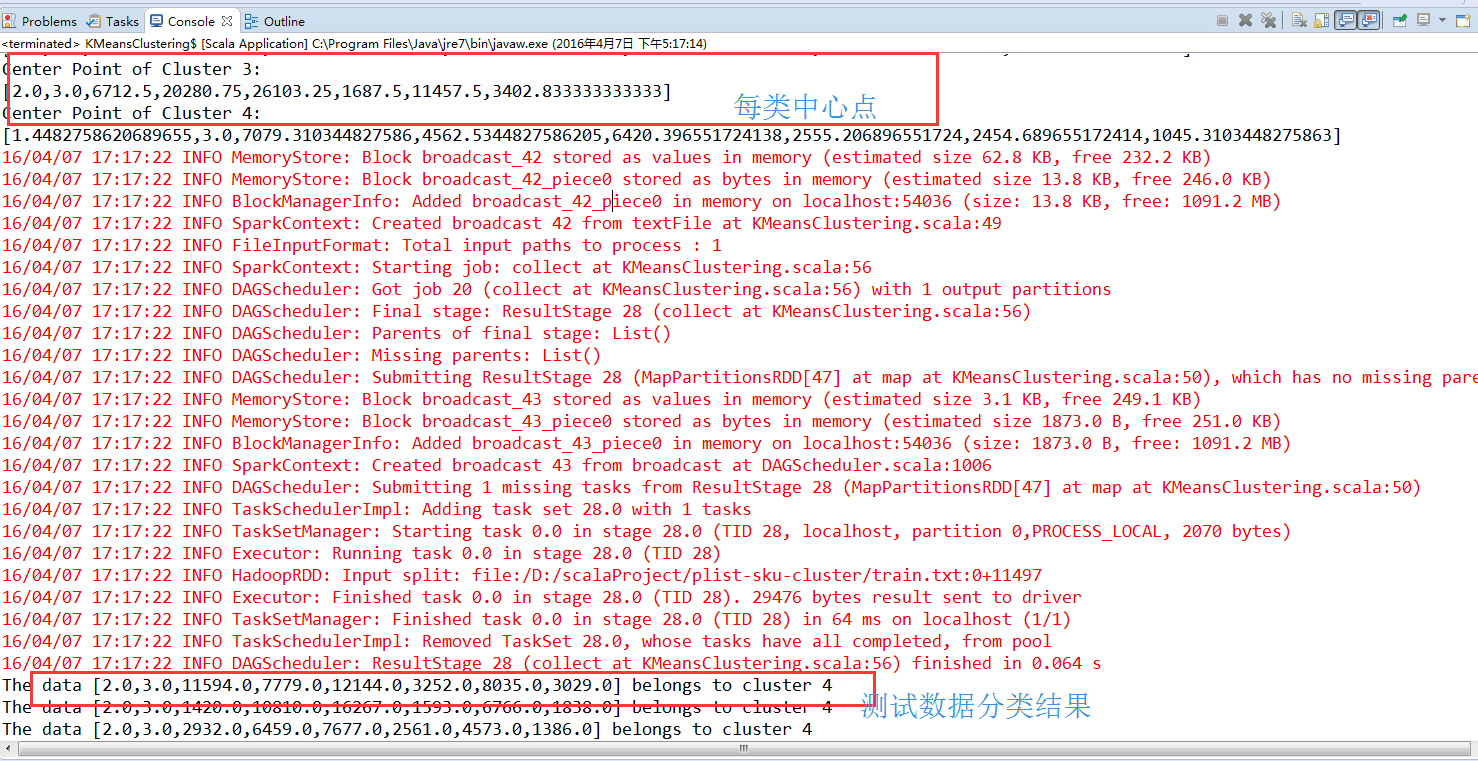
parsedTestData.collect().foreach(testDataLine => {
val predictedClusterIndex: Int = clusters.predict(testDataLine)
println("The data " + testDataLine.toString + " belongs to cluster " +
predictedClusterIndex)
})
println("Spark MLlib K-means clustering test finished.")
}
private def isColumnNameLine(line: String): Boolean = {
if (line != null && line.contains("Channel"))
true
else
false
}
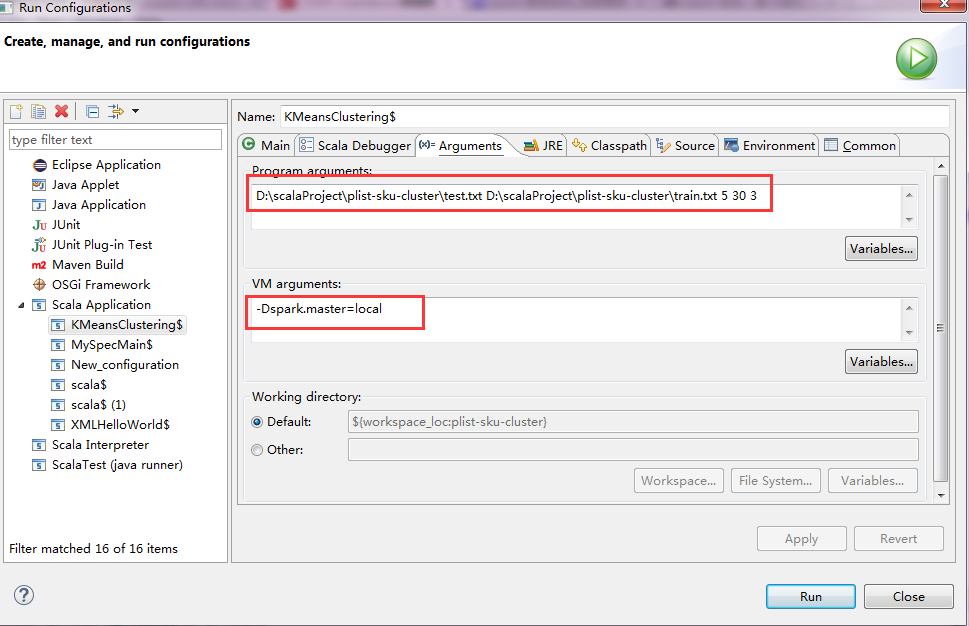
}- 运行
如果报master url必须配置的错误,注意添加-Dspark.master=local的参数
结果















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









