







Spark
区别和共性
三者的区别
-
RDD
RDD一般和spark mlib同时使用
RDD不支持sparksql操作 -
DataFrame
与RDD和Dataset不同,DataFrame每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值,
DataFrame与DataSet一般不与 spark mlib 同时使用
DataFrame与DataSet均支持 SparkSQL 的操作,比如select,groupby之类,还能注册临时表/视窗,进行 sql 语句操作
DataFrame与DataSet支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然(后面专门讲解) -
DataSet
Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同。 DataFrame其实就是DataSet的一个特例
DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段。而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息
三者的共性
2.5.1 三者的共性
-
RDD、DataFrame、Dataset全都是 Spark 平台下的分布式弹性数据集,为处理超大型数据提供便利
-
三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算。
-
三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
-
三者都有partition的概念
-
三者有许多共同的函数,如map, filter,排序等
-
在对 DataFrame和Dataset进行操作许多操作都需要这个包进行支持 import spark.implicits._
-
DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型
RDD
RDD是Spark的核心概念,它是一个只读的、可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,可在多次计算间重用。
-
创建RDD
// 从本地加载RDD // 执行 sc.textFile()方法以后,Spark 从本地文件 word.txt 中加载数据到内存,在内存中生成一个 RDD对象lines。 // 假设word.txt文件中只包含3行文本内容,则生成的RDD (即lines)中就会包含3个String类型的元素。 val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt") val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt", 2) //设置两个分区 // 从分布式文件系统中加载数据 val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt") val lines = sc.textFile("/user/hadoop/word.txt") //因为HDFS中已经创建了与当前Linux系统登录用户hadoop对应的用户目录"/usr/hadoop" val lines = sc.textFile("word.txt") // 通过并行集合创建RDD,每个元素一行 val array = Array(1,2,3,4,5) val rdd = sc.parallelize(array) val rdd = sc.parallelize(array,2) //设置两个分区 -
RDD转换
| 操作 | 含义 |
|---|---|
| filter(func) | 筛选出满足函数func的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传递到函数func, |
| flatMap(func) | 与map()相似,但每个输入元素都可映射到0个或多个输出 |
| groupByKey() | 应用于(K,V)键值对的数据集时,返回一个新的(K,Iterable)形式的数据集 |
| reduceByKey(func) | 应用于(K,V)键值对的数据集时,返回一个新的(K,V)形式的数据集,其中每个值是将每个Key传递到函数func中进行聚合的结果 |
// 对于RDD而言,每次转换操作都会产生不同的RDD,RDD的转换过程是惰性求值的,也就是说,
// 整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算。
// filter,筛选。
// 筛选出带有"Spark"的所有行
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
val linesWithSpark=lines.filter(line => line.contains("Spark"))
// map,处理每一行元素,并返回一个新的数据集
// 将每行元素的值加10后返回新的数据集
data=Array(1,2,3,4,5)
val rdd1= sc.parallelize(data)
val rdd2=rdd1.map(x => x + 10)
// 将每行数据都去除空格后用一个Array包含所有元素,即返回一个每行都是数组的RDD
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
val words=lines.map(line => line.split(" "))
// flatMap,相当于先map,然后把map生成的Array再拍扁,使得新的RDD每个元素都是String
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
val words=lines.flatMap(line => line.split(" "))
// groupByKey,操作(K,V)键值对的数据集,返回一个新的(K,Iterable)形式的数据集
// reduceByKey,相当于先执行groupByKey,然后再对生成的Iterable执行func操作
-
RDD行动
操作 含义 count() 返回数据集中的元素个数 collect() 以数组的形式返回数据集中的所有元素 first() 返回数据集中的第一个元素 take(n) 以数据的形式返回数据集中的前n个元素 reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 foreach(func) 将数据集中的每个元素传递到函数func中运行 // 行动操作是真正触发计算的地方。Spark程序只有执行到行动操作时,才会执行真正的计算, // 从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。 val rdd=sc.parallelize(Array(1,2,3,4,5)) rdd.count() //返回5 rdd.collect() //返回Array(1,2,3,4,5) rdd.first() //返回1 rdd.take(3) //返回Array(1,2,3) rdd.reduce((a,b) => a + b) //返回15 rdd.foreach(elem => println(elem)) //输出1,2,3,4,5 -
持久化
// 将RDD持久化 rdd.cache() rdd.persist(MEMORY_ONLY) //和上一句等价 rdd.persist(MEMORY_AND_DISK) //如果内存不够,会存储到文件 // 取消RDD持久化 rdd.unpersist() -
分区
// 设置分区 val rdd = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt", 2) val rdd = sc.parallelize(array, 2) // 查看分区 data.partitions.size // 对add重新分区 val rdd1 = rdd.repartition(1) -
关于键值对的一些方法
rdd.keys //返回所有键 rdd.value //返回所有值 rdd.sortByKey //将元素按照键排序后返回 rdd.sortBy(func) //根据自定义的函数排序, rdd.reduceByKey(_+_).sortBy(_._2,false).collect 即表示根据值来排序,"_._2"表示每个键值对RDD的值 rdd.mapValue(func) //对每个键值对的value都应用func方法 rdd1.join(rdd2) //对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集 val pairRDD1 = sc.parallelize(Array(("spark",1),("spark",2),("hadoop",3),("hadoop",5))) val pairRDD2 = sc.parallelize(Array(("spark","fast"))) pairRDD1.join(pairRDD2) //结果为 (spark,(1,fast)) (spark,(2,fast)) combineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine) /*中的各个参数的含义如下: (1)createCombiner:在第一次遇到key时创建组合器函数,将RDD数据集中的V类型值转换C类型值(V => C); (2)mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C; (3)mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值; (4)partitioner:使用已有的或自定义的分区函数,默认是HashPartitioner; (5)mapSideCombine:是否在map端进行Combine操作,默认为true。 */ -
文件操作
// 普通文件系统的读写 val textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt") textFile.saveAsTextFile("file:///usr/local/spark/mycode/wordcount/writeback") // HDFS的读写 val textFile = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt") val textFile = sc.textFile("/user/hadoop/word.txt") val textFile = sc.textFile("word.txt") textFile.saveAsTextFile("writeback") // JSON文件的读写 // Scala 中有一个自带的JSON 库——scala.util.parsing.json.JSON,可以实现对 JSON 数据的解析, // JSON.parseFull(jsonString:String)函数以一个 JSON 字符串作为输入并进行解析,如果解析成功, // 则返回一个 Some(map: Map[String, Any]),如果解析失败,则返回None。
Spark SQL(DataFrame)
DataFrame 是一种以 RDD 为基础的分布式数据集,提供了详细的结构信息,就相当于关系数据库的一张表。
-
创建和保存DataFrame
// 从文件中读取DataFrame spark.read.json("file:///usr/files/spark_test/people.json") spark.read.format("json").load("file:///usr/files/spark_test/people.json") spark.read.parquet("file:///usr/files/spark_test/people.parquet") spark.read.format("parquet").load("file:///usr/files/spark_test/people.parquet") spark.read.csv("file:///usr/files/spark_test/people.csv") spark.read.format("csv").load("file:///usr/files/spark_test/people.csv") // 自己创建 case class Person(name: String, age: Int) val df = Seq(Person("lili", 20), Person("zs", 21)).toDF // 将DataFrame保存到文件 df.write.json("file:///usr/files/spark_test/people.json") df.write.format("json").save("file:///usr/files/spark_test/people.json") df.write.parquet("file:///usr/files/spark_test/people.parquet") df.write.format ("parquet").save("file:///usr/files/spark_test/people.parquet") df.write.csv("file:///usr/files/spark_test/people.csv") df.write.format ("csv").save("file:///usr/files/spark_test/people.csv") -
DataFrame的常用操作
// 输出模式信息 df.printSchema() // 输出name和age两列的内容 df.select(df("name"), df("age")).show() df.select(df("name").as("username"), df("age")).show // 筛选出年龄大于20的记录 df.filter(df("age") > 20).show() // 根据age字段分组并统计个数 df.groupBy("age").count().show() // 对记录进行排序 df.sort(df("age").desc).show() df.sort(df("age").desc, df("name").asc).show() -
将RDD转换成DataFrame
// 利用反射机制推断RDD模式 // people.txt // Michael, 29 // Andy, 30 // Justin, 19 //导包 import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder import org.apache.spark.sql.Encoder import spark.implicits._ case class Person(name: String, age: Long) val peopleDF = spark.sparkContext.textFile("file:///usr/files/spark_test/people.txt").map(_.split(",")).map(attributes => Person(attributes(0), attributes(1).trim.toInt)).toDF() peopleDF.createOrReplaceTempView("people") //把peopleDF转换成临时表才能够使用,临时表名称为people val personsRDD = spark.sql("select name,age from people whereage > 20") //从临时表people中查询所有age字段的值大于20的记录。 personsRDD.map(t => "Name: " + t(0) + "," + "Age: " + t(1)).show() /* 在上面的代码中,首先通过import语句导入所需的包,然后,定义了一个名称为Person的case class, 也就是说,在利用反射机制推断RDD模式时,需要先定义一个case class,因为,只有case class才能 被 Spark 隐式地转换为 DataFrame。spark.sparkContext.textFile()执行以后,系统会把 people.txt文 件加载到内存中生成一个 RDD,每个 RDD 元素都是 String 类型,3个元素分别是"Michael,29""Andy,30" 和"Justin,19"。然后,对这个RDD调用map(_.split(","))方法得到一个新的RDD,这个RDD中的3个元素分别 是Array("Michael","29")、Array("Andy", "30")和Array("Justin", "19")。接下来,继续对RDD执行 map(attributes => Person(attributes(0), attributes(1).trim.toInt))操作,这时得到新的RDD,每 个元素都是一个Person对象,3个元素分别是Person("Michael",29)、Person ("Andy", 30)和Person ("Justin", 19)。 然后,在这个RDD上执行toDF()操作,把RDD转换成DataFrame。从toDF()操作执行后系统返回的信息可以看出,新生成的名称 为peopleDF的DataFrame,每条记录的模式(schema)信息是[name: string, age: bigint]。 */// 使用编程方式定义RDD模式 /* • 第一步:制作“表头”; • 第二步:制作“表中的记录”; • 第三步:把“表头”和“表中的记录”拼装在一起。 */ import org.apache.spark.sql.types._ import org.apache.spark.sql.Row val fields = Array(StructField("name",StringType,true), StructField("age", IntegerType, true)) val schema = StructType(fields) val peopleRDD = spark.sparkContext.textFile("file:///usr/files/spark_test/people.txt") val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim.toInt)) val peopleDF = spark.createDataFrame(rowRDD, schema) peopleDF.createOrReplaceTempView("people") val results = spark.sql("SELECT name,age FROM people") results.map(attributes => "name: " + attributes(0) + ","+"age:" + attributes(1)).show() -
连接Mysql
参数名称 参数的值 含义 url jdbc:mysql://localhost:3306/spark 数据库的连接地址 driver com.mysql.jdbc.Driver 数据库的JDBC驱动程序 dbtable student 所要访问的表 user root 用户名 password hadoop 用户密码 // 读取Mysql中的数据 val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/spark").option("driver","com.mysql.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "hadoop").load() jdbcDF.show() // 向Mysql数据库写入数据 import java.util.Properties import org.apache.spark.sql.types._ import org.apache.spark.sql.Row //下面设置两条数据,表示两个学生的信息 val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M26","4 Guanhua M 27")).map(_.split(" ")) //下面设置模式信息 val schema = StructType(List(StructField("id", IntegerType,true),StructField("name", StringType, true),StructField("gender", StringType,true),StructField("age", IntegerType, true))) //下面创建Row对象,每个Row对象都是rowRDD中的一行 val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim,p(3).toInt)) //建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来 val studentDF = spark.createDataFrame(rowRDD, schema) //下面创建一个prop变量用来保存JDBC连接参数 val prop = new Properties() prop.put("user","root") //表示用户名是root prop.put("password","hadoop") //表示密码是hadoop prop.put("driver","com.mysql.jdbc.Driver") //表示驱动程序是com.mysql.jdbc.Driver //下面连接数据库,采用append模式,表示追加记录到数据库spark的student表中 studentDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark","spark.student",prop) -
连接Hive
// 从hive中读取数据 import org.apache.spark.sql.Row import org.apache.spark.sql.SparkSession import spark.implicits._ import spark.sql case class Record(key: Int, value: String) val warehouseLocation = "spark-warehouse" val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", warehouseLocation).enableHiveSupport().getOrCreate() // 向Hive中写入数据 import java.util.Properties import org.apache.spark.sql.types._ import org.apache.spark.sql.Row //下面设置两条数据表示两个学生信息 val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26","4 Guanhua M27")).map(_.split(" ")) //下面设置模式信息 val schema = StructType(List(StructField("id", IntegerType,true),StructField ("name", StringType, true),StructField("gender", StringType,true),StructField("age", IntegerType, true))) //下面创建Row对象,每个Row对象都是rowRDD中的一行 val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt)) //建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来 val studentDF = spark.createDataFrame(rowRDD, schema) //查看studentDF studentDF.show() // 注册临时表 //下面注册临时表 studentDF.registerTempTable("tempTable") //下面执行向Hive中插入记录的操作 sql("insert into sparktest.student select * from tempTable")
Spark Streaming
Spark Streaming是构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。Spark Streaming 可结合批处理和交互式查询,因此,可以适用于一些需要对历史数据和实时数据进行结合分析的应用场景。Spark Streaming 可整合多种输入数据源,如Kafka、Flume、HDFS,甚至是普通的TCP套接字。经处理后的数据可存储至文件系统、数据库,或显示在仪表盘里。
数据源
-
文件流
// 在spark-shell中创建文件流 import org.apache.spark.streaming._ val ssc = new StreamingContext(sc, Seconds(20)) val lines = ssc.textFileStream("file:///usr/files/spark_test") val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) wordCounts.print() ssc.start() ssc.awaitTermination() // 独立应用程序创建文件流 import org.apache.spark._ import org.apache.spark.streaming._ object WordCountStreaming { def main(args: Array[String]) { //设置为本地运行模式,两个线程,一个监听,另一个处理数据 val sparkConf = newSparkConf().setAppName("WordCountStreaming").setMaster("local[2]") // 时间间隔为2秒 val ssc = new StreamingContext(sparkConf, Seconds(2)) //这里采用本地文件,当然也可以采用HDFS文件 val lines = ssc.textFileStream("file:///usr/local/spark/mycode/streaming/logfile") val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) wordCounts.print() ssc.start() ssc.awaitTermination() } } -
Kafka数据源
//生产者 import java.util.HashMap import org.apache.spark.SparkConfimport import org.apache.spark.streaming._ import org.apache.spark.streaming.kafka._ import org.apache.kafka.clients.producer.{ KafkaProducer , ProducerConfig , ProducerRecord } object KafkaWordProducer { def main(args: Array[String]) { if (args.length < 4) { System.err.println("Usage: KafkaWordProducer<metadataBrokerList> <topic> " + "<messagesPerSec> <wordsPerMessage>" ) System.exit(1) } val Array(brokers, topic, messagesPerSec, wordsPerMessage) = args val props = new HashMap[String, Object]() props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers) props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer" ) props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer" ) val producer = new KafkaProducer[String, String](props) while (true) { (1 to messagesPerSec.toInt).foreach { messageNum => val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString) .mkString(" ") print(str) println() val message = new ProducerRecord[String, String](topic, null, str) producer.send(message) } Thread.sleep(1000) } } } // 消费者 import org.apache.spark._import import org.apache.spark.SparkConf import org.apache.spark.streaming._ import org.apache.spark.streaming.kafka._ import org.apache.spark.streaming.StreamingContext._ import org.apache.spark.streaming.kafka.KafkaUtils object KafkaWordCount { def main(args: Array[String]) { StreamingExamples.setStreamingLogLevels() val sc = newSparkConf().setAppName("KafkaWordCount").setMaster("local[2]") val ssc = new StreamingContext(sc, Seconds(10)) //设置检查点,如果存放在HDFS上面,则写成类似ssc.checkpoint("/user/hadoop/checkpoint")这种形式,但是,要启动Hadoopval ssc.checkpoint("file:///usr/local/spark/mycode/kafka/checkpoint") //Zookeeper服务器地址 zkQuorum = "localhost:2181" //Topic 所在的 group,可以设置为自己想要的名称,比如不用1,而是val group = "test-consumer-group" val group = "1" //topics的名称 val topics = "wordsender" //每个topic的分区数 val numThreads = 1 val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val lineMap = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap) val lines = lineMap.map(_._2) val words = lines.flatMap(_.split(" ")) val pair = words.map(x => (x, 1)) //这行代码的含义在下一节的窗口转换操作中会有介绍 val wordCounts = pair.reduceByKeyAndWindow(_ + _, _ - _, Minutes(2), Seconds(10), 2) wordCounts.print ssc.start ssc.awaitTermination } } // Log的日志等级 import org.apache.spark.internal.Logging import org.apache.log4j.{ Level , Logger } object StreamingExamples extends Logging { def setStreamingLogLevels() { val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements if (!log4jInitialized) { logInfo("Setting log level to [WARN] for streaming example." + " To override add a custom log4j.properties to the classpath." ) Logger.getRootLogger.setLevel(Level.WARN) } } }
转换操作
无状态转换操作
| 操作 | 含义 |
|---|---|
| map(func) | 对源Dstream的每个元素,采用func函数进行转换,得到一个新的Dstream |
| flatMap(func) | 与map类似,但是每个输入项可以被映射为零个或多个输出项 |
| filter(func) | 返回一个新的DStream,仅包含源DStream中满足函数func的项 |
| repartition(numPartitions) | 通过创建更多或者更少的分区改变DStream的并行程度 |
| reduce(func) | 利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDD的新DStream |
| count() | 统计源DStream中每个RDD的元素数量 |
| union(otherStream) | 返回一个新的DStream,包含源DStream和其他DStream的元素 |
| countByValue() | 应用于元素类型为K的DStream上,返回一个(K, V)键值对类型的新DStream, 每个键的值是在原DStream的每个RDD中的出现次数 |
| reduceByKey(func, [numTasks]) | 当在一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream, 每一个key的值均由给定的reduce函数(func)聚集起来 |
| join(otherStream, [numTasks]) | 当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K,(V,W))键值对的新DStream |
| cogroup(otherStream, [numTasks]) | 当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K,Seq[V],Seq[W])的元组 |
| transform(func) | 通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream,支持在新的DStream中做任何RDD操作 |
有状态装换操作
| 操作 | 含义 |
|---|---|
| windows(windowLength, slideInterval) | 基于源DStream产生的窗口化的批数据,计算得到一个新的DStream |
| countByWindow(windowLength, slideInterval) | 返回流中的一个滑动窗口数 |
| reduceByWindow(func, windowLength, slideInterval) | 返回一个单元素流。利用函数func对滑动窗口内的元素进行聚集,得到一个单元素流。函数func必须满足结合律,从而可以支持并行计算 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 应用到一个(K, V)键值对组成的DStream上时,会返回一个由(K, V)键值对组成的新的DStream。每一个Key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 更高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向recude函数”(以InvFunc参数传入) |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个Key的值都是它们在滑动窗口中出现的频率。 |
redeceByKeyAndWindow()中各个参数的取值
| 参数 | 值 | 含义 |
|---|---|---|
| func | _+_ | 等价于匿名函数(a,b) => a + b |
| invFunc | _-_ | 等价于匿名函数(a, b) => a - b |
| windowLength | Minutes(2) | 滑动窗口大小为2分钟 |
| slideInterval | Seconds(10) | 每隔10秒滑动一次 |
| numTasks | 2 | 启动的任务数量为2 |
例子
-
WordCount
val lines = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt") val wordCount = lines.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) wordCount.collect() wordCount.foreach(println)
SPARK笔记2
重要概念
-
架构
- Standalone模式下才有Master和Worker的叫法。
- Master:类似
YARN中的ResourceManager。作用:①监控Worker,接收对Worker的注册;②接收Client提交的Application,调度等待的Application并向Worker提交。 - Worker:类似
YARN中的NodeManager,掌管着所在节点的资源信息。作用:①通过RegisterWorker注册到Master;②发送心跳信息;③根据Master发送的Application配置进程环境,启动ExecutorBackend(执行Task所需的临时进程)。 - Executor:
SparkContext对象一旦连接到集群管理器,就可以获取到集群中每个节点上的Executor。Executor是一个进程(进程名:ExecutorBackend,运行在Work节点上),用来执行计算和为应用程序存储数据,然后Spark会发送应用程序代码(比如Jar包)到每个Ececutor,最后SparkContext对象发送任务到执行器开始执行程序。 - Driver Program:运行应用程序的main()函数并创建SparkContext的线程。每个Spark应用程序都包括一个驱动程序,驱动程序负责把并行操作发布到集群中。Driver会将用户程序划分为不同的执行阶段,每个执行阶段由一组完全相同的Task组成,这些Task分别作用于待处理数据的不同分区。在阶段划分完成和Task创建后,Driver会向Executor发送Task。
-
重要类:
SparkContext:负责连接到集群管理器。
-
RDD(弹性分布式数据集)
- RDD类中的特点
- 分区列表,即 一个RDD中有多个分区,每个分区中有多条数据,内部有方法
getPartitions: Array[Partition],默认等于核心数 - 切片
- 依赖列表,每个RDD都会依赖于其他RDD,内部有方法
getDependencies: Seq[Dependency[_]],窄依赖(NarrowDependency)分为OneToOneDependency和RangeDependency,宽依赖,没有对应的类,就只有ShuffleDependency。并且宽依赖一定会有shuffle阶段。 - RDD是一个泛型类
- 分区列表,即 一个RDD中有多个分区,每个分区中有多条数据,内部有方法
- RDD类中的特点
-
弹性:
- 存储的弹性:内存和磁盘的自动切换
- 容错的弹性:数据丢失可以自动恢复
- 计算的弹性:计算出错重试机制,即出错时可能会切换Executor
- 分片的弹性:可根据需要重新分片
- 只读
- RDD是只读的
- RDD包括两类算子
- transformation:将RDD进行转化,构建RDD的血缘关系
- action:触发RDD的计算,得到结果或者保存文件系统,比如
count、collect、savaAsTextFile
- 依赖:RDDs通过操作算子开始进行转换,转换之后得到新的RDD包含从其他RDDs衍生所必须的信息,RDDs之间维护者这种血缘关系
- 隐式转换:RDD的伴生类中有一些隐式转换,
-
转换算子
-
序列
-
单值
map和mapPartitions的区别:map是对每个分区内的每个元素都执行,mapPartitions是对每个分区都执行一次flatMap:一进多出,即flatMap中的方法返回的应该是一个可遍历的集合glom:将分区中的所有元素合并成一个Array
-
多值
zip:将两个RDD中索引相同的值合并为一个二元组
-
-
键值对
-
单值
partitionBy:重分区reduceByKey:聚合算子,在shuffle之前聚合(即预聚合),并且分区内和分区间聚合逻辑相同groupByKey:分组算子,foldByKey:聚合算子,可以有0值,在分区内会先进行聚合,并且分区内和分区间聚合逻辑相同aggregateByKey:聚合算子,三个参数,可以有0值,分区内调用func1,分区间调用func2combineByKey:聚合算子,比aggregateByKey更加灵活sortByKey:对key进行排序mapValues:对value进行map操作
-
多值
join和leftOuterJoin和rightOuterJoin:
-
-
-
行动算子
- collect
- count
- take
- takeOrdered
- countByKey
- reduce:聚合,无0值,分区内和分区间相同
- fold:聚合,有0值,分区内和分区间相同
- aggregate:聚合,有0值,分区内和分区间不同
- foreach:这个遍历是在executor上完成的,
-
概念:
- Application:一个Driver Program一个Application。基于Spark 构建的用户程序。 由集群上的驱动程序和执行程序组成。
- Job:一个Application中,每个Job包含多个Stage,每个action会产生一个Job。由多个Task组成的并行计算,这些任务响应 Spark action而产生;你会在驱动程序的日志中看到这个术语。
- Stage:每个宽依赖会产生一个新stage,也和分区器有关系(如果分区器相同,不产生新的Stage)。每个Job被划分为更小的task集,称为stage,彼此依赖(类似于MapReduce中的map和reduce阶段);您将在驱动程序日志中看到这个术语。
- Task:一个Stage包含多个Task,Task是一个线程,是执行代码的最小单位,Task和分区数相等。将发送给一个Executor的工作单元去执行。
-
RDD缓存级别,聚合算子默认会进行缓存
-
划分DAG:
- 首先,根据依赖关系的不同将DAG划分为不同的阶段(Stage)。
- 对于窄依赖,由于Partition依赖关系的确定性,Partition的转换处理就可以在同一个线程里完成,窄依赖被Spark划分到同一个执行阶段;
- 对于宽依赖,由于Shuffle的存在,只能在parent RDD(s)Shuffle处理完成后,才能开始接下来的计算,因此宽依赖就是Spark划分Stage的依据,即Spark根据宽依赖将DAG划分为不同的Stage。
- 在一个Stage内部,每个Partition都会被分配一个计算任务(Task),这些Task是可以并行执行的。
- Stage之间根据依赖关系变成了一个大粒度的DAG,这个DAG的执行顺序也是从前向后的。也就是说,Stage只有在它没有parent Stage或者parent Stage都已经执行完成后,才可以执行。
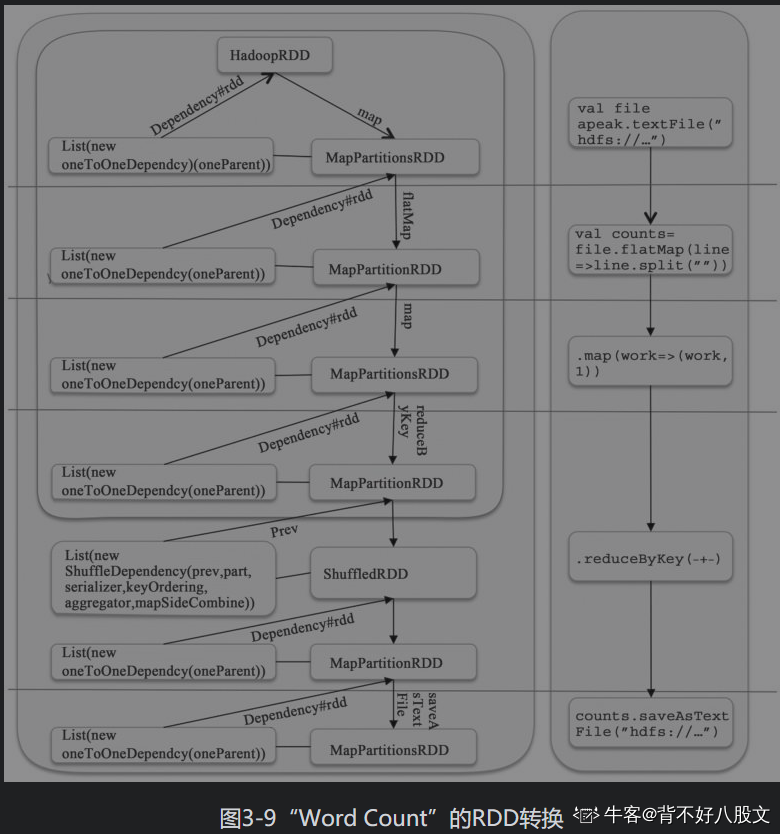
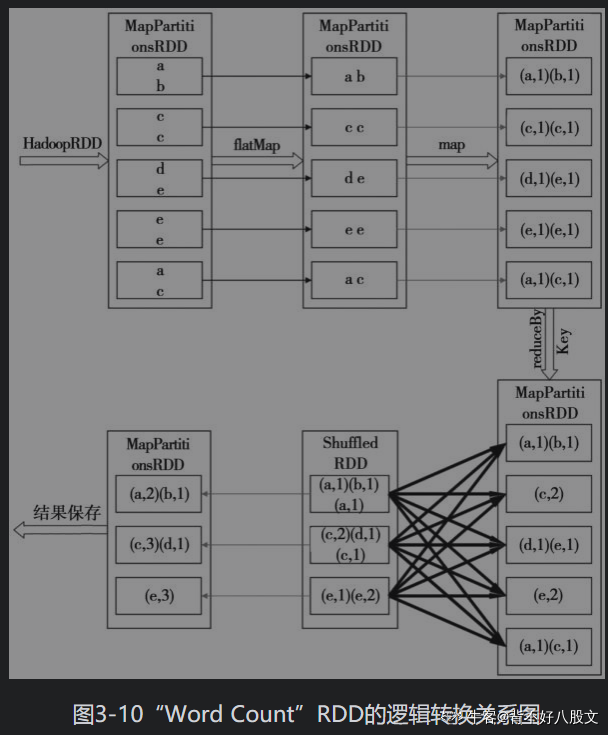
- 举例
- 首先,根据依赖关系的不同将DAG划分为不同的阶段(Stage)。
-
分区算法:
-
代码
private object ParallelCollectionRDD { /** * Slice a collection into numSlices sub-collections. One extra thing we do here is to treat Range * collections specially, encoding the slices as other Ranges to minimize memory cost. This makes * it efficient to run Spark over RDDs representing large sets of numbers. And if the collection * is an inclusive Range, we use inclusive range for the last slice. */ def slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] = { if (numSlices < 1) { throw new IllegalArgumentException("Positive number of slices required") } def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = { (0 until numSlices).iterator.map { i => val start = ((i * length) / numSlices).toInt val end = (((i + 1) * length) / numSlices).toInt (start, end) } } seq match { case r: Range => positions(r.length, numSlices).zipWithIndex.map { case ((start, end), index) => // If the range is inclusive, use inclusive range for the last slice if (r.isInclusive && index == numSlices - 1) { new Range.Inclusive(r.start + start * r.step, r.end, r.step) } else { new Range(r.start + start * r.step, r.start + end * r.step, r.step) } }.toSeq.asInstanceOf[Seq[Seq[T]]] case nr: NumericRange[_] => // For ranges of Long, Double, BigInteger, etc val slices = new ArrayBuffer[Seq[T]](numSlices) var r = nr for ((start, end) <- positions(nr.length, numSlices)) { val sliceSize = end - start slices += r.take(sliceSize).asInstanceOf[Seq[T]] r = r.drop(sliceSize) } slices // 如果是一个Array,会将Array分割为多个Seq case _ => val array = seq.toArray positions(array.length, numSlices).map { case (start, end) => array.slice(start, end).toSeq }.toSeq } } }
-














 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









