



关系型数据库
关系型数据库是一种基于关系模型(二维表结构)的数据库管理系统,数据以"行-列"的形式存储在表中,表与表之间通过主键(Primary Key)和外键(Foreign Key)建立关联关系。通过预定义的Schema(数据结构)将数据组织为相互关联的表。其本质是结构化数据的规范化管理工具。
NoSQL数据库
简单说,NoSQL(Not Only SQL,"不仅仅是SQL")就是一种不依赖于传统关系型数据库模型的数据库。它不使用SQL作为主要查询语言,也不需要预先定义复杂的表结构。数据结构更加灵活,支持多种数据模型(如键值对、文档、列族和图形等)。你可以把它想象成一个"灵活的收纳盒",而关系型数据库就像一个"固定尺寸的文件柜"。
已有关系型数据库,为啥还有的非关系型数据库
虽然关系型数据库在很多情况下都能很好地满足需求,但在某些特定场景下,NoSQL 数据库具有更好的性能和可扩展性。
可以从以下几个方面,说明在某些特定场景下NoSQL比(MySQL、Oracle)关系型数据库更适合:
1.可扩展性
NoSQL 数据库通常具有更好的可扩展性,可以轻松地在多个服务器之间分布数据。这对于需要处理大量数据和高并发访问的应用(如社交网络、电子商务网站等)非常重要。而关系型数据库在扩展性方面相对较差,尤其是在需要跨多个服务器分布数据时。
2. 灵活的数据模型
NoSQL 数据库通常具有更灵活的数据模型,可以轻松地存储和查询非结构化和半结构化数据(如 JSON、XML 等)。这使得 NoSQL 数据库非常适合处理各种类型的数据,如文本、图像、视频等。而关系型数据库通常需要预先定义表结构,对于非结构化数据的存储和查询相对较困难。
3. 高性能
在某些场景下,NoSQL 数据库可以提供比关系型数据库更高的性能。例如,Redis 等内存数据库可以将数据存储在内存中,从而实现极快的读写速度。而关系型数据库通常需要将数据存储在磁盘上,读写速度相对较慢。
4. 高可用性
NoSQL 数据库通常具有更好的容错性和高可用性。例如:Cassandra 等分布式数据库可以在多个节点之间自动复制数据,从而在某个节点发生故障时仍能保证数据的可用性。而关系型数据库在实现高可用性方面通常需要更多的配置和管理。
5. 低成本
NoSQL 数据库通常具有更低的成本,尤其是在开源社区中。许多 NoSQL 数据库(如 MongoDB、Redis 等)都是开源的,可以免费使用。而关系型数据库(如 Oracle、SQL Server 等)通常需要购买许可证,成本较高。
6. 特定场景的优势
在某些特定场景下,NoSQL 数据库具有明显优势。例如:在处理大量日志数据、实时数据分析、物联网设备数据等场景时,NoSQL 数据库可以提供更好的性能和可扩展性。
查询与操作方式对比

适用场景对比
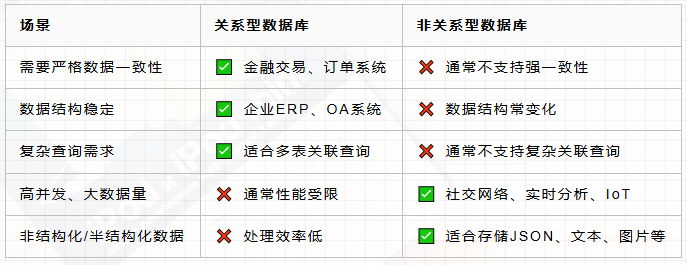
结论
NoSQL的存在并非否定关系型数据库,而是互相补充,主要是:
-
解决关系型数据库无法覆盖的场景(如PB级数据存储)
-
提供更合适的技术选项(如实时推荐系统选
Redis而非MySQL) -
推动数据库技术生态的多元化
在现代的软件架构中,两者常以混合部署方式协同工作:
-
用
PostgreSQL管理核心交易数据 -
用
MongoDB存储用户行为日志 -
用
Elasticsearch实现搜索功能
MySQL的数据存储一定在磁盘吗?
基于磁盘的存储(默认情况)
大多数情况下,MySQL确实将数据存储在磁盘上,这是最常见的存储方式:
-
默认存储引擎:从MySQL 5.5开始,
InnoDB成为默认存储引擎 -
存储方式:数据存储在
.ibd文件(InnoDB独占表空间)或共享表空间文件ibdata1中 -
数据文件位置:通过
show variables like '%datadir%';命令可查看,通常在/usr/local/var/mysql或/var/lib/mysql
基于内存的存储(特殊情况)
MySQL也可以将数据存储在内存中,这通过MEMORY存储引擎实现:
MEMORY存储引擎:允许将数据和索引存储在内存中,提高检索速度和修改效率
主要特点:
-
无磁盘数据文件(仅
.frm文件存储表结构) -
数据在内存中,重启MySQL后数据会丢失
-
适合临时数据、缓存或快速查询场景
-
通过
ENGINE = MEMORY指定
MySQL中如何指定引擎1、创建表时,可以通过ENGINE来指定存储引擎,在create语句最后加上"engine=存储引擎"即可;
CREATE TABLE table_test (
id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY
) ENGINE = InnoDB;2、修改表时,可以使用“alter table 表名 engine=存储引擎;”来指定存储引擎。
ALTER TABLE table_test ENGINE=InnoDB;常见误解澄清
因为MySQL的InnoDB为了提高数据库的操作效率,设计了Buffer Pool(内存缓冲区)用于缓存数据,人们看到"Buffer Pool"(内存缓冲区)就误以为数据存储在内存中。这不是数据存储在内存中,而是数据在磁盘上,部分数据被缓存在内存中以提高性能。误解了"In-Memory Database"的概念(MySQL 本身不提供独立进程级的 In-Memory Database(如 SAP HANA),仅通过 Memory 引擎提供表级内存存储)。
总结
MySQL的数据存储不一定是基于磁盘的。虽然大多数情况下,MySQL使用InnoDB或MyISAM等存储引擎将数据存储在磁盘上(如.ibd或.MYD文件),但它也支持MEMORY存储引擎,允许将数据完全存储在内存中,从而获得极快的查询速度。使用MEMORY存储引擎时,数据仅存在于内存中,重启MySQL服务后数据会丢失,因此它适用于临时数据或缓存场景,而非持久化数据存储。
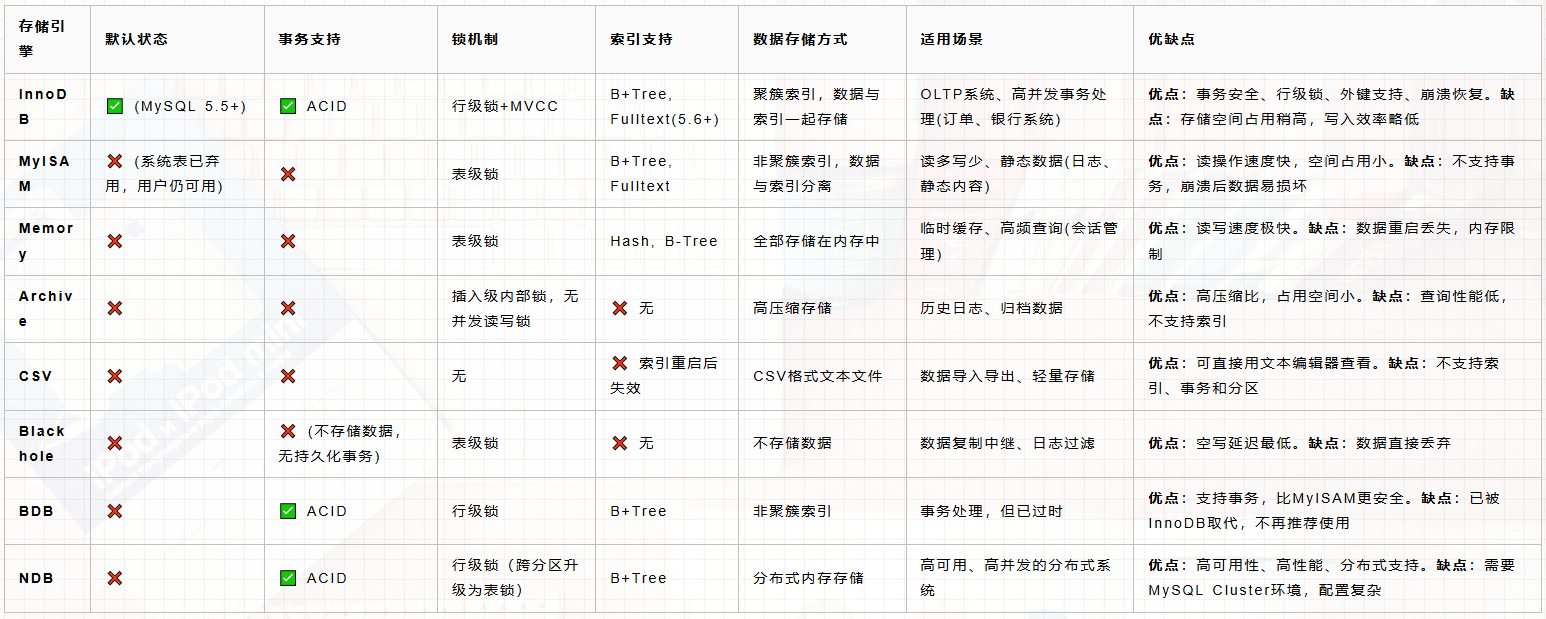
下面是MySQL各存储引擎的对比
文章转载自:纪莫

















 3167
3167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









