







1.什么是过拟合?什么是欠拟合?怎么样去诊断算法是否是过拟合或欠拟合?
过拟合:训练误差很小,验证误差较大。高方差,
欠拟合:训练误差和验证误差都很大。高偏差,
诊断算法:绘制这个模型的学习曲线
2.模型的拟合成本是什么意思?它和模型的准确性有什么关系?
拟合成本:衡量模型与训练样本符合程度的指标
关系:成本函数值越小,模型准确性越高
3.我们有哪些指标来评价一个模型的好坏?
回归模型:
1)SSE 误差平方和
SSE数值大小本身没有意义,随着样本增加,SSE必然增加,也就是说,不同的数据集的情况下,SSE比较没有意义
2)R-square决定系数
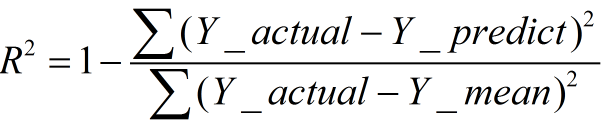
3)
Adjusted R-Square (校正决定系数)
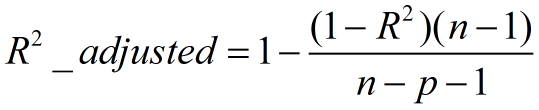
分类模型
1)混淆矩阵(Confusion Matrix)
| 真实情况 | 预测结果 | |
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
查准率(精准率):Precision = TP / (TP+FP);
查全率(召回率):Recall = TP / (TP+FN);
正确率(准确率):Accuracy = (TP+TN) / (TP+FP+TN+FN)
2)PR曲线

3)ROC曲线和AUC

4.为什么需要交叉验证数据集?
用来验证参数
5.什么是学习曲线?为什么要画学习曲线?
学习曲线:以Jtrian(θ)和Jcv(θ)作为纵坐标,画出与训练数据集m的大小关系。
目的:直观的观察到模型的准确性与训练集大小的关系
6.打开ch03.02.ipynb,运行直观示例代码。
 7.参考ch03.02.ipynb,换成随机森林回归算法sklearn.ensemble.RandomForestRegressor来拟合曲线,并画出学习曲线。提示:读者可以阅读scikit-learn文档以获得帮助。不需要深入了解算法原理,由于scikit-learn提供了一致的接口,对大部分有编程经验的读者这个任务不会是太大的障碍。
7.参考ch03.02.ipynb,换成随机森林回归算法sklearn.ensemble.RandomForestRegressor来拟合曲线,并画出学习曲线。提示:读者可以阅读scikit-learn文档以获得帮助。不需要深入了解算法原理,由于scikit-learn提供了一致的接口,对大部分有编程经验的读者这个任务不会是太大的障碍。

8.为什么需要查准率和召回率来评估模型的好坏?查准率和召回率适合那些领域?
有些问题先验概率太低。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









