







背景:
某现场迁移RB库时发现数据泵(expdp)导出某张表加parallel并不能完全生效,导出的dmp文件大小不平均,数据全部集中在某个dmp文件上,如下图所示:

导出命令如下:
nohup expdp rb/*** directory=MIGRATE tables=event_usage_2985 dumpfile=event_usage_2985%U.dump CONTENT=DATA_ONLY PARALLEL=4 logfile=expdp_event_usage_2985.log &
可以由上图看出,虽然加了parallel=4,dmp文件只生成了4个,且数据几乎全部集中在某个dmp文件里,这种不均衡的数据分布不是我们期望的。
问题复现:
1、找一张大表
col owner for a10
col segment_name for a40
set lines 400 pages 9999
select * from (select owner,segment_name,sum(bytes/1024/1024/1024) from dba_segments group by segment_name,owner order by sum(bytes/1024/1024/1024) desc) where rownum<10;

2、按照常规parallel的命令导出
expdp rbc/******** directory=DIR_DP tables=rbc.EVENT_USAGE_C_10570 parallel=8 dumpfile=EVENT_USAGE_C_10570_%U.dmp logfile=EVENT_USAGE_C_10570.log metrics=y
发现导出的dmp文件大小不均匀,且使用parallel 8,只生成3个dmp文件,复现了此问题

问题排查:
1、分区表分析
查看日志发现数据分布不均,怀疑是一个expdp woker进程只负责一个partition的导出,导致dmpfile大小不一样

使用filesize限制每个dumpfile的大小,效果显现:
expdp rbc/******** directory=DIR_DP tables=rbc.EVENT_USAGE_C_10570 parallel=8 filesize=2G dumpfile=EVENT_USAGE_C_2_10570_%U.dmp logfile=EVENT_USAGE_C_2_10570.log metrics=y


但是dmpfile是一个个增长的,而不是并行增长(怀疑是分区数据不均导致)
2、构造非分区表测试
create table rbc.EVENT_USAGE_C_10570_TEST as select * from rbc.EVENT_USAGE_C_10570;
expdp rbc/******** directory=DIR_DP tables=rbc.EVENT_USAGE_C_10570_test parallel=8 dumpfile=EVENT_USAGE_C_10570_test_%U.dmp logfile=EVENT_USAGE_C_10570_test.log metrics=y
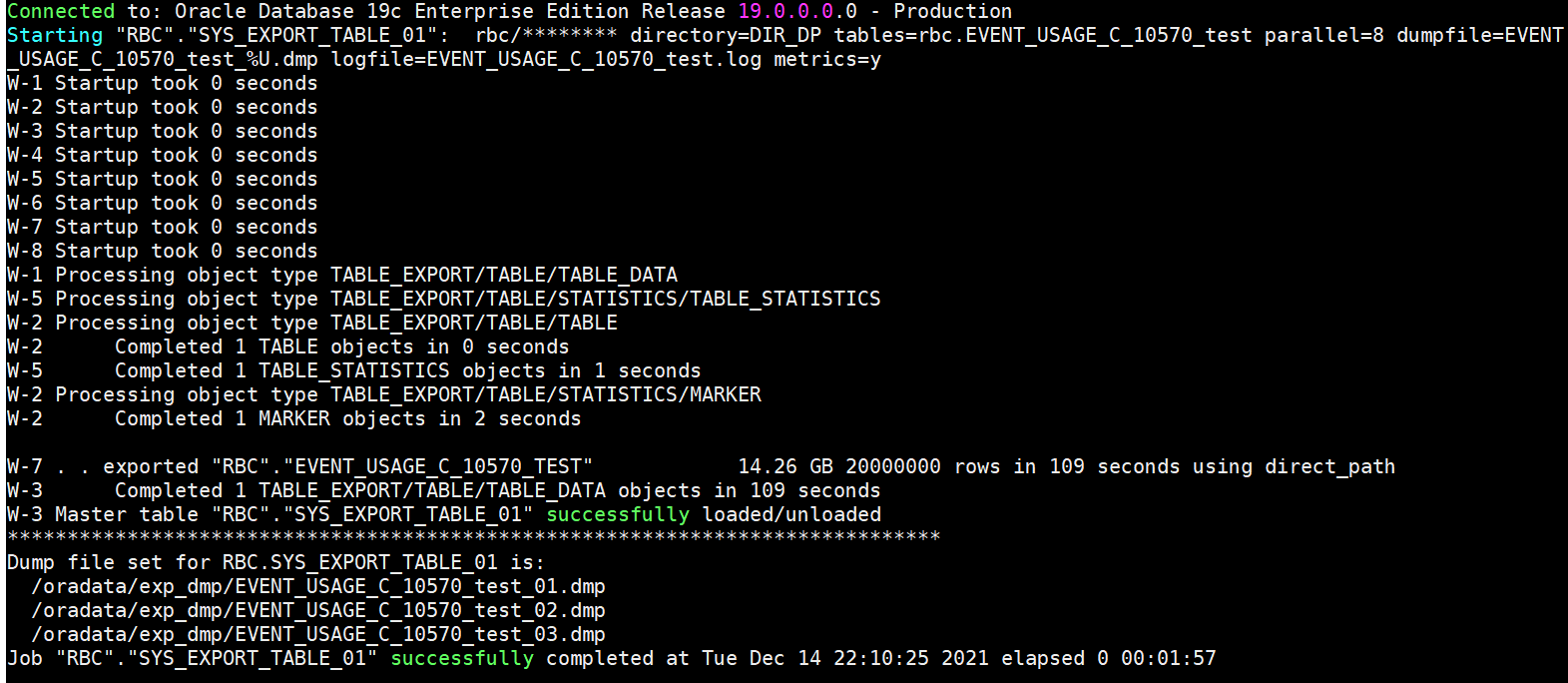
测试发现普通表指定了parallel,也无法均匀产生相应数量的dmpfile,排除了分区分布不均的怀疑

仔细观察此日志,发现真正用户数据导出的worker进程只有W-7,其他worker要么在处理其他(statisctics等),要么没有用到(W-4,W-6等)
怀疑一张表只能由一个worker导出
3、导出整个schema测试
expdp rbc/******** directory=DIR_DP schemas=rbc parallel=8 dumpfile=EVENT_USAGE_C_10570_test_%U.dmp logfile=EVENT_USAGE_C_10570_test.log metrics=y exclude=statistics

根据导出的结果可以看出,以schema导出的dmp文件仍然不均匀,应该是用户下面有两张大表各自落在这两个dmp文件导致

结论
由测试结果可以暂时得出结论,一张表只能由一个worker导出数据,且此worker导出的数据会集中在一个dmpfile。所以导出单表时,只加parallel无法生成对应的dmpfile个数(最多3个)要想生成多个dmpfile,可以加filesize限制一个dmpfile大小,这样会生成多个dmpfile(但是并不是同时生成,而是一个个生成,所以加parallel只能生成多个dmpfile,而不能减少导出时间)
附:
导出过程:

filesize的解释:
filesize限制生成的dmpfile的最大值,建议与parallel共同使用,使用filesize,dumpfile要加%U才行,否则导出的数据超出filesize指定的值,会报错如下:


如果导出的dmpfile很大,大于parallel*filesize的值,dmpfile会继续增加;建议导出前先预估下导出的量,尽量使得parallel*filesize的值小于dmpfile,避免expdp worker进程idle
导出导入时间对比:
| 参数 | parallel=8 | filesize=2G | parallel+filesize | 两个参数都不加 |
| 导出时间 | 1min33s | 1min47s | 1min40s | 1min50s |
| 导入时间 | 5min57s | 5min29s | 6min8s | 5min29s |














 4033
4033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









